Name Indexer and Name Translator
Introduction
Rosette Name Indexer and Rosette Name Translator (RNI-RNT) provides the linguistic infrastructure and Java APIs to perform name matches, name searches, and translations across an expanding collection of languages and scripts.
You can use RNI-RNT to perform the following tasks:
Search name indexes across languages for similar entries for a given name.
Build automated applications to translate names from one language to another.
Build interactive applications to translate names in conformance with a number of transliteration standards.
For information about other Rosette products that can help with processing documents, extracting names, and additional text analytics, contact support@rosette.com.
Overview of name matching
The natural language processing algorithms employed by RNI use machine learning and cutting-edge NLP techniques to perform name matching. The match scores produced are a relative indication of how similar two names are, or a search name is to a name in an index; the higher the score the stronger the match. Customizations are available to tune and configure RNI to fit your business and data.
There are two common usage patterns in name and address matching: pairwise and index.
In pairwise matching, you have two names or addresses that you are comparing directly to one another. This comparison results in a single similarity score that indicates how similar the two names are.
With index matching, you have a single name or address that you are comparing to a list. This can be thought of as a search problem. You have a name and want to search are large list of records to find a match.
Index matching includes pairwise matching. When querying an index RNI performs a two-pass search:
Generate candidates: The first pass is designed to quickly generate a set of candidates for the second pass to consider.
Pairwise match: The query value is compared with each value returned by the first pass and a similarity score is calculated for each pair.
Language support
RNI can match names in any language. For the languages listed in Fully supported text domains for name matching, RNI calculates a match score using a variety of techniques, as described in Understanding name match scores. For names not listed in those tables, RNI provides limited support, as described in Language support parameters.
Note
Prior to release 7.36.0, RNI did not support the limited languages; when presented with names in those languages, an "unsupported language" error would be returned.
To set RNI to behave as it did previously, set allLanguageSupport to false.
Documentation
This guide provides information on installing, running the sample applications included in RNI-RNT, setting up a development environment, and creating applications that use the runtime environment to incorporate RNI-RNT functionality.
The Java API is documented in HTML Javadoc pages generated from the source code, found at api-reference/index.html .
For instructions on using RNI-RNT with RLP, see Installing RLP with RNI.
Getting started
Requirements
Java SDK 11 through 19. RNI-RNT is tested with OpenJDK.
Apache Ant 1.7.1 or later to use the Ant build scripts we provide to build and run the samples.
The compressed SDK package file for your platform.
See Supported Platforms and RNI-RNT Package File Names.
The RNI-RNT documentation set includes the following:
Release Notes with up-to-date information about new features and bug fixes in this release
The RNI-RNT Application Developer's Guide (this document)
Online reference to the Java API
The Rosette license file:
rlp-license.xml.
Important
Unless otherwise specified, all inputs to RNI need to be UTF-8 encoded.
Verify that documents that have been copied from another system maintain UTF-8 encoding and have not been converted to another encoding scheme such as ASCII or UTF-16.
Supported platforms
You must install an SDK package that is appropriate for your platform with respect to operating system and CPU. Since the public API for RNI-RNT is Java, the C++ compiler that appears in the following list is irrelevant.
OS | CPU | Compiler | $BT_BUILD[a] | ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
MAC OS X v10.9+ (Darwin 13) | AMD64 | xcode 5 | amd64-darwin13-xcode5 | ||||||||||||||||||||||||||||||||||||||||||||||
Linux | AMD64 | gcc 4.4 | amd64-glibc217-gcc48 | ||||||||||||||||||||||||||||||||||||||||||||||
Linux | AARCH64 | gcc 7.3 | aarch64-glibc226-gcc73 | ||||||||||||||||||||||||||||||||||||||||||||||
Windows | AMD64 | Visual Studio 2013 | amd64-w64-msvc120 | ||||||||||||||||||||||||||||||||||||||||||||||
Java Only[b] | n/a | n/a | jvm | ||||||||||||||||||||||||||||||||||||||||||||||
[a] [b] The Java-only SDK runs on any OS and CPU with 64-bit Java SDK 11 through 19. | |||||||||||||||||||||||||||||||||||||||||||||||||
The compressed SDK package file names take the form:
rni-rnt-<version>-sdk-$BT_BUILD.<ext>
where <version> is the RNI-RNT version ( x.xx.x.cxx.x is the format), $BT_BUILD is in the table above, and <ext> is .zip for Windows or Java-only, and tar.gz for Unix platforms.
rni-rnt-<version>-sdk-amd64-darwin13-xcode5.tar.gzrni-rnt-<version>-sdk-amd64-glibc217-gcc48.tar.gzrni-rnt-<version>-sdk-aarch64-glibc226-gcc73.tar.gzrni-rnt-<version>-sdk-amd64-w64-msvc120.ziprni-rnt-<version>-sdk-jvm.zip
Note
The version number is embedded in the package file name.
RNI-RNT-<version>-api-reference.zipRNI-RNT-<version>-ReleaseNotes.pdfRNI-RNT-<version>-AppDevGuide.pdf
Installing RNI-RNT
When you obtain RNI-RNT, you should receive the following files:
The SDK package listed above for your platform: e.g.,
rni-rnt-<version>-sdk-amd64-glibc217-gcc48.tar.gzThe Rosette License:
rlp-license.xml.
Expand the SDK into the install directory, which we will call $BT_ROOT, and copy the license to the $BT_ROOT/rlp/rlp/licenses subdirectory.
Once you have installed RNI-RNT, you can install RLP. See instructions for Installing RLP with RNI-RNT .
Note
For Windows users, you must add
\rlp\bin\*
to your PATH environment variable. In this case, you must replace * with the name of the subdirectory which contains the platform-specific binary library files (for example, amd64-w64-msvc120).
Note on logging
RNI uses the Logging Facade for Java (SLF4J) to log RNI activities. See http://www.slf4j.org/.
SFL4J is a facade for various logging APIs. Using SFL4J, the developer or an administrator can determine which one of many popular logging systems to use at runtime.
This is done by including one and only one adapter jar on the classpath, such as slf4j-log4j-1.17.36.jar, for the logging system of your choice, and the jar for that logging system (such as log4j-2.19.0.jar). You also need to include the SLF4J API jar, slf4j-api-1.17.36.jar, on the classpath.
By default, all activity is logged to the console. To log to a file and to control the level of logging, place an adapter jar, a logging library, an SLF4J API jar, and the appropriate properties file (e.g., log4j.properties if you are using log4j) on your classpath.
The adapter, logging, and API jars mentioned above are in samples/java/lib. A copy of log4j.properties, which is used by our samples, is in samples/java/logging. You should adjust the copy of log4j.properties that you place on your classpath to meet your specific runtime logging needs.
libpostal data directory
RNI uses libpostal to parse addresses; libpostal is a C library for parsing/normalizing street addresses around the world using statistical NLP and open data.
RNI packages libpostal data in plugins/rni/bt_root/rlpnc/data/libpostal. The data directory is relatively large (~2G). If you are certain that you won't be utilizing address matching of unfielded addresses, you can safely delete the libpostal data directory without impacting any other RNI functionalities.
RLP with RNI-RNT
If you are using both RLP and RNI-RNT together, first install RNI-RNT. Next, install RLP in the same location. When you are installing RLP there will be some overlap of directories, which is expected. Allow the RLP directories and files to replace the existing directories and files.
Setting up your development environment
When building or running an RNI-RNT application, you must include the following JAR files on your classpath:
btrlpnc.jarbtcommon-api-<apiversion>.jarbtcommon-api-jackson-<jacksonversion>.jarbtcommon-lib-<libversion>.jaricu4j-<icuversion>.jar
If using the seq2seq model for Katakana-English matching, you must also include the following JAR files on your classpath:
btrlpnc-seq2seq.jartensorflow-core-api-<tensorflowversion>-native.jarIf you need GPU support, replace the tensorflow file with the version compiled for your platform. macOS must be at version 10.13 or higher.
jna-<jnaversion>.jar
These files are in $BT_ROOT/rlpnc/lib/jvm.
For information about $BT_ROOT (the Basis root directory) and $BT_BUILD (the platform designator), see Installing RNI-RNT.
To use the Ant scripts described in Building and running the sample applications, make sure you have Ant (1.7.1 or later), the JAVA_HOME environment variable is set to the root of your Java SDK, and the Java SDK bin directory is on your PATH.
Handling the runtime environment
RNI uses data resources stored in the file system in standard locations relative to the Basis root directory ($BT_ROOT). Accordingly, you must follow a few basic rules when you are assembling an application that includes RNI functionality.
Prior to accessing the RNI API, you must set the Basis root directory.
RNI maintains singleton Environment objects for maintaining read-only shared data. Depending on the operations you perform, you may need to explicitly instantiate an Environment object before you perform these operations and close the Environment object when you are done.
Setting the Basis root directory
The API provides two ways of performing this action:
Use
com.basistech.names.internal.Pathnames.setBTRootDirectory (String BT_ROOT).Set the
bt.rootsystem property. You can do this from the command line when you launch the Java virtual machine:java -Dbt.root=
$BT_ROOT...where
$BT_ROOTis the path to the Basis root directory.
You can also set up an overlay directory. This directory must have an identical structure to the normal root directory outside of the rlp/lib and rlp/bin directories. License files will only be considered from BT_ROOT and should not be moved over to the overlay root.
Important
If a location for this overlay directory is specified, either in Java with com.basistech.names.internal.Pathnames.setOverlayRootDirectory or the bt.overlay.root system property, RNI will look in that location for every data/configuration file instead of the root directory. If no location is specified, RNI will use the normal root directory.
Note
Libpostal data (controlled by the libpostalDataDirPath parameter, defaulting to rlpnc/data/libpostal) and word embedding data (rlpnc/data/tvec/filtered-vectors) will only be considered from BT_ROOT and should not be moved over as part of the overlay root
Manipulating the environment
Before you use Rosette Name Translator (RNT), you must instantiate a com.basistech.rnt.RNTEnvironment object. For example:
RNTEnvironment rntEnv = new RNTEnvironment();
The RNTEnvironment uses data files stored in the file system according to the standard RLP release hierarchy. Accordingly, you must set the Basis root directory prior to instantiating RNTEnvironment.
If your RLP license is not found in the appropriate location (rlp/rlp/licenses/rlp-license.xml) under your BT_ROOT directory, RNIConfiguration and RNTEnvironment include a setLicenseXML() method that you can use to provide the license as a string.
When you have finished performing translations, you should close the RNTEnvironment object to free resources. For example:
rntEnv.close();
When you use Rosette Name Indexer, RNI-RNT instantiates an RNTEnvironment object as required. If RNI-RNT instantiates an RNTEnvironment object, it also closes it at the appropriate time.
A Quick look at RNI-RNT: running a sample program
Building and running the sample applications
To build and run the sample applications, you must have the Java SDK (11 or later). To use the Ant build files we provide to build and run the samples, you need Ant (1.7.1 or later) with the JAVA_HOME environment variable set to the root of your Java SDK. For more information, see http://ant.apache.org.
The source files for these applications and the Ant build file for compiling and running them (build.xml) are located in $BT_ROOT/rlpnc/samples/java.
Tip
The Ant scripts and build files require one input property: bt.arch=$BT_BUILD (bt.arch=amd64-glibc217-gcc48, for example). If you set this property in the script (build.xml), you do not need to include it on the command line.
Source File | Description |
|---|---|
| Adds names from a UTF-8 file to an RNI Index. |
| Loads an XML gazetteer into an RNI Index. |
| Submits a series of queries (names) to an index and reports on the results. |
| Queries an index, deletes the names returned from that index, and adds the names to a second index. The deletions and additions are performed in a single distributed transaction with two-phase commit. |
| Determines the similarity of two or more names. |
| Demonstrates the different name matching phenomena that RNI supports. |
| Translates one or more names. |
| Simulates a series of user interactions resulting in the translation of an Arabic name. |
| Integrates RNI with Solr to add and query Solr documents with multiple and multivalued name fields. |
| Submits a series of queries (addresses) to an index and reports on theresults. |
| Demonstrates the different address matching phenomena that RNIsupports. |
Your License
You must copy the license file you obtained from BasisTech to $BT_ROOT/rlp/rlp/licenses. If the license is not in place, you cannot access any RNI-RNT functionality. The license defines the scope of the activities you may perform with RNI-RNT.
Using the Ant build script
Tip
The Ant scripts and build files require one input property: bt.arch=$BT_BUILD (bt.arch=amd64-glibc217-gcc48, for example). If you set this property in the script (build.xml), you do not need to include it on the command line.
Change directory to $BT_ROOT/rlpnc/samples/java and run Ant:
ant -Dbt.arch=$BT_BUILD targetwhere target is one of the Ant build targets in the following table.
| Description | ||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Compiles the samples and places the class files in | ||||||||||||||||||||||||||||||||||||||||||||||||
compile. | Compiles the specified sample. | ||||||||||||||||||||||||||||||||||||||||||||||||
| Compiles (if necessary) and runs the samples with the command-line arguments defined in the Ant build file. Each sample prints a message to the console indicating what it has done, including any file it has created. | ||||||||||||||||||||||||||||||||||||||||||||||||
run. | Runs the specified sample. | ||||||||||||||||||||||||||||||||||||||||||||||||
| Removes the class files and any files created by the samples. | ||||||||||||||||||||||||||||||||||||||||||||||||
clean. | Removes the sample class file(s) and any file created by the sample. | ||||||||||||||||||||||||||||||||||||||||||||||||
| Calls | ||||||||||||||||||||||||||||||||||||||||||||||||
[a] | |||||||||||||||||||||||||||||||||||||||||||||||||
As you create your own applications, you can use the Ant build file as the starting point for establishing your own build procedures.
Matching names
RNI provides a Java API for matching names across the boundaries of writing scripts. For the complete list of the languages and writing scripts that name matching supports, see Supported Text Domains for Rosette Name Indexer and Name Matching.
In the RNI context, name matching means comparing two names, performing linguistic analysis, and returning a score (a double greater than zero and less than or equal to one) that indicates how similar the two names are. A value of 1.0 is returned if and only if the two names are identical (the strings, languages, languages of origin, and entity types match). A score of less than 1.0 is returned for names that potentially match, with different mismatched name variations.
Interpreting RNI scores
Names are complex to match because of the large number of variations that occur within a language and across languages. RNI breaks a name into tokens and compares the matching tokens. RNI can identify variations between matching tokens including, but not limited to, typographical errors, phonetic spelling variations, transliteration differences, initials, and nicknames.
RNI scores range from 0 to 1. The higher the score, the greater the confidence that this a relevant match. A score of 1.0 indicates that the query name string and result name string are identical (including all name properties).
The match score is a relative indication of how similar the match is; it is not an absolute value. When comparing different name matches, the relative matches of the scores are more relevant than the actual score. Similar name matches in different languages may generate different match scores. To understand how RNI calculates the score, see Understanding name match scores.
Scores less than 1.0 for similar names indicate the query name and index name vary with respect to one or more properties (such as language of origin) and/or one or more of the following:
Variation | Example(s) |
|---|---|
Phonetic and/or spelling differences | Nayif Hawatmeh and Nayif Hawatma |
Missing name components | Mohammad Salah and Mohammad Abd El-Hamid Salah |
Rarity of a shared name component | Two English names that contain Ditters are more likely to match than two names that contain Smith |
Initials | John F. Kennedy and John Fitzgerald Kennedy |
Nicknames | Bobby Holguin and Robert Holguin |
"Cousin" or cognate names | Pedro Calzon and Peter Calzon |
Uppercase/Lowercase | Rosa Elena PACHECO and Rosa Elena Pacheco |
Reordered name components | Zedong Mao and Mao Zedong |
Variable Segmentation | Henry Van Dick and Henri VanDick, Robert Smith and Robert JohnSmyth |
Corresponding name fields | For [Katherine][Anne][Cox], the similarity with [Katherine][Ann][Cox] is higher than the similarity with [Katherine Ann][Cox] |
Truncation of name elements | For Sawyer, the similarity with Sawy is higher than the similarity with Sawi. |
Scoring is commutative: the scores for two given names are always the same, regardless of which name is in the index and which name is in the query.
You can configure RNI to customize how it scores different match phenomena.
The score weighting associated with a token may vary depending on the token's characteristics, such as the frequency with which it appears in the language model (the more frequent, the lower the weighting).
Entity types
The entityType field identifies the type of name being matched and to select the algorithms to use for matching. Where supported, stop words and override files are specific to an entity type. Parameters can be set for specific languages and entity types.
Important
The entityType should always be specified to utilize all available methods when indexing and matching names. If you don't specify an entityType, the type PERSON will be used.
Type | Description | Features |
|---|---|---|
PERSON | A human identified by name, nickname, or alias. | Values are tokenized and token pairs are compared. Stop words, overrides, frequency and gender models are supported. |
LOCATION | A city, state, country, region or other location. | Values are tokenized and token pairs are compared. Stop words, overrides, and frequency models are supported. |
ORGANIZATION | A corporation, institution, government agency, or other group of people defined by an established organizational structure. | Values are tokenized and token pairs are compared. Stop words, overrides, frequency models, and embeddings are supported. Real World IDs are supported. |
IDENTIFIER IDENTIFIER:DRIVERS_LICENSE IDENTIFIER:LICENSE_PLATE IDENTIFIER:NATIONAL_ID_NUM | An alphanumeric identifier. | Values are not tokenized. The entire identifier is treated as a string. Scoring is primarily by string edit distance. |
Names with data fields
By using a string array (such as String[] nameData = {"John", "Smith"};), you can create a name with data fields. The maximum number of data fields is 5. We assign no explicit semantics to each field (such as given name or surname), but the order of the fields does matter when comparing two names that have fields. RNI assigns lower scores to matches that cross field boundaries (e.g., the first field in one name matches the second field in another name). The use of fields may enhance accuracy when you are performing queries and matches with PERSON names in languages where standard name ordering is not the norm. By dictating a consistent name ordering, you can avoid penalties for mis-ordered tokens.
For consistency, you may want to adopt a paradigm for name fields, such as {title, given names, surname, suffix}. Include empty fields in the appropriate position for names that do not contain all these elements. If a trailing field is empty, you can leave it out. For example:
{"Mr", "John Miles", "Doe", "Jr"}
{"Queen", "Elizabeth", "", "II"}
{"Mr", "Anthony Charles", "Blair"}
{"Ms", "Rosanne Christine", "Atwood"}
{"", "Martin Luther", "King", "Jr"}
Note
When scoring a potential match between a name with data fields and a name without data fields, RNI treats the name without data fields as if it were a name with one data field.
RNI treats trailing empty fields as if they were not present. For example, {"Rosanne", "Taylor Smith",""} is treated the same as {"Rosanne", "Taylor Smith"}.
Alternatively, you have the option of specifying that there is an unknown value in a field. To specify an unknown name field, replace the field with Name.UNKNOWN_FIELD_MARKER.
Name matching usage model
Identify two names to compare. They may be in different languages (languages of use) and writing scripts.
Use MatchScorer to score the similarity of two Name objects. MatchScorer and Name are in the com.basistech.rni.match package.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/match_2names.java
For the Arabic name نايف أبو شرخ and its IC transliteration Nayif Abu-Sharakh, this comparison returns a score of 0.99.
If you want to compare one name to many names, for improved efficiency you can cache the scorer with the one name (the query name) and used the cached scorer to compare that name to multiple names. As illustrated in the following code snippet, you must prepare each name that you use with the cached scorer.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/match_1name_tomany.java
For a sample Java application that matches two names and matches a query name against multiple reference names, see MatchNamesSample.
Configuring name matching
There are many ways to configure RNI to better fit your use case and data. The two primary mechanisms are by modifying match parameters and editing overrides. You can also train a custom language model.
Tuning match parameters
The default values of the RNI match parameters are tuned to perform well on most queries and datasets. However, every use case uses different data with distinct match requirements. You can modify match parameters to optimize match results for your data and business case.
The typical process for tuning parameters is as follows:
Gather a list of names to index and queries to run against them to use as a set of test data. Ideally the test data set should be big enough to reflect the diversity in your real data with at least 100 queries.
After indexing the data, run the queries using RNI and determine a match score threshold that appears to provide the best results.
Analyze the results to discover cases that RNI failed to score high enough or that RNI incorrectly scored higher than the threshold.
Choose a subset of these name pairs that RNI scored too low or too high that will be used as examples to tune your parameters.
Tune the match parameters to change the match scores of the test set of undesirable results, so that the score is correctly above or below your threshold. For name or address pairs that have to match in a specific way and are very dissimilar (eg. aliases), we recommend you add them as token or full-name overrides.
Run the large set of queries through RNI again to test that the new parameter values still return the desired matches, and not new undesired results.
Parameter configuration files
Individual name tokens are scored by a number of algorithms or rules. These algorithms can be optimized by modifying configuration parameters, thus changing the final similarity score.
The parameter files are contained in two .yaml files located in plugins/rni/bt_root/rlpnc/data/etc. The parameters are defined in parameter_defs.yaml and modified in parameter_profiles.yaml.
parameter_defs.yamllists each match parameter along with the default value and a description. Each parameter may also have a minimum and maximum value, which is the system limit and could cause an error if exceeded. A parameter may also have a recommended minimum (sane_minimum) and recommended maximum (sane_maximum) value, which we advise you do not exceed.parameter_profiles.yamlis where you change parameter values based on the language pairs in the match.
Important
Do not modify the parameter_defs.yaml file. All changes should be made in the parameter_profiles.yaml file.
Do refer to the parameter_defs.yaml file for definitions and usage of all available parameters.
Parameter profiles
The parameters in the parameter_profiles.yaml file are organized by parameter profiles. Each profile contains parameter values for a specific language pair. For example, matching "Susie Johnson" and "Susanne Johnson" will use the eng_eng profile. There is also an any profile which applies to all language pairs.
Parameter profiles have the following characteristics:
Parameter profile names are formed from the language pairs they apply to. The 3 letter language codes are always written in alphabetical order, except for English (
eng), which always comes last. The two languages can be the same. Examples:spa_engara_jpneng_eng
They can include the entity type being matched, such as
eng_eng_PERSON. The parameter values in this profile will only be used when matching English names with English names, where the entity type is specified as PERSON. Any entity type listed in the table can be used.Parameter profiles can inherit mappings from other parameter profiles. The global
anyprofile applies to all languages; all profiles inherit its values.The
anyprofile can include an entity type;any_PERSONapplies to all PERSON matches regardless of language.Specific language profiles inherit values from global profiles. The profile matching person names is named
any_PERSON. The profile for matching Spanish person against English person names is namedspa_eng_PERSON. It inherits parameter values from thespa_engprofile and theany_PERSONprofile. Theany_PERSONprofile will not override parameter values from more specific profiles, such as thespa_engprofile.
Important
Global changes are made with the any profile.
Any changes to address parameters should go under the any profile, and will affect all fields for all addresses.
Any changes to date parameters must go under the any profile.
Parameter universe
A parameter universe is a named profile containing a set of RNI parameter profiles with values. Each universe has a name and can contain multiple parameter profiles, including the global any profile. A parameter universe profile can also include the entity type being matched, just like regular parameter profiles. Examples:
For example, the MyParameterUniverse universe may include the following parameter profiles:
"name": "MyParameterUniverse/any"applies to all language pairs."name": "MyParameterUniverse/spa_eng"applies to English - Spanish name pairs."name": "MyParameterUniverse/spa_eng_PERSON"applies to all PERSON English - Spanish name pairs.
Each parameter in the profile must match the name of a parameter declared in the parameters_defs.yaml file, along with a value. Parameter universes are added to the parameter_profiles.yaml file.
A parameter universe can also be defined dynamically . We recommend that you use dynamic parameter universes for testing and tuning only. For production use, add all parameter universes to the parameter_profiles.yaml file.
Tip
You can define multiple named parameter profiles.
Define the parameter universe in the parameter_profiles.yaml file. Example:
parameterUniverseOne/spa_eng_PERSON:
reorderPenalty: 0.4
HMMUsageThreshold: 0.8
stringDistanceThreshold: 0.1
useEditDistanceTokenScorer: true
parameterUniverseOne/eng_eng:
reorderPenalty: 0.6
Modifying name parameters
To start tuning the parameters, run the RNI pairwise match on the test set and look at the match reasons in the response. These match reasons will serve as a guide for which parameters to tune, which are defined in parameter_defs.yaml. For additional support on tuning the parameters, contact support@rosette.com.
Once you define a profile and set a parameter value, rerun the RNI pairwise match, scoring the match with the edited parameter_profiles.yaml file.
Selected name parameters
Given the large number of configurable name match parameters in RNI, you should start by looking at the impact of modifying a small number of parameters. The complete definition of all available parameters is found in the parameter_defs.yaml file.
The following examples describe the impact of parameter changes in more detail.
conflictScoreLet’s look at the two names: ‘John Mike Smith’ and ‘John Joe Smith’. ‘John’ from the first and second name will be matched as well the token ‘Smith’ from each name. This leaves unmatched tokens ‘Mike’ and ‘Joe’. These two tokens are in direct conflict with each other and users can determine how it is scored. A value closer to 1.0 will treat ‘Mike’ and ‘Joe’ as equal. A value closer to 0.0 will have the opposite effect. This parameter is important when you decide names that have tokens that are dissimilar should have lower final scores. Or you may decide that if two of the tokens are the same, the third token (middle name?) is not as important.
initialsScore)Consider the following two names: 'John Mike Smith' and 'John M Smith'. 'Mike' and 'M' trigger an initial match. You can control how this gets scored. A value closer to 1.0 will treat ‘Mike’ and ‘M’ as equal and increase the overall match score. A value closer to 0.0 will have the opposite effect. This parameter is important when you know there is a lot of initialism in your data sets.
deletionScore)Consider the following two names: ‘John Mike Smith’ and ‘John Smith’. The name token ‘Mike’ is left unpaired with a token from the second name. In this example a value closer to 1.0 will not penalize the missing token. A value closer to 0.0 will have the opposite effect. This parameter is important when you have a lot of variation of token length in your name set.
reorderPenalty)This parameter is applied when tokens match but are in different positions in the two names. Consider the following two names: ‘John Mike Smith’, and ‘John Smith Mike’. This parameter will control the extent to which the token ordering ( ‘Mike Smith’ vs. ‘Smith Mike’) decreases the final match score. A value closer to 1.0 will penalize the final score, driving it lower. A value closer to 0.0 will not penalize the order. This parameter is important when the order of tokens in the name is known. If you know that all your name data stores last name in the last token position, you may want to penalize token reordering more by increasing the penalty. If your data is not well-structured, with some last names first but not all, you may want to lower the penalty.
boostWeightAtRightEnd, boostWeightAtLeftEnd, boostWeightAtBothEndsboost)These parameters boost the weights of tokens in the first and/or last position of a name. These parameters are useful when dealing with English names, and you are confident of the placement of the surname. Consider the following two names: “John Mike Smith’ and ‘John Jay M Smith’. By boosting both ends you effectively give more weight to the ‘John’ and ‘Smith’ tokens. This parameter is important when you have several tokens in a name and are confident that the first and last token are the more important tokens.
The parameters boostWeightAtRightEnd and boostWeightAtLeftEnd should not be used together.
Language support parameters
RNI currently has two levels of language support: complete and limited. Complete support uses a comprehensive set of algorithms to calculate match scores. Fully supported text domains for name matching lists the languages and scripts with complete support. For all other languages, RNI has limited support.
Note
Prior to release 7.36.0, RNI did not support the limited languages; when presented with names in those languages, an "unsupported language" error would be returned.
To set RNI to behave as it did previously, set allLanguageSupport to false.
Limited support uses two match score computations:
Exact matches return a score of 1. This is the same for all languages.
A score is calculated based on string edit distance.
Two parameters control the level of language support.
Parameter | Description | Default |
|---|---|---|
| When set to |
|
| When set to |
|
Neural model for matching
When matching Japanese names in Katakana to English names, you can replace the HMM with a neural model. This model should improve accuracy, but will have an impact on performance.
To enable the neural model, set enableSeq2SeqTokenScorer to true in the jpn_eng profile in the parameter_profiles.yaml file. This applies to Japanese names in Katakana only. Japanese names in other scripts will still use the HMM.
To use the neural model:
Extract the appropriate library files from the platform-specific tensorflow JAR provided in the
rni-es-<version>-seq2seq-libraries.zipbundle.Elasticsearch must be started with an additional Java property and point to the directory containing the extracted libraries:
ES_JAVA_OPTS="-Dorg.bytedeco.javacpp.cacheLibraries=false -Djava.library.path=<path-to-extracted-libraries>"
Note
The neural model is currently only available on MacOS and Linux platforms in RNI-ES versions 7.10.2.x and all plugins including RNI-RNT 7.38.1.67.0 or later.
Matching Korean names
If your data includes a lot of Korean names written in Han script mixed in with Chinese and/or Japanese names, you may want to enable Korean readings. This is only used when the language (languageOfUse) of the document is not specified for each request. The following steps may increase accuracy for Korean names, at the cost of decreased throughput.
To enable Korean readings of names in Han script you need to edit the parameter files as follows:
Edit the
zho_engprofile in theinternal_param_profiles.yamlfile and removekorfrom the list ofignoreTranslationOriginsparameter.Edit the
zho_engprofile in theparameter_profiles.yamlfile to increase thealternativePairsToCheckparameter by 1 to compensate for the additional reading.
Matching names with Han characters
We've added experimental support to leverage mechanisms within the unicode data to improve matching of Han characters.
The four-corner system is a method for encoding Chinese characters using four numerical digits per characters. The digits encode the shapes found in the corners of the symbol, from the top-left to the bottom-right. While this does not uniquely identify a Chinese character, it does limit the list of possibilities.
The parameter haniFourCornerCodeMismatchPenalty applies a penalty if the names have different four corner codes. By default, haniFourCornerCodeMismatchPenalty is set to 0, which turns it off. Experiments have shown positive accuracy improvements when setting the value of the parameter to 1.
To enable the feature, add the following line to your parameter_profiles.yaml file:
zho_zho_PERSON: haniFourCornerCodeMismatchPenalty: 1
Note
This is an experimental feature. As with any experimental feature, we highly recommend experimenting in your environment with your data.
Matching Turkish and Vietnamese names
Vietnamese and Turkish have their own detectors which must be enabled. If your data includes Turkish and/or Vietnamese names, then you must enable the respective detector.
Edit the
parameter_profiles.yamlfile.To enable Turkish detection, add:
detectableLanguagesRuleBased: [tur]
To enable Vietnamese detection, add:
detectableLanguagesRuleBased: [vie]
Restart the system.
Evaluating parameter configuration
To evaluate the newly tuned parameter values, query a large dataset of names or addresses that does not include your test set. For an exact evaluation, query an annotated dataset that includes the correct answers for a number of queries. For a general evaluation, measure the number of pair matches that have scores above your threshold, compared to before tuning the parameter values. If there were too many matches before, now there should be fewer matches. If there were too few matches before, there should be more now. If the number of matches increases or decreases dramatically, then there is a higher chance of missing correct matches below the threshold or including incorrect matches above the threshold.
If you find new pair matches that you want to score above or below your threshold, collect them into a test set to retune the parameters. Then evaluate the parameters again using a large dataset to review results. It is important to frequently evaluate new parameter settings on separate test data to ensure the parameters continue to return correct results.
Configuring name overrides
RNI includes override files (UTF-8 encoded) to improve name matching. There are different types of override files:
Stop patterns and stop word prefixes designate name elements to strip during indexing and queries, and before running any matching algorithms.
Name pair matches specify scores to be assigned for specified full-name pairs.
Token pair overrides specify name token pairs that match along with a match score.
Token normalization files specify the normalized form for tokens and variants to normalize to that form.
Low weight tokens specify parts of names (such as suffixes) that don't contribute much to name matching accuracy.
The name matching override files are in the plugins/rni/bt_root/rlpnc/data/rnm/ref/override directory.
You can modify these files and add additional files in the same subdirectory to extend coverage to additional supported languages. You can also create files that only apply to a specified entity type, such as PERSON.
Stop patterns and stop word prefixes
Before running any matching algorithms, the names are transformed into tokens that can be compared. RNI uses stop patterns and stop word prefixes to remove patterns, including titles such as Mr., Senator, or General, that you do not want to include in name matching. Both stop patterns and stop word prefixes are used to strip matching name elements during indexing and querying. Stop words are string literals and are processed much more quickly than stop patterns, which are regular expressions. You should use stop words for the most efficient removal of prefixes, such as titles. Stop words are language-dependent.
For each name, RNI performs the following steps in order:
Character-level normalization, stripping punctuation (except for periods, commas, and hyphens). White space is reduced to single spaces and all characters are lower-cased. Diacritical marks are removed.
Stop patterns are applied.
Stop words are applied.
RNI cycles its way through the stop patterns then the stop words, each cycle removing the patterns and words that strip nothing, until the list of stop patterns and stop words is empty.
Stop Pattern
A stop pattern is a regular expression that excludes matching name elements during indexing and queries. You can use any regular expression supported by the Java java.util.regex.Pattern; see the Javadoc for detailed documentation.
Stop patterns for a given language are specified in a UTF-8 file with the ISO 639-3 three-letter language code in the filename:
stopregexes_LANG[_TYPE].txt
where LANG is a three-letter language code.
Each row in the file, except for rows that begin with #[8] is a regular expression. Leading and trailing whitespace is removed from regex lines, so use \s at the beginning and end as needed.
Tip
Include _TYPE, where TYPE designates an entity type, such as PERSON if you want the override to apply only if the name, matching names, or matching tokens have been assigned this entity type. If the filename does not include _TYPE, it will be applied to all names, regardless of the entity type.
Name elements matching any of these regular expressions are removed. Longer stop patterns are applied before shorter stop patterns, so the presence of a shorter stop pattern does not prevent the stripping of a longer pattern that includes the shorter pattern. For example, the brigadier[-]general stop pattern is applied first, but general is also a stop pattern and will be applied as well.
RNI includes files with stop patterns for names in English (generic and ORGANIZATION), Japanese (PERSON), Spanish (generic), and Chinese (PERSON). These files are in plugins/rni/bt_root /rlpnc/data/rnm/ref/override. The generic (non-entity-specific) English file is stopregexes_eng.txt. For example, the entries
^fnu\b \blnu$
indicate that the common indicators for first-name-unknown at the start of a name and last-name-unknown at the end of a name, are to be removed.
You can also specify which field the regex is to be applied to when processing a fielded name. Simply add Tabn, where n is the field number. To search multiple fields, include an entry for each field, as illustrated below. When processing a name without fields, the field parameter is ignored. For example,
\blnu$ 2 \blnu$ 3
indicates that the regex is to be applied to fields 2 and 3 in fielded names.
You can modify the contents of this file. To add stop patterns for a different language, create an additional UTF-8 file in the same subdirectory with the three-letter language code in the filename. For example, stopregexes_ara.txt would include regular expressions with Arabic text; stopregexes_eng_PERSON.txt would include regular expression to remove elements from PERSON names in English text.
Use of complex patterns may increase processing time. When possible, use stop word prefixes.
Stop Word Prefixes
A stop word prefix is a string literal that strips the matching prefix from name elements during indexing and querying.
Stop word prefixes for a given language are specified in a UTF-8 file with the ISO 639-3 three-letter language code in the filename:
stopprefixes_LANG[_TYPE].txt
where LANG is a three-letter language code. Each row in the file, except for rows that begin with #, is a string literal. Prefixes matching any of these string literals are removed.
Like stop patterns, longer stop word prefixes take precedence over shorter prefixes contained within the longer stop word. For example, the lieutenant colonel stop word prefix is applied where applicable when colonel is also a stop word prefix.
RNI includes files with generic stop word prefixes for names in Arabic, English, Greek, Hebrew, Hungarian, Khmer, Spanish, Thai, Turkish, and Vietnamese. These files are in plugins/rni/bt_root /rlpnc/data/rnm/ref/override. You can modify the contents of these files. To add stop word prefixes for another language, create a UTF-8 file in the same directory with the three-letter language code in the filename. For example, stopprefixes_rus.txt would include stop word prefixes for use with Russian text.
Overriding name pair matches
You can create UTF-8 text files that specify the scores to be assigned for specified full-name pairs. The filename uses the ISO 639-3 three-letter language codes to designate the language of each full name in each of the full-name pairs:
fullnames_LANG1_LANG2[_TYPE].txt
where LANG1 is the three-letter language code for the first name and LANG2 is the three letter language code for the second name.
Tip
Include _TYPE, where TYPE designates an entity type, such as PERSON if you want the override to apply only if the name (for stop patterns), matching names, or matching tokens have been assigned this entity type. If the filename does not include _TYPE, it will be applied to all names, regardless of the entity type.
Each row in the file, except for rows that begin with #, is a tab-delimited full-name pair and score:
name1 Tab name2 Tab score
The scores must be between 0 and 1.0, where 0 indicates no match, and 1.0 indicates a perfect match.
Tip
Since the minimum score for names returned by RNI queries must be greater than 0, an RNI query will not return the name if the override score is 0. Name match operations, on the other hand, will return an override score of 0.
The installation includes a sample file with sample entries commented out: plugins/rni/bt_root/rlpnc/data/rnm/ref/override/fullnames_eng_eng.txt. Any non-commented-out entries in this file assign scores to English queries applied to English names in an RNI index. For example,
John Doe Joe Bloggs 1.0
indicates that the query name John Doe matches the index name Joe Bloggs (both used in different regions to indicate 'person unknown') with a score of 1.0.
These match patterns are commutative. The previous entry also specifies a match score of 1.0 if the query name is Joe Bloggs and the index includes a document with an rni_name field containing John Doe.
You can add entries for English to English name matches to fullnames_eng_eng.txt, and create additional override files, using the filename to specify the languages. For example the following entries could appear in fullnames_jpn_eng.txt:
外山恒 Toyama Koichi 1.0 ヒラリークリントン Hillary Clinton 1.0
Overriding token pair matches
You can create text files that specify token (name-element) pairs that match. Token pair overrides are supported[9] for English-English, Japanese-English, Chinese-English, Russian-English, Spanish-English, Japanese-Japanese, Russian-Russian, English-Korean, Korean-Korean, Spanish-Spanish, Greek-English and Hungarian-English token pairs. Such pairs may include proper name and nickname, such as Peter and Pete, and cognate names such as Peter and Pedro. When RNI evaluates two names, each of which contains an element from the pair, it enhances the value of the resulting name match score. For example, if Abigail and Abby constitute a token pair, then the match score for Abigail Harris and Abby Harris will be higher than it would be if the token pair had not been specified.
The token pairs may be within a language or cross-lingual, as indicated by the file name:
tokens_LANG1_LANG2_[TYPE].txtwhere LANG1 is the three-letter language code for the first token in each pair and LANG2 is the three-letter language code for the second token in each pair. Each entry in the file, except for rows that begin with #, is a tab-delimited token pair and may include a raw score between 0.0 and 1.0 or an indicator that at least one of the tokens is a nickname or that the tokens are cognates:
Token1 Tab Token2 Tab [[0.0-1.0]|NICKNAME|COGNATE|VARIANT]
A token pair override score (raw score or indicator) serves as a minimum score, but you can write "/force" after a token score to force it to be exactly that value:
Token1 Tab Token2 Tab [([0.0-1.0]|NICKNAME|COGNATE|VARIANT)/force]
If you would like to prevent a token pair from matching, you can use the SUPPRESS indicator as an alias for "0.0/force". If you do not include NICKNAME, COGNATE, VARIANT, or SUPPRESS, RNI assumes NICKNAME.
RNI includes plugins/rni/bt_root/rlpnc/data/rnm/ref/override/tokens_eng_eng.txt, which contains a list of English/English token pairs. For example:
Peter Pete NICKNAME Peter Pedro COGNATE
This directory also contains Chinese to English token overrides for LOCATION and ORGANIZATION: tokens_zho_eng_LOCATION.txt, tokens_zho_eng_ORGANIZATION.txt.
When you create an additional file in the same location, use the ISO 639-3 three-letter language name in the filename to identify the language of each name element in the pair. For example tokens_eng_eng.txt indicates that the contents match English names to English names; tokens_eng_eng_ORGANIZATION.txt indicates that the contents match English ORGANIZATION names to English ORGANIZATION names. The SDK includes a sample file for matching English/English tokens in LOCATION entities: tokens_eng_eng_LOCATION.txt.
We recommend that you enter the language names in alphabetical order in the filename and token pairs. Keep in mind that the order has no influence on the resulting score, since the scoring is commutative.
Multiple sets of token overrides
There may be situations in which you want to define multiple sets of token overrides for an index. This can be accomplished by combining override file names with the overrideSelector parameter.
The value of
overrideSelectoris an alphanumeric string, and it controls which set of overrides will be considered during querying and matching. The value is case-insensitive. By default, it will read overrides for the "default" selector.The value of
overrideSelectorcan be appended to the name of the override text file containing the token pairs, preceded by a dash (-). For example, a file for person name overrides in English - English matching using theoverrideSelectorofOverrideGroup1would be named:tokens_eng_eng_PERSON-OverrideGroup1.txt
If no valid selector name is found in the override text file filename, overrides for that file will be applied to the "default" selector.
Note
Overrides that are associated with a specific selector are not additive to the base overrides. If a custom overrideSelector value is specified, RNI will only consider overrides in that specific selector. As with the base overrides, for a given selector, RNI will consider non-entity-type overrides for that selector if no entity-type-specific override pair is found for that selector.
Normalizing token variants
You can create text files that specify the normalized form for tokens (name elements) and variants to normalize to that form. The file name indicates the language and optionally the entity type for the tokens to be normalized:
equivalenceclasses_LANG_[TYPE].txtFor example, equivalenceclasses_jpn.txt would contain entries for normalizing Japanese token variants for any entity type to a normalized form.
Each entry in the file contains a normalized form followed by one or more variant forms. The syntax is as follows:
[normal_form1] variant1_1 variant1_2 variant1_3 [normal_form2] variant2_1 variant2_2 variant2_3 ...
RNI includes plugins/rni/bt_root/rlpnc/data/rnm/ref/override/equivalenceclasses_eng_PERSON.txt, which contains a list of variant renderings to normalize to muhammad:
[muhammad] mohammed mahamed mohamed mohamad mohammad muhammed muhamed muhammet muhamet md mohd muhd
You can add lists of variants to this file, including the normalized form in square brackets to start each list.
Unimportant tokens
You can edit the list of tokens that are given low influence in RNI. These low weight tokens are parts of a name (such as suffixes) that don't contribute much to the name matching accuracy.
The file name is lowWeightTokens_LANG.txt.
For example, plugins/rni/bt_root/rlpnc/data/rnm/ref/lowWeightTokens_eng.txt contains entries for tokens in English that you may want to put less emphasis on: "jr", "sr", "ii", "iii", "iv", "de".
Matching organizations with real world IDs
Organizations and companies often have nicknames which are very different from the company's official name. For example, International Business Machines, or IBM, is known by the nickname Big Blue. As there is no phonetic similarity between the two names, a match query between those two organization names would result in a low score. A real world identifier associates companies, along with their associated nicknames and permutations, with an identifier. When enabled, a search between two company names will include a comparison between the real world identifiers for the two names, thus matching dissimilar names for the same corporate entity.
RNI contains real world identifiers for corporations, which pair an entity id with nicknames and common permutations of the corporation name. Name matching within a language lists the languages with provided real-world ID dictionaries. Customers can also generate their own real-world ID dictionaries to supplement the provided dictionaries.
Parameter | Description | Default |
|---|---|---|
| Enables real world iIDs, indexes the real-world ids as corporation names are added to the index. Must reindex if you enable it after indexing. |
|
| Enables querying with real world IDs; set by language pair. |
|
realWorldIdScore | Sets the match score when two names match due to matching real world IDs. Set by language pair. | 0.98 |
nameRealWorldQueryBoost | Boosts the value of the real world ID results from the first pass. Increases the likelihood of real world ID matches being returned from the first pass. Set by language pair. | 35 |
Building a real world ID file
Many companies have their own file of organizations with their different names. To improve matching between organization names, you can supplement the real world IDs provided in RNI and build your own file of real world IDs. The provided file will build a binary file in the specified output directory named <LANG>_ORGANIZATION_ids.bin where <LANG> is the three-letter language code of the file.
The input file is a tab separated file (.tsv). Each line contains an organization name and a corresponding alphanumeric ID. The file can only contain a single language and script. You must create a separate file for each language.
IBM WE1X92 Big Blue WE1X92 International Business Machines WE1X92
Unzip the file realWorldIDBuilder.zip found in the plugins/rni/bt_root directory and run the build command. Instructions on how to run the program are in the README.md file in the zip file.
Omit real world IDs
You may want to use real world ID matching even if there are some entities which you do not want to match via real world IDs. You can omit specific organizations and QIDs (Wikidata's identifier for entities) from matching by creating an omit file listing the organization names and QIDs you would like to omit.
The omit file is a tab separated file (.tsv) named <LANG>_ORGANIZATION_ids.tsv where <LANG> is the three-letter language code of the file. Each omit file can only contain names in one language and separate files must be made for each language. There are three types of lines that can appear in an omit file, which have different effects on omission: pairs, lone names, and lone QIDs.
Pair: A name and a QID on the same line. The QID will no longer be used for matching against the name. The same name can be associated with multiple QIDs to omit by placing each pair on its own line.
Lone name: A name followed by an asterisk in the QID column. The name will not be used at all for RWID matching.
Lone QID: A QID is preceded by an asterisk in the name column. No names in the specified language will be able to match against each other using this QID.
Example:
IBM Q37156 Nintendo * * Q45700
To enable an omit file in RNI:
Place the omit file in the
BT_ROOTdirectory.Open
omit_ids.datafiles, which is in theplugins/rni/bt_root/rlpnc/data/real_world_ids/ref/omit_idsdirectory by default.Add a new entry for your omit file following the format
<LANG>_ORGANIZATION tab * tab <file path>, where LANG is the three-letter language code of the file. File paths must be relative to BT_ROOT, meaning absolute paths will not work. For example:ara_ORGANIZATION * rlpnc/data/real_world_ids/ref/omit_ids/ara_ORGANIZATION_ids.tsv
Save
omit_ids.datafiles.
Custom language model training
You can train a language model on your own name data. RNI uses language models in which common names score differently than rare names. For example, "John Jingleheimer" should match "Jingleheimer" better than "John", because Jingleheimer is a rarer name than John. RNI already comes with language models for many supported languages, but you might find it best to train a new language model so that it reflects the statistics of your data. Please note that a large amount of full names are required to train an effective language model.
Installation
Unpack frequencyModelTrainer.zip to any desired location. Ensure that the JAVA_HOME environment variable is set and points to a Java version of 11 or higher.
Simple usage example
bin/buildLM.sh -root rni-rnt -in eng_PER_LM.tsv -out rni-rnt/data/rnm/ref/user_models/eng_PERSON_unigram.bin -lang eng -script Latn
See README.txt in frequencyModelTrainer.zip for more details, including the full description of arguments.
Indexing and querying names
The Rosette Name Indexer (RNI) enables high-speed, scalable, cross-language, and cross-script searches for names.
RNI uses the Apache Lucene full-text search engine to store names with their search keys and a key index. RNI updates and queries with Lucene are transactional.
When you search for a name, RNI generates a search key for each component of the name, locates all the names indexed by those search keys, and uses linguistic matching algorithms to filter that set of names down to the most similar names.
For a list of the languages and writing scripts that RNI supports, see Fully supported text domains for name matching.
RNI provides a Java API that you can use to embed it in your applications. The RNI classes are in com.basistech.rni.index. Unqualified class names that appear in this section are in com.basistech.rni.index.
For detailed information about the API, see the Java API Reference shipped with RNI.
Note
If you have not already done so, you must set the Basis root directory.
Constructing a name index
A name index is an indexed list of names. The list includes a collection of Name objects and associated keys.
The Name object includes the name, language, [10] script, (script and language will be inferred if not included in the name definition) and may include entity type (such as person or place), language of origin, and additional information (with place names, for example, you may want to store the geocoordinates).
Tip
You can also create an index in memory that is never stored on disk.
To create an indexed list of names on disk, you must specify a pathname for the data store, and you must use a IndexStoreDataModelFlags object (the default is fine).
Example:
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/create_index.java
Once the index is created, use NameBuilder to create Name objects and add them to the index. NameBuilder provides a fluent interface that supports method chaining. The following fragment illustrates the syntax for creating and adding a name to the index.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/add_name.java
When you are finished adding names, close the name index, as in the preceding fragment.
Note
NameBuilder also includes static methods that you can use for determining the language and script for a name prior to creating the Name object: guessLanguage(String nameData) and guessScript(String nameData).
You can use hintLanguage(com.basistech.util.LanguageCode hintLanguage) to suggest the language when you create a Name. The NameBuilder uses the suggestion if it is compatible with the script, otherwise it uses its own language guess.
When you are adding a large number of names to an index, you can use an INameIndexSession object to batch these additions into a single transaction. A single transaction is faster than adding each name in a separate transaction. For information, see RNI Sessions and Transactions, and for a sample application that adds multiple names in a single transaction, see AddNamesSample.
Querying a name index
Once you have an index created, you can use queries to search the index for similar names.
Opening a name index
The primary role of a name index is to perform queries. You can also perform updates (insertions and deletions).
StandardNameIndex provides a static method for opening a name index.
INameIndex index = StandardNameIndex.open(String indexPathname);
indexPathname is the path to the directory that contains the name index.
To optimize the index for more efficient queries, call
index.optimize();
When you are done using the name index, you must close it:
index.close();
Defining a name search query
A query includes a Name object and may also include settings to constrain the query. For example, the query can specify the entity type, language, and/or script of the names that it returns. For the details, see the Javadoc for com.basistech.rni.index.IndexStoreDataModelFlags.
You can also define a query to return all the names associated with a specified entity.
Set up a NameIndexQuery object. For example:
// Define a query.
NameIndexQuery defineQuery(Name queryName)
throws NameIndexException, NameIndexStoreException, RNTException {
NameIndexQuery query = new NameIndexQuery(queryName);
query.setNameDataMinimumMatchScore(.30);
return query;
}Running the query and accessing the query results
INameIndex includes a query method that takes as its parameter the defined NameIndexQuery.
The query returns a NameIndexQueryResult iterator. Each NameIndexQueryResult object provides a Name object and a similarity score. As the following fragment illustrates, you can obtain and process each name and its score. The higher the score (greater than 0 and less than or equal to 1), the greater the confidence that this is a relevant match. A score of 1.0 indicates that the query name string and result name string are identical. The types of variations matched by RNI are described in Name Variations. Scoring is commutative: the scores for two given names are always the same, regardless of which name is in the index and which name is in the query.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/query_index.java
SpanMatches. Each query result may contain information about spans (one or more tokens) in the query name that match or do not match spans in each result name. The NameIndexQueryResult provides a MatchResult object, which in turn provides match type and a list of SpanMatch objects. For more information, see the Javadoc for com.basistech.rni.match.SpanMatch and com.basistech.rni.match.Span. The Javadoc for MatchResult#getSpanMatches() provides information about the scope and limitations on what is returned for names in various text domains.
Cleanup
When you are done running queries, close the index:
index.close();
Sample
For a sample Java application that defines a query, runs the query, and reports the results, see IndexQuerySample.
Retrieving groups of names
You may want to retrieve a group of names that share some common characteristic other than name similarity. Perhaps you even want to retrieve all the names in an RNI index.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/name_groups.java
The query returns all the names for which the Extra field contains the token used in the query.
Optimizing query performance
By adjusting NameIndexQuery parameters, you can optimize queries for your use case.
Tradeoffs between accuracy and speed
RNI passes a subset of the highest scoring names from the first-pass high-recall search to the second-pass high-precision filter. The namesToCheckAllowance and maximumNamesToCheck parameters can be adjusted to control how many names are included in that subset.
- maximumNamesToCheck
The
maximumNamesToCheckparameter sets a hard limit on the number of names passed to the high-precision filter for each query. Use it to control the maximum query latency. The appropriate value is largely determined by the size of your index and should increase as your index grows.- namesToCheckAllowance
The
namesToCheckAllowanceparameter is a value between 0.0 and 1.0 used at query time to dynamically calculate the most efficient number of names to pass to the high-precision filter based on the commonality of the query name in the index. When set to 1.0, the value ofmaximumNamesToCheckis used for every query. After determining a good value formaximumNamesToCheck, adjust this parameter to fine-tune the performance.
In general, for greater speed and less accuracy (particularly recall), decrease the value of these parameters using:
setNamesToCheckAllowance(double namesToCheckAllowance)setMaximumNamesToCheck(int maxNamesToCheck)
For greater recall and less speed, increase those settings.
To pass all names found by the high-recall search to the high-precision filter, set:
namesToCheckAllowanceto 1.0maximumNamesToChecktoNameIndexQuery.UNLIMITED_RESULTS.
Optimizing for Duplicate Names. If your index contains duplicate names, you should use setMaximumNamesToConsider(int maxNamesToConsider) to set the maximum number of names to consider to a value higher than the maximum number of names to check. RNI returns the maximum names to consider in the first-pass high-recall search and sends the maximum names to check to the second-pass high-precision filter. If there are any duplicates in the names returned by the first pass, the duplicates are not passed to the second-pass. In other words, the score assigned by the second pass to the first instance of a given name is assigned to its duplicates without spending time sending them through the second pass. For optimal behavior, the ratio of maximumNamesToConsider to maximumNamesToCheck should be approximately the same as the average number of times that a name is repeated in the RNI index. So, for example, if each name is entered twice (on average), maximumNamesToConsider should be twice as big as maximumNamesToCheck. If your index does not include duplicates, you can use IndexStoreDataModelFlags to set optimizeDuplicateNames to false (the default setting is true), in which case RNI does not perform this optimization procedure.
Constraints on maximum settings. maximumNamesToCheck and maximumResultsToReturn must be less than or equal to maximumNamesToConsider. As described above, maximumNamesToCheck may be less than maximumResultsToReturn. Accordingly, the order in which you make these settings is important. For example, you cannot set maximumResultsToReturn to a value higher than maximumNamesToConsider, so you may need to reset maximumNamesToConsider before you can reset maximumResultsToReturn.
To simulate a high-recall search with perfect recall:
Retrieve all names in the index as described in Retrieving Groups of Names.
Apply the high-precision filter to each name by matching it against the query with a
MatchScorer(see Matching Names).
This is not recommended for a production environment due to the high amount of computation such a procedure requires, but it can be useful during development to identify recall errors (false negatives) made by the high-recall search but not the high-precision filter.
Tradeoffs between false positives and false negatives
For fewer false positives (bad matches) and more false negatives (missing good matches) in your query results, you can:
increase the minimum match score that a candidate must reach to be returned
decrease the number of results that are returned (candidates with the highest scores are included)
The default minimum match score is NameIndexQuery.DEFAULT_MINIMUM_MATCH_SCORE. To reset this threshold, use setNameDataMinimumMatchScore(double nameDataMinimumMatchScore), where nameDataMinimumMatchScore is greater than 0 and less than or equal to 1.
The default maximum number of results to return is NameIndexQuery.DEFAULT_MAXIMUM_RESULTS_TO_RETURN. To reset this value, use setMaximumResultsToReturn(int maximumResultsToReturn).
To return an unlimited number of results, use setMaximumResultsToReturn(NameIndexQuery.UNLIMITED_RESULTS).
RNI sessions and transactions
In addition to using the INameIndex API for performing operations on an RNI Index, you can use the INameIndexSession API for finer-grained control. Sessions allow a set of operations to happen atomically (all occur or nothing occurs), and, especially for write operations, more efficiently. For those familiar with relational databases and SQL, the RNI concept of a session is similar to the JDBC concept of a connection with auto-commit mode off.
To start a session, call
INameIndex.openSession().To end the session, call
close()on the resultantINameIndexSessionobject.
While INameIndexSession provides many of the same operations as INameIndex, such as query() and addName(), the difference is when changes to the index become permanent. INameIndex update operations are immediately flushed to disk, but INameIndexSession operations are not made permanent until you call commit(). At any time, you can invoke rollback() to undo all the operations since the last commit(). If you call rollback() before ever calling commit(), all of the operations of the session are undone.
You can run multiple sessions concurrently by having multiple threads call openSession() on the same INameIndex object. When multiple sessions are acting concurrently in separate threads, they are logically isolated from each other in order to not interfere with each other's operations. The isolation level is equivalent to READ COMMITTED, as outlined in the SQL-1992 Specification. This guarantees that one session will not see any uncommitted changes to the index performed by another session. In addition, a session will not see any uncommitted changes that it has made itself. For example, if a session adds a name to the index and then searches for that name before committing, it will not find the name it has added. You can also perform INameIndex auto-commit operations in the midst of one or more sessions; each INameIndex update or query is performed in its own session.
The session objects themselves are thread-safe; a session object may be shared by multiple threads.
The INameIndexSession API is recommended for doing bulk adds to the index. It is much more efficient to create a single session for adding all the names of a bulk add than to use the INameIndex API. The following fragment shows an example.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/add_names.java
A Sample. For a sample application that adds multiple names in a single transaction, see AddNamesSample.
Local vs. Distributed Transactions. A local transaction is a set of operations performed atomically (all occur or nothing occurs) on a single index. A distributed transaction is a set of operations performed atomically on multiple data sources, such as a relational database and an RNI index. All the operations on all the data sources must take place, or none of the operations take place.
For local transactions, use the INameIndexSession API, as illustrated above. The transaction object is managed internally and is not visible to the user.
In order to participate in a distributed transaction, an INameIndexTransaction object must be created from the session by calling INameIndexSession.startTransaction(). This transaction object is linked with the session internally. There is a division of labor between the two objects: the session object can only be used for adding/removing/searching, and the transaction object can only be used for committing or rolling back. A typical use case would be to provide the session object to the user application while handing over the transaction object to a transaction manager.
One side effect of this division of labor between the session and transaction objects is that a session cannot call commit() or rollback() once it is associated with a distributed transaction. These operations are only allowed by the linked transaction object. Specifically, after calling INameIndexSession.startTransaction(), you should not call INameIndexSession.commit(). You must call INameIndexTransaction.commit() instead.
A session can be associated with multiple distributed transactions, one at a time. When the work for one transaction is finished, you may call INameIndexSession.startTransaction() again to start a new one.
Two-Phase Commit. INameIndexTransaction supports two-phase commits, a standard protocol for managing transactions robustly among multiple data sources. INameIndexTransaction provides the prepare(), commit(), and rollback() operations necessary for a transaction manager to effectively execute the protocol. RNI does not include a transaction manager.
The following simplified example illustrates the use of INameIndexTransaction in a distributed transaction with a two-phase commit. In this example, both transactions are RNI transactions.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/distributed_transaction.java
A Sample. For a sample application that illustrates a distributed transaction with a two-phase commit involving two RNI indexes, see DistributedTransactionSample.
Multithreading
No more than one INameIndex object may exist for a given name index on disk at any time.
Queries and updates may be performed in multiple threads on a single INameIndex object.
One write session at a time
While a write session (which may be shared by multiple threads) is open, all other writing sessions (including optimization) are blocked. If there is an operation that is expected to take a long time (e.g., batch document adds or calls to optimize), care should be taken to ensure it is the only active writing session. If a write attempt needs to wait too long, a timeout exception is thrown, and the transaction is aborted.
Matching organizations with real world IDs
Organizations and companies often have nicknames which are very different from the company's official name. For example, International Business Machines, or IBM, is known by the nickname Big Blue. As there is no phonetic similarity between the two names, a match query between those two organization names would result in a low score. A real world identifier associates companies, along with their associated nicknames and permutations, with an identifier. When enabled, a search between two company names will include a comparison between the real world identifiers for the two names, thus matching dissimilar names for the same corporate entity.
RNI contains real world identifiers for corporations, which pair an entity id with nicknames and common permutations of the corporation name. Name matching within a language lists the languages with provided real-world ID dictionaries. Customers can also generate their own real-world ID dictionaries to supplement the provided dictionaries.
Parameter | Description | Default |
|---|---|---|
| Enables real world iIDs, indexes the real-world ids as corporation names are added to the index. Must reindex if you enable it after indexing. |
|
| Enables querying with real world IDs; set by language pair. |
|
realWorldIdScore | Sets the match score when two names match due to matching real world IDs. Set by language pair. | 0.98 |
nameRealWorldQueryBoost | Boosts the value of the real world ID results from the first pass. Increases the likelihood of real world ID matches being returned from the first pass. Set by language pair. | 35 |
Building a real world ID file
Many companies have their own file of organizations with their different names. To improve matching between organization names, you can supplement the real world IDs provided in RNI and build your own file of real world IDs. The provided file will build a binary file in the specified output directory named <LANG>_ORGANIZATION_ids.bin where <LANG> is the three-letter language code of the file.
The input file is a tab separated file (.tsv). Each line contains an organization name and a corresponding alphanumeric ID. The file can only contain a single language and script. You must create a separate file for each language.
IBM WE1X92 Big Blue WE1X92 International Business Machines WE1X92
Unzip the file realWorldIDBuilder.zip found in the plugins/rni/bt_root directory and run the build command. Instructions on how to run the program are in the README.md file in the zip file.
Omit real world IDs
You may want to use real world ID matching even if there are some entities which you do not want to match via real world IDs. You can omit specific organizations and QIDs (Wikidata's identifier for entities) from matching by creating an omit file listing the organization names and QIDs you would like to omit.
The omit file is a tab separated file (.tsv) named <LANG>_ORGANIZATION_ids.tsv where <LANG> is the three-letter language code of the file. Each omit file can only contain names in one language and separate files must be made for each language. There are three types of lines that can appear in an omit file, which have different effects on omission: pairs, lone names, and lone QIDs.
Pair: A name and a QID on the same line. The QID will no longer be used for matching against the name. The same name can be associated with multiple QIDs to omit by placing each pair on its own line.
Lone name: A name followed by an asterisk in the QID column. The name will not be used at all for RWID matching.
Lone QID: A QID is preceded by an asterisk in the name column. No names in the specified language will be able to match against each other using this QID.
Example:
IBM Q37156 Nintendo * * Q45700
To enable an omit file in RNI:
Place the omit file in the
BT_ROOTdirectory.Open
omit_ids.datafiles, which is in theplugins/rni/bt_root/rlpnc/data/real_world_ids/ref/omit_idsdirectory by default.Add a new entry for your omit file following the format
<LANG>_ORGANIZATION tab * tab <file path>, where LANG is the three-letter language code of the file. File paths must be relative to BT_ROOT, meaning absolute paths will not work. For example:ara_ORGANIZATION * rlpnc/data/real_world_ids/ref/omit_ids/ara_ORGANIZATION_ids.tsv
Save
omit_ids.datafiles.
Matching addresses
RNI provides a Java API for matching addresses in English, Traditional Chinese, and Simplified Chinese.
In the RNI context, address matching means comparing two addresses, performing linguistic analysis per address field, and returning a score (a double greater than zero and less than or equal to one) that indicates how similar the two addresses are. A value of 1.0 is returned if and only if the two addresses are identical (each address field matches exactly). A score of less than 1.0 is returned for addresses that potentially match, with a score indicating the relative similarity of the two addresses.
Note
Address matching in Latin script is optimized for addresses in English. Non-English addresses in Latin script may also be matched; results will vary by language.
Address definition
Addresses can be defined either as a set of address fields or as a single string. When defined as a string, the jpostal library[11] is used to parse the address string into address fields.
When entered as a set of fields, the address may include any of the fields in Table 19, “Supported Address Fields”. At least one field must be specified, but no specific fields are required.
RNI optimizes the matching algorithm to the field type. Named entity fields, such as street name, city, and state, are matched using a linguistic, statistically-based algorithm that handles name variations. Numeric and alphanumeric fields, such as house number, postal code, and unit, are matched using character-based methods.
Field Name | Description | Example(s) |
|---|---|---|
| venue and building names | "Brooklyn Academy of Music", "Empire State Building" |
| usually refers to the external (street-facing) building number | "123" |
| street name(s) | "Harrison Avenue" |
| an apartment, unit, office, lot, or other secondary unit designator | "Apt. 123" |
| expressions indicating a floor number | "3rd Floor", "Ground Floor" |
| numbered/lettered staircase | "2" |
| numbered/lettered entrance | "front gate" |
| usually an unofficial neighborhood name | "Harlem", "South Bronx", "Crown Heights" |
| these are usually boroughs or districts within a city that serve some official purpose | "Brooklyn", "Hackney", "Bratislava IV" |
| any human settlement including cities, towns, villages, hamlets, localities, etc. | "Boston" |
| named islands | "Maui" |
| usually a second-level administrative division or county | "Saratoga" |
| a first-level administrative division | "Massachusetts" |
| informal subdivision of a country without any political status | "South/Latin America" |
| sovereign nations and their dependent territories, which have a designated ISO-3166 code | "United States of America" |
| currently only used for appending "West Indies" after the country name, a pattern frequently used in the English-speaking Caribbean | "Jamaica, West Indies" |
| postal codes used for mail sorting | "02110" |
| post office box: typically found in non-physical (mail-only) addresses | "28" |
Address field groups
When an address is parsed into address fields, values can get put into the wrong field. Address field groups encapsulate common transpositions between fields. When scoring matching values in fields, RNI uses address field groups to group related or similar fields. If two field values match, but they are dissimilar fields, RNI applies a penalty to that match, reducing the score for that pair.
When matching two fields, the following penalties are applied:
If the fields are the same, no penalty is applied. (street - street)
If the fields are different, but the fields are in the same group, a small penalty is applied. (suburb - city)
If the fields are in different field groups, a large penalty is applied. (road - city)
Group | Fields |
|---|---|
house | house |
house_number | houseNumber |
road | road |
unit | unit level staircase entrance |
city | suburb cityDistrict city |
state | island stateDistrict state |
country | countryRegion country worldRegion |
post_code | postCode |
po_box | po_box |
Address matching usage model
Identify two addresses to compare.
Use MatchScorer to score the similarity of two AddressSpec objects. MatchScorer and AddressSpec are in the com.basistech.rni.match and com.basistech.rni.match.address packages respectively.
// Use MatchScorer to match two addresses.
void match2Addresses(AddressSpec addr1, AddressSpec addr2) {
MatchScorer ms = new MatchScorer();
double score = ms.score(addr1, addr2);
// Handle the score.
System.out.println("Score: " + score);
// Release resources used by the match scorer.
ms.close();
}How Rosette calculates address match scores
The address match score is a value between 0.0 and 1.0; the higher the score, the stronger the match. The score is a relative indication of how similar two addresses are; it is not an absolute value. Calculating the match score is a complex process that utilizes multiple matching techniques and algorithms, as explained below.
Identify the address fields. This step is only performed if the address is provided as an unparsed string. In that case, Rosette uses the jpostal library to parse the addresses into address fields. This process works well for well-formatted addresses, but may have difficulty when an addresses are irregularly formatted.
For example, most addresses are formatted from specific to general:
houseNumber road city state postCode
The parser would provide predictable results for an address in an expected order:
38 Concord Road, Apt. B Arlington MA
The parser would have more difficulty if the address format was in an unexpected order:
Arlington MA Concord Road #38 Apt B
If you are getting unexpected match values, check how the addresses are being parsed into address fields.
Normalize the fields in each address. Address fields are normalized so they can be compared. Normalization includes removing stop words, such as The from The United States.
Compare each address field. For the addresses being compared, every field in each address is compared to every field in the other address, with a match score calculated for each comparison. The algorithm used will depend on the field type. Scoring algorithms include:
Edit distance: Alphanumeric fields, such as house number, are scored based on the number of character addition, substitutions, and deletions.
Fuzzy match: Text fields, such as street names, are scored with intelligent name comparison algorithms to determine how similar they are.
Postal codes: Rosette uses meanings of US, UK, and Canadian postal codes to provide scores for these fields. Even if a postal code is poorly formatted, Rosette can recognize and score the match correctly.
Select the best scores. Once all scores have been calculated, the best mapping of fields between the two addresses is selected to maximize the complete score.
Field Weights: Some fields in an address are considered more important than other fields. The score from each selected match are weighted by field types. These field type weightings can be modified based on the type of address data in your system.
Configuring address matching
Addresses have their own match parameters and override files that you can customize to achieve the best results for your data.
There are two types of override files for addresses:
Stop patterns and stop word prefixes designate address field elements to strip during indexing and queries.
Token pair overrides specify address field elements pairs that match.
File Directories
The parameters are modified in the
plugins/rni/bt_root/rlpnc/data/etc/parameter_profiles.yamlfile.The address matching override files are in the
plugins/rni/bt_root/rlpnc/data/addresses/ref/overridesdirectory.The address stop word files are in the
plugins/rni/bt_root/rlpnc/data/addresses/ref/stopwordsdirectory.
Modifying address parameters
To start tuning the parameters, run address matching on the test set and look for any unexpected results. Tunable parameters are defined in parameter_defs.yaml. The parameter files are described in Parameter configuration files.
Note
Changes made to the any profile apply to all supported languages.
An example parameter to tune is addressJoinedTokenLimit, which controls leniency towards joining or separating tokens. For some use cases, you may decide that joining many tokens within a field is acceptable. To adjust this parameter, find an existing parameter profile or define a new one, add the parameter and modify the value. By increasing the parameter value, the addressJoinedTokenLimit will be allowed to merge more tokens.
Another example parameter is houseNumberAddressFieldWeight, which controls the weight of the houseNumber score when calculating the overall score. This type of parameter is available for all address fields, and is weighted evenly at 1 by default. For example, cityAddressFieldWeight controls the weight of the city field when matching addresses.
Once you define a profile and set a parameter value, rerun the address pairwise match, scoring the match with the edited parameter_profiles.yaml file.
Address parameters
Stop patterns and stop word prefixes
RNI uses stop patterns and stop word prefixes to remove patterns from address fields during indexing and queries before matching algorithms are applied. Using string literals to strip prefixes can be performed more quickly than the application of stop patterns (regular expressions), so you should use stop words for the efficient removal of prefixes, such as the, that you do not want to include in address matching.
For each address field, RNI performs the following steps in order:
Character-level normalization, stripping punctuation including periods, commas, hyphens, and the number sign. White space is reduced to single spaces and all characters are lower-cased.
Stop patterns are applied.
Stop words are applied.
Stop pattern
A stop pattern is a regular expression that excludes matching address field elements during indexing and queries. You can use any regular expression supported by the Java java.util.regex.Pattern class; see the Javadoc for detailed documentation.
Stop patterns for a given address field are specified in a UTF-8 file with the AddressField name:
stopregexes_LANG_ADDRESS_FIELD__FIELD.txt
where LANG is a three-letter language code and FIELD is an AddressField name. Currently, the only supported values for LANG are eng and zho. Each row in the file, except for rows that begin with #,[12] is a regular expression. Leading and trailing whitespace is removed from regex lines, so use \s at beginning and end where needed.
Note
The delimiter before FIELD is a double underscore (__)
Elements in the address fields matching any of these regular expressions are removed. Longer stop patterns are applied before shorter stop patterns, so the presence of a shorter stop pattern does not prevent the stripping of a longer pattern that includes the shorter pattern.
Stop pattern files are arranged by field in plugins/rni/bt_root/rlpnc/data/addresses/ref/stopwords. You can add patterns to existing files, or if the file doesn't exist, create a UTF-8 file in the directory and include the full address field identifier (ADDRESS_FIELD__FIELD) in the filename. For example, stopregexes_eng_ADDRESS_FIELD__CITY.txt would include regular expressions to remove elements from the CITY address field for English.
Use of complex patterns may increase processing time. When possible, use stop word prefixes.
Stop word prefixes
A stop word prefix is a string literal that strips the matching prefix from address field elements during indexing and queries.
Stop word prefixes for a given address field are specified in a UTF-8 file with the AddressField name:
stopprefixes_LANG_ADDRESS_FIELD__FIELD.txt
where LANG is a three-letter language code and FIELD is an AddressField name. Currently, the only supported values for LANG are eng and zho. Each row in the file, except for rows that begin with #,[13] is a string literal.
Note
The delimiter before FIELD is a double underscore (__)
Prefixes in the address field matching any of these string literals are removed.
Like stop patterns, longer stop word prefixes take precedence over shorter prefixes that the longer stop word contains.
RNI includes files with stop word prefixes for selected address fields in English and Chinese. These files are in plugins/rni/bt_root/rlpnc/data/addresses/ref/stopwords. You can modify the contents of these files. To add stop word prefixes for a different address field, create an additional UTF-8 file in the same subdirectory and include the full address field identifier (ADDRESS_FIELD__FIELD) in the filename. For example, stopprefixes_eng_ADDRESS_FIELD__CITY.txt would include stopword prefixes for use on CITY address field for English.
Overriding token pair matches
You can create text files that specify token (address field element) pairs that match. Token pair overrides are supported for English-English, Chinese-English, and Chinese-Chinese. When RNI evaluates two address fields, each of which contains an element from the pair, it enhances the value of the resulting address match score. For example, if road and rd constitute a token pair, then the match score for Stuart Road and Stuart Rd will be higher than it would be if the token pair had not been specified.
The token pairs may be within a language or cross-lingual, as indicated by the file name:
LANG1_LANG2_FIELD.txtwhere LANG1 is the three-letter language code for the first token in each pair, LANG2 is the three letter language code for the second token in each pair, and FIELD is the AddressField name. Each entry in the file, except for rows that begin with #, is a tab-delimited token pair and may include a raw score between 0.0 and 1.0. If no score is provided, the addressOverrideDefaultScore parameter value will be used.
Token1 Tab Token2 Tab [0.0-1.0]
A token pair override score serves as a minimum score, but you can write /force after a token score to force it to be exactly that value:
Token1 Tab Token2 Tab [0.0-1.0]/force
If you would like to prevent a token pair from matching, you can use the SUPPRESS indicator as an alias for "0.0/force".
RNI includes plugins/rni/bt_root/rlpnc/data/addresses/ref/override/eng_eng_state.txt, which contains a list of U.S. state abbreviations. For example:
Massachusetts MA California CA
When you create an additional file in the same location, use the respective AddressField name in the filename to identify the address field each token element in the pair pertains to. For example zho_eng_cityDistrict.txt indicates that the contents match Chinese - English cityDistrict address fields.
Indexing addresses
RNI enables high-speed, scalable searches for addresses in English using the Apache Lucene full-text search engine to store addresses with their search keys and a key index.
When you search for an address, RNI generates a search key for each component of each address field, locates all addresses indexed by those search keys, and uses linguistic matching algorithms to filter that set of addresses down to the most similar addresses.
RNI provides a Java API that you can use to embed it in your applications.
Java packages: The address indexing classes are in com.basistech.rni.index.internal. Unqualified class names that appear in this section are in com.basistech.rni.index.internal.
For detailed information about the API, see the Java API Reference.
Reminder: If you have not already done so, you must set the Basis root directory.
Constructing an address index
An address index is an indexed list of addresses. The list includes a collection of AddressSpec objects and associated keys.
The AddressSpec object may include house, house number, road, unit, level, staircase, entrance, suburb, city district, city, island, state district, state, country region, country, world region, post code, post office box and additional fields.
Note
You can also create an index in memory that is never stored on disk.
To create an indexed list of addresses on disk, you must specify a pathname for the data store.
For example:
// Create an Address index.
// indexPathname specifies the directory where the index will be created.
StandardAddressIndex createIndex(String indexPathname) throws NameIndexStoreException,
RNTException {
StandardAddressIndex index = StandardAddressIndex.create(indexPathname);
return index;
}Now you can use AddressSpecBuilder to create AddressSpec objects and add them to the index. AddressSpecBuilder provides a fluent interface that supports method chaining.
You can also create an AddressSpec object by parsing an address using AddressSpecBuilder.parse(String str) which internally utilizes the jpostal library. The following fragment illustrates the syntax for creating and adding an AddressSpec to the index.
// Add an address to the index.
void addAddress(StandardAddressIndex index, Integer id) throws NameIndexException, IOException {
// Give the address a unique identifier. Must be a string.
String uid = Integer.toString(id);
// AddressSpecBuilder provides methods for adding address fields,
// and a build method that returns the AddressSpec.
AddressSpec addr = new AddressSpecBuilder()
.house("101")
.road("Stuart Street")
.city("Boston")
.state("MA")
.countryRegion("New England")
.uid(uid)
.build();
// AddressSpecBuilder also provides a method for parsing addresses which uses jpostal,
// and a build method that returns the AddressSpec.
AddressSpec addr2 = AddressSpecBuilder.parse("101 Stuart Street, Boston, MA").build();
index.addAddress(addr);
index.close();}When you are done adding addresses, be sure to close the address index, as in the preceding fragment.
Querying an address index
You can define and run queries that search an index for similar addresses.
Opening an address index
The primary role of an address index is to perform queries. You can also perform updates (insertions and deletions).
StandardAddressIndex provides a static method for opening an address index.
StandardAddressIndex index = StandardAddressIndex.open(String indexPathname);
indexPathname is the path to the directory that contains the address index.
To optimize the index for more efficient queries, call
index.optimize();
When you are done using the address index, you must close it:
index.close();
Defining an address search query
A query includes an AddressSpec object and several settings that you can use to constrain the query.
Set up an AddressIndexQuery object . For example:
// Define a query.
AddressIndexQuery defineQuery(AddressSpec address){
AddressIndexQuery query = new AddressIndexQuery(address);
query.setAddressDataMinimumMatchScore(.30);
return query;
}Query performance tradeoffs
You can make tradeoffs between different dimensions of performance by adjusting certain AddressIndexQuery parameters.
For more information about tradeoffs between accuracy and speed and between false positives and false negatives, refer to Query Performance Tradeoffs for names. For addresses, you will adjust the addressesToCheckAllowance and maximumAddressesToCheck AddressIndexQuery parameters.
Running the query and accessing the query results
StandardAddressIndex includes a query method that takes as its parameter the AddressIndexQuery you have set up.
The query returns an AddressIndexQueryResult list. Each AddressIndexQueryResult object provides an AddressSpec object and a similarity score. As the following fragment illustrates, you can obtain and process each AddressSpec and its score. The higher the score (greater than 0 and less than or equal to 1), the greater the confidence that this is a relevant match. A score of 1.0 indicates that the query address and result address are identical. See Address Variations. Scoring is commutative: the scores for two given addresses are always the same, regardless of which address is in the index and which address is in the query.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/address_query_index.java
AddressMatchResult. The AddressIndexQueryResult provides an AddressMatchResult object, which in turn provides a match type and score.
Cleanup
When you are done running queries, close the index:
index.close();
Sample
For a sample Java application that defines a Rosette Address Indexer query, runs the query, and reports the results, see AddressIndexQuerySample.
Multithreading
No more than one StandardAddressIndex object may exist for a given address index on disk at any time.
Queries and updates may be performed in multiple threads on a single StandardAddressIndex object.
Matching dates
RNI can match dates returning a data match score reflecting the time similarity of the two dates. Dates that are closer together are considered a stronger match and return a match score closer to 1.
For example, 11/05/1993 and 11/07/1993 have a high score, as they are very similar and just two days apart. However, 11/05/1993 and 11/05/1995 yield a low score as they differ by two years.
Date definition
A date contains a year, month, and day, but not all fields are required for matching. All common delimiters for English dates are supported, and dates can be expressed with various orderings. RNI will filter out some non-date related words. Formats that include time of day are not supported.
You can specify an Elasticsearch date format that includes time information in the mapping. The time component will be ignored.
RNI supports a wide variety of date formats. The best date format will always be the ISO standard of YYYY-MM-DD, where March 7, 1984 is written as 1984-03-07. RNI will attempt to interpret any date provided, although the less standard the format, the less guarantee that its interpretation will be the one you might expect.
Dates can be represented as YYYY-MM-DD. When some fields are unspecified, the letters represent the unknown values. For example, March 7 is YYYY-03-07, since the year in unspecified. Two digit years will be assumed to have unknown centuries. 3/7/84 is interpreted as YY84-03-07. March 7, 1984 will be an equally good match as March 7, 2084 and March 7, 1884.
When a date is provided, RNI will attempt to identify the year, month, and day within it, leaving blank any fields it cannot determine. You can omit fields if you do not have the value for one or more fields. For example: 1955-12-30, 1955--03, 12/30, -12-, --30, 1955, 1955-12- are all valid dates.
If RNI encounters an invalid date in an acceptable format, such as March 38, 1984, it will not return an error. Rather it will replace the impossible value as an unknown, March 1984.
Supported date formats
RNI supports a wide variety of date formats.
Days can be represented by 1 or 2 digits.
Months can be numerics (1 or 2 digits) or English characters (full name or 3 character abbreviation).
Years can be represented by 1, 2, 3 or 4 digits.
Supported delimiters include
, . - /, as well as a space.Partial fields can be entered.
At this time, only English month names and abbreviations are recognized.
All words are case-insensitive; upper and lower case are interpreted the same.
The following table shows different acceptable formats for the date March 7, 1984.
Format | Valid Examples | Notes |
|---|---|---|
Y-M-D | 1984-03-07; 1984/3/7; 1984.3.07; 1984 Mar 07; 1984-March-7 | |
M-D | 03-07; 3/7; Mar-07; March 7 | |
Y-M | 1984-03; 1984 March; 1984-Mar | |
YYYYMMDD | 19840307 | All 8 digits must be included |
M-D-Y | 03-07-1984; 3/7/84; March 7 84; Mar. 7, 1984 | |
M-YYYY | 03-1984; March 1984; Mar-1984 | The year must include 4 digits. March-84 will not be recognized. |
D-M-Y | 07 03 1984; 7/3/84; 07 March 84; 7/Mar/1984 | |
D-M | 07-03; 7/3; 07-Mar; 7 March | |
D(MONTH)Y | 7MAR84; 07March1984 | The month is a word or abbreviation |
YYYY | 1984 | |
Month | March |
Date match parameters
Similarly to the name matching parameters, there are a series of date matching parameters. The parameter values can be edited in the plugins/rni/bt_root/rlpnc/data/etc/parameter_defs.yaml file.
Matching records
Record similarity refers to a pairwise match between two lists of records which can include multiple fields and return a single match and match score. The fields can be any combination of RecordFieldType.RNI_NAME, RecordFieldType.RNI_DATE, and RecordFieldType.RNI_ADDRESS. The records do not have to contain the same fields; only fields with the same field name are compared. If one record has three fields and the other has two fields, the missing field will be ignored and the other two fields compared.
Each field can be assigned a weight to reflect its importance in the overall matching logic. When matching two records, some fields are more important in determining a match than others. For example, the name field is likely more important in determining a match than an address field. If no weights are defined, each field is weighted equally.
You can specify individual parameter values or a parameter universe string in the record similarity properties object to set tuning variables for the record similarity call.
When matching records, a similarity score is calculated for each field. The final match score is then calculated by performing a weighted arithmetic mean over each of the similarity scores. If a field is missing from a record, that field is removed from the score calculation and its weight is evenly distributed across the other fields. Set the score_if_null parameter to a value between 0 and 1 to include missing fields in the score. When set, that value is returned when the field is missing from the record.
Record matching usage model
Use RecordScorer to score the similarity of two records that include multiple field types, instead of the functions for a single type, such as the MatchScorer, DateScorer and AddressScorer functions for names, dates and address matching respectively.
Supported field types
The RecordScorer has default support for the RecordFieldType.RNI_NAME, RecordFieldType.RNI_DATE, and RecordFieldType.RNI_ADDRESS field types. All default similarity scores are between 0.0 and 1.0.
Field Type | Entity Type | Examples |
|---|---|---|
| PERSON | 'John David Smith' vs. 'Jon D Smith' = 0.88 |
| IDENTIFIER:DRIVERS_LICENSE | 'S82062270' vs. 'S82062272' = 0.9 |
| IDENTIFIER:LICENSE_PLATE | 'E23 2IN' vs. 'E23 2IM' = 0.875 |
| IDENTIFIER:NATIONAL_ID_NUM | '691-84-8999' vs. '691-84-9999' = 0.9167 |
| N/A | '2010-11-4' vs. '2010-5-11' = 0.92 |
| N/A | 'Red Cedar Ct' vs. 'Cedar Ct' = 0.53 |
Explainability of RNI Matching
Explainability of RNI matching
As important as getting a match score is, understanding how the system calculated the score can be just as important. When matching two names or records, RNI returns a JSON response explaining in detail how the two names, dates, addresses, or records were matched. With this information, you can understand how the score was calculated and, if necessary, modify the matching parameters to better solve your matching problems.
The following concepts are helpful when reviewing the explainInfo JSON file.
When two objects are being compared, one is referred to as the left input, one as the right input.
Every token of the left object is compared to every token of the right object. Token strings, made up of multiple tokens, may also be compared.
Names are usually composed of multiple tokens. For example, John Fitzgerald Kennedy is 3 tokens.
Common Terms
The response JSON contains sections for each type of object: names, addresses, and dates. While each object has its own criteria for comparison, there are common terms used for all comparisons, as shown below.
Term | Definition | Note |
|---|---|---|
bin | A number representing the frequency of the token in the language. A lower bin indicates the token in unusual and therefore should be more highly weighted when calculating the similarity score. | |
biasedBin | The bin raised to a power from .1 to 10 (default 0.970). This value is set by the | |
scoreInIsolation | The matching score of just the tuples being compared, ignoring things like position in the name, name weighting, etc. This will show a match core of 1.000 if it is an exact match of tokens, even if if there are biases that will lower the score in context. | |
scoreInContext | The matching score between the tuples taking into account the placement in the overall query and any biases related to the overall query. | |
(left/right)MinTokenIndex | This is the index of the first token in the string of tokens. For single tokens, the min and max tokenIndex will have the same value. An index of -1 or -2 means the token isn't in the name and the token is considered a deletion. | An index of -1 or -2 means the token isn't in the name and the token is considered a deletion. |
(left/right)MaxTokenIndex | This is the index of the last token in the string. For single tokens, the min and max tokenIndex will have the same value. An index of -1 or -2 means the token isn't in the name and the token is considered a deletion. | An index of -1 or -2 means the token isn't in the name and the token is considered a deletion. |
unbiasedScore | The raw score before any calculations using | |
score | The final score after |
Response structure
All matches responses contain the same sections. The details contained within the section can change based on the match object (names, dates, addresses).
Left/right input information: The input information for each input along with the properties for each token in the input. Properties depend on the type of object being matched.
For example, the name matching example contains the following properties:
"data": "John Smith", "normalizedData": "john smith", "latnData": "john smith", "script": "Latn", "languageOfUse": "ENGLISH", "languageOfOrigin": "ENGLISH"
While a date comparison would contain different properties:
"century": 20, "month": 10, "canonicalForm": "2024-10-01", "yearWithoutCentury": 24, "dayMonthSwapped": true, "originalString": "10 January 2024", "modifiedJulianDay": 60584, "day": 1
Tuple scores: The score for every tuple, where a tuple is a token string from the left input and a token string from the right input. Every token in the left input is matched to every token in the right input, along with some token strings (multiple tokens combined together).
Score adjustments: The score adjustments list the parameters applied, and the score calculated with those parameters.
For example, the name example here contains the following parameters:
"unbiasedScore": 0.6829129823127231, "score": 0.6919264820086959, "parameter": "adjustOneSidedDeletionScores" "unbiasedScore": 0.6919264820086959, "score": 0.8435140063279181, "parameter": "finalBias"
Meanwhile, a date comparison would contain different parameters. In this case, a different matching scheme,
tryDayMonthSwap, is tried to see if a better result is returned."score": 0.95, "unbiasedScore": 0.5926523220980572, "parameter": "tryDayMonthSwap" "score": 0.95, "unbiasedScore": 0.95, "parameter": "dateFinalBias"
Final score: The similarity score for the two names.
Example: matching names
Let's take a look at an example. In this example we're matching the following 2 names:
John Smith
Jon J Smyth
The JSON output is broken down by section.
"leftInput": {
"data": "John Smith",
"normalizedData": "john smith",
"latnData": "john smith",
"script": "Latn",
"languageOfUse": "ENGLISH",
"languageOfOrigin": "ENGLISH",
"tokens": [
{
"token": "john",
"latnToken": "john",
"bin": 5,
"biasedBin": 4.764319787410581,
"tokenWeight": 0.41435888604672094,
"tokenType": "GIVEN"
},
{
"token": "smith",
"latnToken": "smith",
"bin": 3.5,
"biasedBin": 3.3709010396413017,
"tokenWeight": 0.585641113953279,
"tokenType": "SURNAME"
}
],
"entityType": "PERSON"
},The name is tokenized. Each token is evaluated.
The entityType is identified as PERSON. We recommend always providing the entityType in your search for the best results.
The tokenTypes are identified. Even if the name was provided as Smith John, Smith would be identified as a SURNAME and John as a GIVEN name.
"rightInput": {
"data": "Jon J. Smyth",
"normalizedData": "jon j. smyth",
"latnData": "jon j. smyth",
"script": "Latn",
"languageOfUse": "ENGLISH",
"languageOfOrigin": "ENGLISH",
"tokens": [
{
"token": "jon",
"latnToken": "jon",
"bin": 3.5,
"biasedBin": 3.3709010396413017,
"tokenWeight": 0.2083122782666673,
"tokenType": "UNKNOWN"
},
{
"token": "j",
"latnToken": "j",
"bin": 8,
"biasedBin": 7.5161819937120935,
"tokenWeight": 0.08948764635417582,
"tokenType": "UNKNOWN"
},
{
"token": "smyth",
"latnToken": "smyth",
"bin": 1,
"biasedBin": 1,
"tokenWeight": 0.702200075379157,
"tokenType": "UNKNOWN"
}
],
"entityType": "PERSON"
},The name is tokenized. Each token is evaluated.
The entityType is identified as PERSON. We recommend always providing the entityType in your search for the best results.
The tokenTypes are identified. Since both Jon and Smyth are unusual spellings, the tokenType is not identified.
"scoreTuples": [
{
"scoreInIsolation": 0.7595918889283346,
"scoreInContext": 0.7595918889283346,
"left": "john",
"right": "jon",
"marked": true,1
"reason": "HMM_MATCH",
"leftMinTokenIndex": 0,
"leftMaxTokenIndex": 0,
"rightMinTokenIndex": 0,
"rightMaxTokenIndex": 0
},
{
"scoreInIsolation": 0.4912303477031893,
"scoreInContext": 0.4666688303180298,
"left": "john",
"right": "jonj",
"marked": false,
"reason": "HMM_MATCH",
"leftMinTokenIndex": 0,
"leftMaxTokenIndex": 0,
"rightMinTokenIndex": 0,
"rightMaxTokenIndex": 1
},
{
"scoreInIsolation": 0.542,
"scoreInContext": 0.4743439389212776,
"left": "john",
"right": "j",
"marked": false,
"reason": "INITIAL_MATCH",
"leftMinTokenIndex": 0,
"leftMaxTokenIndex": 0,
"rightMinTokenIndex": 1,
"rightMaxTokenIndex": 1
},
{
"scoreInIsolation": 0.2941408383164158,
"scoreInContext": 0.279433796400595,
"left": "johnsmith",
"right": "jon",
"marked": false,
"reason": "HMM_MATCH",
"leftMinTokenIndex": 0,
"leftMaxTokenIndex": 1,
"rightMinTokenIndex": 0,
"rightMaxTokenIndex": 0
},
{
"scoreInIsolation": 0.46557800000000005,
"scoreInContext": 0.4422991,
"left": "johnsmith",
"right": "j",
"marked": false,
"reason": "INITIAL_MATCH",
"leftMinTokenIndex": 0,
"leftMaxTokenIndex": 1,
"rightMinTokenIndex": 1,
"rightMaxTokenIndex": 1
},
{
"scoreInIsolation": 0.7237045473947534,
"scoreInContext": 0.7237045473947534,
"left": "smith",
"right": "smyth",
"marked": true,2
"reason": "HMM_MATCH",
"leftMinTokenIndex": 1,
"leftMaxTokenIndex": 1,
"rightMinTokenIndex": 2,
"rightMaxTokenIndex": 2
},
{
"scoreInIsolation": 0.27169000000000004,
"scoreInContext": 0.27169000000000004,
"left": "",
"right": "j",
"marked": true,3
"reason": "DELETION",
"leftMinTokenIndex": -1,
"leftMaxTokenIndex": -1,
"rightMinTokenIndex": 1,
"rightMaxTokenIndex": 1
}
],All tuples are compared. The tuples that are marked as true are the matches that are used to calculate the scores.
"scoreAdjustments": [
{
"unbiasedScore": 0.6829129823127231,
"score": 0.6919264820086959,
"parameter": "adjustOneSidedDeletionScores"
},
{
"unbiasedScore": 0.6919264820086959,
"score": 0.8435140063279181,
"parameter": "finalBias"
}
],The unbiased score is the score before the parameter is applied. The score is after the parameter is applied.
"finalScore": 0.8435140063279181
The final calculated score with all parameters applied. This is the similarity score returned by RNI.
Response schemas by object
The following sections list the JSON schema for each object type.
Name response schema
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"leftInput": {
"type": "object",
"properties": {
"data": { "type": "string" },
"normalizedData": { "type": "string" },
"latnData": { "type": "string" },
"script": { "type": "string" },
"languageOfUse": { "type": "string" },
"languageOfOrigin": { "type": "string" },
"tokens": {
"type": "array",
"items": {
"type": "object",
"properties": {
"token": { "type": "string" },
"latnToken": { "type": "string" },
"bin": { "type": "number", "default": 0.0 },
"biasedBin": { "type": "number", "default": 0.0 },
"tokenWeight": { "type": "number", "default": 0.0 },
"tokenType": { "type": "string", "default": null }
}
}
},
"entityType": { "type": "string" },
"realWorldIds": { "type" : "array", "items": { "type": "string" } }
},
"required": ["entityType"]
},
"rightInput": {
"type": "object",
"properties": {
"data": { "type": "string" },
"normalizedData": { "type": "string" },
"latnData": { "type": "string" },
"script": { "type": "string" },
"languageOfUse": { "type": "string" },
"languageOfOrigin": { "type": "string" },
"tokens": {
"type": "array",
"items": {
"type": "object",
"properties": {
"token": { "type": "string" },
"latnToken": { "type": "string" },
"bin": { "type": "number", "default": 0.0 },
"biasedBin": { "type": "number", "default": 0.0 },
"tokenWeight": { "type": "number", "default": 0.0 },
"tokenType": { "type": "string", "default": null }
}
}
},
"entityType": { "type": "string" },
"realWorldIds": { "type" : "array", "items": { "type": "string" } }
},
"required": ["entityType"]
},
"scoreTuples": {
"type": "array",
"items": {
"type": "object",
"properties": {
"scoreInIsolation": { "type": "number", "default": 0.0 },
"scoreInContext": { "type": "number", "default": 0.0 },
"left": { "type": "string" },
"right": { "type": "string" },
"marked": { "type": "boolean", "default": false },
"reason": { "type": "string" },
"leftMinTokenIndex": { "type": "integer", "default": 0 },
"leftMaxTokenIndex": { "type": "integer", "default": 0 },
"rightMinTokenIndex": { "type": "integer", "default": 0 },
"rightMaxTokenIndex": { "type": "integer", "default": 0 }
},
"required": ["left", "right", "reason"]
}
},
"scoreAdjustments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"unbiasedScore": { "type": "number", "default": 0.0 },
"score": { "type": "number", "default": 0.0 },
"parameter": { "type": "string" }
}
}
},
"finalScore": { "type": "number" }
}
}Address response schema
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"leftInput": {
"type": "object",
"properties": {
"fieldInputInfos": {
"type": "array",
"items": {
"type": "object",
"properties": {
"data": { "type": "string" },
"latnData": { "type": "string" },
"script": { "type": "string" },
"languageOfUse": { "type": "string" },
"languageOfOrigin": { "type": "string" },
"tokens": {
"type": "array",
"items": {
"type": "object",
"properties": {
"token": { "type": "string" },
"latnToken": { "type": "string" },
"tokenWeight": { "type": "number", "default": 0.0 }
}
}
},
"addressField": { "type": "string" },
"normalizedData": { "type": "string" }
},
}
}
},
"required": ["fieldInputInfos"]
},
"rightInput": {
"type": "object",
"properties": {
"fieldInputInfos": {
"type": "array",
"items": {
"type": "object",
"properties": {
"data": { "type": "string" },
"latnData": { "type": "string" },
"script": { "type": "string" },
"languageOfUse": { "type": "string" },
"languageOfOrigin": { "type": "string" },
"tokens": {
"type": "array",
"items": {
"type": "object",
"properties": {
"token": { "type": "string" },
"latnToken": { "type": "string" },
"tokenWeight": { "type": "number", "default": 0.0 }
}
}
},
"addressField": { "type": "string" },
"normalizedData": { "type": "string" }
},
}
}
},
"required": ["fieldInputInfos"]
},
"scoreTuples": {
"type": "array",
"items": {
"type": "object",
"properties": {
"scoreInIsolation": { "type": "number", "default": 0.0 },
"scoreInContext": { "type": "number", "default": 0.0 },
"left": { "type": "string" },
"right": { "type": "string" },
"marked": { "type": "boolean", "default": false },
"reason": { "type": "string" },
"leftField": { "type": "string" },
"rightField": { "type": "string" },
"leftMinTokenIndex": { "type": "number", "default": 0 },
"leftMaxTokenIndex": { "type": "number", "default": 0 },
"rightMinTokenIndex": { "type": "number", "default": 0 },
"rightMaxTokenIndex": { "type": "number", "default": 0 }
},
"required": ["left", "right", "reason", "leftField", "rightField"]
}
},
"scoreAdjustments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"unbiasedScore": { "type": "number", "default": 0.0 },
"score": { "type": "number", "default": 0.0 },
"parameter": { "type": "string" },
"leftField": { "type": "string" },
"rightField": { "type": "string" }
},
}
},
"finalScore": { "type": "number" },
"fieldScores": {
"type": "array",
"items": {
"type": "object",
"properties": {
"leftField": { "type": "string" },
"rightField": { "type": "string" },
"score": { "type": "number", "default": 0.0 },
"marked": { "type": "boolean", "default": false }
},
"required": ["leftField", "rightField"]
}
}
},
}Date response schema
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"leftInput": {
"type": "object",
"properties": {
"originalString": { "type": "string" },
"day": { "type": "integer" },
"month": { "type": "integer" },
"yearWithoutCentury": { "type": "integer" },
"century": { "type": "integer" },
"modifiedJulianDay": { "type": "integer" },
"canonicalForm": { "type": "string" },
"dayMonthSwapped": { "type": "boolean" }
}
},
"rightInput": {
"type": "object",
"properties": {
"originalString": { "type": "string" },
"day": { "type": "integer" },
"month": { "type": "integer" },
"yearWithoutCentury": { "type": "integer" },
"century": { "type": "integer" },
"modifiedJulianDay": { "type": "integer" },
"canonicalForm": { "type": "string" },
"dayMonthSwapped": { "type": "boolean" }
}
},
"scoreTuples": {
"type": "array",
"items": {
"type": "object",
"properties": {
"scoreInIsolation": { "type": "number", "default": 0.0 },
"scoreInContext": { "type": "number", "default": 0.0 },
"left": { "type": "string" },
"right": { "type": "string" },
"marked": { "type": "boolean", "default": false },
"weight": { "type": "number", "default": 0.0 },
"component": { "type": "string" },
"differenceInDays": { "type": "integer" }
},
"required": ["left", "right", "component"]
}
},
"scoreAdjustments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"unbiasedScore": { "type": "number", "default": 0.0 },
"score": { "type": "number", "default": 0.0 },
"parameter": { "type": "string" }
}
}
},
"finalScore": { "type": "number" }
}
}Using RNI with Solr
RNI includes plugins for Solr 8.11.3, and Solr 9.6.0 that support the use of RNI with Solr documents that contain names, addresses, and dates along with other data. The plugins support single-valued and multi-valued name, address, and date fields. With them, you can run Solr queries against documents that include, but are not limited to, name, address, and date fields.
Getting started with the Solr plugin
To index and search documents with RNI in a Solr application, you must add JARs to the Solr classpath, add the name fields to the schema.xml, and modify the solrconfig.xml.
Placing the Solr plugin jar
The Solr plugin Jar should be in your Solr sharedLib directory.
Jar files used by all of the cores in your Solr application (including bt-rni-solr<version>-plugin.jar) should be placed in a sharedLib directory that is defined in solr.xml.
We have placed the Solr plugin jar in rlpnc/data/rnm/sample/solr_shared_lib and included the corresponding sharedLib setting in solr.xml in our sample solr home.
Example, from rlpnc/data/rnm/sample/solr9x_home/solr.xml:
<!--Adjust the sharedlib setting if you move bt-rni-solr9x-plugins.jar to a different location.-->
<str name="sharedLib">${bt.root}/rlpnc/data/rnm/sample/solr_shared_lib</str>Modifying schema.xml
Add fieldType and field definitions to schema.xml.
In types, define the NameField field type.
<fieldType name="bt_rni_name" class="com.basistech.rni.solr.NameField" needNameStore="true"/>
In types, define the AddressField field type.
<fieldType name="bt_rni_addr" class="com.basistech.rni.solr.AddressField" needAddressStore="true"/>
In types define the DateField field type.
<fieldType name="bt_rni_date" class="com.basistech.rni.solr.DateField" needDateStore="true"/>
Add your name, address, and date fields in fields. For example:
<field name="primaryName" type="bt_rni_name" indexed="true" stored="true" multiValued="false"/> <field name="aka" type="bt_rni_name" indexed="true" stored="true" multiValued="true"/> <field name="residence" type="bt_rni_addr" indexed="true" stored="true" multiValued="false"/> <field name="dateOfBirth" type="bt_rni_date" indexed="true" stored="true" multiValued="false"/>
You can copy fragments from rlpnc/data/rnm/sample/solr8x_home/collection1/conf/schema-xml-sample-fragments.xml.
These changes can also be made using the Solr Schema API in the Solr Admin page.
Modifying solrconfig.xml
As top-level elements, add the reRank queryParser included in the RNI release along with rniMatch valueSourceParser to solrconfig.xml.
<queryParser name="rniRerank" class="com.basistech.rni.solr.RNIReRankQParserPlugin"/> <queryParser name="rniAddrRerank" class="com.basistech.rni.solr.RNIAddressReRankQParserPlugin"/> <queryParser name="rniDateRerank" class="com.basistech.rni.solr.RNIDateReRankQParserPlugin"/> <valueSourceParser name="rniMatch" class="com.basistech.rni.solr.NameMatchValueSourceParser"/> <valueSourceParser name="rniAddrMatch" class="com.basistech.rni.solr.AddressMatchValueSourceParser"/> <valueSourceParser name="rniDateMatch" class="com.basistech.rni.solr.DateMatchValueSourceParser"/>
If your documents include one or more multivalued name fields, include an RNI updateRequestProcessorChain.
<updateRequestProcessorChain name="RNIName"> <processor class="com.basistech.rni.solr.MultiValueNameUpdateRequestProcessorFactory"/> <processor class="solr.LogUpdateProcessorFactory"/> <processor class="solr.RunUpdateProcessorFactory"/> </updateRequestProcessorChain>
Modify the /update requestHandler to use the RNI update chain.
<requestHandler name="/update"
class="solr.UpdateRequestHandler">
<lst name="defaults">
<str name="update.chain">RNIName</str>
</lst>
</requestHandler>If your documents include one or more multivalued address fields, include an RNI updateRequestProcessorChain.
<updateRequestProcessorChain name="RNIAddr"> <!--Custom processor required when using multivalued address fields--> <processor class="com.basistech.rni.solr.MultiValueAddressUpdateRequestProcessorFactory"/> <processor class="solr.LogUpdateProcessorFactory"/> <processor class="solr.RunUpdateProcessorFactory"/> </updateRequestProcessorChain>
Modify the /update requestHandler to use the RNI update chain.
<requestHandler name="/update"
class="solr.UpdateRequestHandler">
<lst name="defaults">
<str name="update.chain">RNIAddr</str>
</lst>
</requestHandler>If your documents include one or more multivalued date fields, include an RNI updateRequestProcessorChain.
<updateRequestProcessorChain name="RNIDate"> <!--Custom processor required when using multivalued date fields--> <processor class="com.basistech.rni.solr.MultiValueDateUpdateRequestProcessorFactory"/> <processor class="solr.LogUpdateProcessorFactory"/> <processor class="solr.RunUpdateProcessorFactory"/> </updateRequestProcessorChain>
Modify the /update requestHandler to use the RNI update chain.
<requestHandler name="/update"
class="solr.UpdateRequestHandler">
<lst name="defaults">
<str name="update.chain">RNIDate</str>
</lst>
</requestHandler>If your documents include one or more multivalued name, address or date fields, include an RNI updateRequestProcessorChain.
<updateRequestProcessorChain name="RNI"> <!--Custom processor required when using multivalued name fields--> <processor class="com.basistech.rni.solr.MultiValueNameUpdateRequestProcessorFactory"/> <!--Custom processor required when using multivalued address fields--> <processor class="com.basistech.rni.solr.MultiValueAddressUpdateRequestProcessorFactory"/> <!--Custom processor required when using multivalued date fields--> <processor class="com.basistech.rni.solr.MultiValueDateUpdateRequestProcessorFactory"/> <processor class="solr.LogUpdateProcessorFactory"/> <processor class="solr.RunUpdateProcessorFactory"/> </updateRequestProcessorChain>
Modify the /update requestHandler to use the RNI update chain.
<requestHandler name="/update"
class="solr.UpdateRequestHandler">
<lst name="defaults">
<str name="update.chain">RNI</str>
</lst>
</requestHandler>You can copy fragments from rlpnc/data/rnm/sample/solr8x_home/collection1/conf/solrconfig-xml-sample-fragments.xml.
Starting Solr
When starting Solr, you must include a java property setting that points to the root of the RNI SDK as well as increase the heap size. If you are running JDK 17, you need to enable security manager by including -Djava.security.manager=allow in -a options. For example:
bin/solr -a "-Dbt.root=$BT_ROOT -Djava.security.manager=allow" -m 2gLoading data into Solr
The data model
Documents or records typically contain multiple names and not all are the same type. For instance, in the OFAC Specially Designated Nationals list, a record may contain a primary name and a list of akas (also known as). Ideally these would all be stored in a single Solr document to efficiently process complex queries involving multiple document fields, especially in a distributed setting.
For example, a Solr document might contain the following data:
<field name="primary">Muhammad Ali</field> <field name="aka">Cassius Clay Jr</field> <field name="aka">The Greatest</field> <field name="dob">1/7/1942</field>
Solr documents may also include multiple names referring to different persons, locations, or organizations. A single news document, for example, may contain references to a number of individuals.
Address fields
An address may include any of the fields in Table 25, “Supported Address Fields” below. At least one field must be specified, but no specific fields are required.
Addresses can be defined either as a set of address fields or as a single string. When defined as a string, the jpostal library[14] is used to parse the address string into address fields.
The format to represent an address with fields consists of non-empty consecutive address fields where each field is an AddressField's name in lower camel case (house, houseNumber, road, unit, level, staircase, entrance, suburb, cityDistrict, city, island, stateDistrict, state, countryRegion, country, worldRegion, postCode, poBox) followed by the value of the field with Hex encoded special characters preceded by the percent sign, and the value itself is enclosed with angle brackets.
RNI optimizes the matching algorithm to the field type. Named entity fields, such as street name, city, and state, are matched using a linguistic, statistically-based algorithm that handles name variations. Numeric and alphanumeric fields, such as house number, postal code, and unit, are matched using character-based methods.
Field Name | Description | Example |
|---|---|---|
| venue and building names | house<Brooklyn Academy of Music> |
| usually refers to the external (street-facing) building number | houseNumber<123> |
| street name(s) | road<Harrison Avenue> |
| an apartment, unit, office, lot, or other secondary unit designator | unit<Apt. 123> |
| expressions indicating a floor number | level<3rd Floor> |
| numbered/lettered staircase | staircase<2> |
| numbered/lettered entrance | entrance<front gate> |
| usually an unofficial neighborhood name | suburb<Crown Heights> |
| these are usually boroughs or districts within a city that serve some official purpose | cityDistrict<Brooklyn> |
| any human settlement including cities, towns, villages, hamlets, localities, etc. | city<Boston> |
| named islands | island<Maui> |
| usually a second-level administrative division or county | stateDistrict<Saratoga> |
| a first-level administrative division | state<Massachusetts> |
| informal subdivision of a country without any political status | countryRegion<South/Latin America> |
| sovereign nations and their dependent territories, which have a designated ISO-3166 code | country<United States of America> |
| currently only used for appending "West Indies" after the country name, a pattern frequently used in the English-speaking Caribbean | worldRegion<Jamaica, West Indies> |
| postal codes used for mail sorting | postCode<02110> |
| post office box: typically found in non-physical (mail-only) addresses | poBox<28> |
In the string that defines the content of an address field, place a tilde (~) after the address, followed by a comma-delimited attribute-value pair: (fielded=true) or (fielded=false) to specify whether the address consists of a single string or a set of fields.
The above example of a Solr document might contain the following additional data where the address is defined as a set of fields:
<field name="primary">Muhammad Ali</field> <field name="aka">Cassius Clay Jr</field> <field name="aka">The Greatest</field> <field name="dob">1/7/1942</field> <field name="address">houseNumber<3302>road<Grand Av.>city<West Louisville>state<KY>~fielded=true</field>
The address field can also consist of a single string, and the above example of a Solr document would look like this:
<field name="primary">Muhammad Ali</field> <field name="aka">Cassius Clay Jr</field> <field name="aka">The Greatest</field> <field name="dob">1/7/1942</field> <field name="address">3302 Grand Av., West Louisville, KY~fielded=false</field>
Date fields
Documents or records may also contain one or multiple dates in which a format can be specified. In order to specify a date format, in the string that defines the content of a date field, place a tilde (~) after the date, followed by a comma-delimited attribute-value pair: (format=dd-MM-yyyy) or (format=MMdd-yyyy) for example, to specify the format to parse the date string with.
An example including a date which is defined without specifying a format:
<field name="primary">Muhammad Ali</field> <field name="aka">Cassius Clay Jr</field> <field name="aka">The Greatest</field> <field name="dob">1/7/1942</field> <field name="address">houseNumber<3302>road<Grand Av.>city<West Louisville>state<KY>~fielded=true</field>
The date field can also consist of a date string with a specified format:
<field name="primary">Muhammad Ali</field> <field name="aka">Cassius Clay Jr</field> <field name="aka">The Greatest</field> <field name="dob">01/07/42~format=dd/MM/yy</field> <field name="address">3302 Grand Av., West Louisville, KY~fielded=false</field>
Fielded names
You can process names with data fields. Use "|" to separate the fields. For example, "Mr|Jon|Q|Smith" has four fields. You can define names with empty fields: in "|Jon|Q|Smith", the first field is ""; in "Mr|Jon||Smith", the third field is "".
You have the option of specifying that there is an unknown value in a field. To specify an unknown name field, replace the field with *?*.
Specifying name attributes
In addition to the name itself, an RNI Name object may contain attributes that you can specify when you index the name or perform a query.
Name Attribute | Example | Description |
|---|---|---|
|
| ISO 639-3 code for the language of use in which the name appears. |
|
| Hint (ISO 639-3 code) for the language of use. Only used if |
|
| ISO 639-3 code for the name's language of origin. |
|
| ISO 15924 code for the script in which the name appears. |
|
| The entity type, such as "PERSON", "LOCATION" or "ORGANIZATION". |
|
| Unique identifier for the name. |
|
| Explicit gender for the name, such as "male", "female", or "nonbinary". |
Note
The entityType field in the query must match the entityType field in the indexed name. If the query does not specify an entity type, the indexed name must also not specify an entity type.
In the string that defines the content of a name field, place a tilde (~) after the name, followed by a comma-delimited list of attribute-value pairs.
Examples:
When posting a Solr document:
<field name="primaryName">Muhammad Ali~language=eng,languageOfOrigin=ara,entityType=PERSON</field>
In a query:
primaryName:"Muhamid Ali~language=eng,languageOfOrigin=ara,entityType=PERSON"
In a pairwise name match:
&rq={!rniRerank reRankQuery=$rrq}
&rrq={!func}rniMatch(primaryName,"Muhammad Ali~language=eng,languageOfOrigin=ara,entityType=PERSON")Attributes in the bt Namespace. You can include bt attributes as query parameters. These attributes are then used in both the base query and the reRank pairwise match query. For example: &bt.language=jpn &bt.script=Kana
Setting Default Attribute Values. You can include name attributes in field or field type definition as defaults that can be overridden by individual name entries. For example:
<field name="primaryKoreanName" type="bt_rni_name" indexed="true" stored="true" multiValued="false"
language="kor" script="Hang" entityType="PERSON"/>Then you only need to include these attributes in name entries when you want to override the defaults.
Query enhancements
It is often necessary to query on other fields besides names fields, such as date of birth and address. The plugin enables the seamless integration of RNI into your Solr queries. To apply Boolean logic to queries, combine multiple fields with Boolean operators. The plugin supports all Boolean operators supported by the standard Lucene query parser (AND, OR, NOT, + , -). The OR operator is the default conjunction operator; if there is no Boolean operator between two terms (fields), the OR operator is used.
Example of a query with name and date fields:
primaryName:"Chuy Lopez A Deyas~entityType=PERSON" AND dateOfBirth:"1960-09-30"
Example of a query including an address field:
primaryName:"Chuy Lopez A Deyas~entityType=PERSON" AND residence:"road<Avenida Const. Pedro L Zavala 1957> house<Colonia Libertad>city<Culiacan>region<Sinaloa>postalCode<80180>country<Mexico>~fielded=true"
You can include name fields and other fields in your base query in conjunction with an RNI Solr reRank query and a custom valueSourceParser. The base query identifies candidate documents. The reRank query sends the top N candidates to the rniMatch valueSourceParser for pairwise matching. You can combine multiple fields in function queries which enable you to generate a relevancy score of those fields. The plugin supports all the functions available for function queries in Solr.
In a pairwise name match we return the maximum score of querying for primaryName and contactName:
&rq={!rniRerank reRankQuery=$rrq reRankMode=replace reRankWeight=1.0}
&rrq={!func}max(rniMatch(primaryName, "Chuy Lopez A Deyas"), rniMatch(contactName, "Chuy Lopez"))In a pairwise address match we return the maximum score of querying for primaryAddress and residence:
&rq={!rniAddrRerank reRankQuery=$rrq reRankMode=replace reRankWeight=1.0}
&rrq={!func}max(rniAddrMatch(primaryAddress, "road<Calle Lago Cuitzeo 1394>house<Colonia Las Quintas>
city<Culiacan>region<Sinaloa>postalCode<80060>country<Mexico>~fielded=true"),
rniAddrMatch(residence, "road<Avenida Const. Pedro L Zavala 1957>house<Colonia Libertad>
city<Culiacan>region<Sinaloa>postalCode<80180>country<Mexico>~fielded=true"))In a pairwise date match we return the maximum score of querying for dateOfBirth and dob:
&rq={!rniDateRerank reRankQuery=$rrq reRankMode=replace reRankWeight=1.0}
&rrq={!func}max(rniDateMatch(dateOfBirth, "01/07/42~format=dd/MM/yy"), rniDateMatch(dob, "1/7/1940"))You can combine the score of multiple RNI fields of the same type where each field can be given a weight to reflect its importance in the overall matching logic.
For example, in a pairwise name match we can return the combined score of querying for aka and primaryName where aka has a weight of 0.3 and the remaining 0.7 is assigned to primaryName field:
&rq={!rniRerank reRankQuery=$rrq reRankMode=replace reRankWeight=1.0}
&rrq={!func}sum(linear(rniMatch(aka, "Jesus Alfonso Diaz"), 0.3, 0),
linear(rniMatch(primaryName, "Jesus Diaz"), 0.7, 0))Setting reRank parameters
The RNIRerankQParserPlugin provides parameters that you can set to customize your reRank query:
reRankDocs(an integer) specifies the maximum number of documents from the base query to pass to the RNI pairwise match.Use this parameter to limit the number of compute-intensive name matches that need to be performed, thus decreasing maximum query latency.
reRankMode("add" or "replace") specifies whether the RNI match score is added to the Solr score (the default) or replaces the Solr score.reRankWeight(a float) specifies the weighting of the maximum RNI pairwise match score when it is combined with the Solr score. This parameter is ignored ifreRankModeis set to "replace".The RNI score, multiplied by the
reRankWeight(the Solr default is 2.0), is added to the Solr score to provide the document score that is used to determine the ordering of the documents in the result set. Use this parameter to influence the role that the RNI pairwise match plays in the ordering of the result set. If you want to prioritize the RNI score and de-emphasize the Solr score, specify a largereRankWeightreRankDocsAllowance(a float from 0 to 1) controls the general proportion of documents from the base query to pass to the RNI pairwise match. This is used at query time to dynamically determine the number of documents to rescore based on the commonality of the query name in the index. Setting this to 1.0 will ensure that the maximum number of documents (reRankDocs) are always rescored.Use this parameter to limit the number of compute-intensive name matches that need to be performed, thus decreasing query latency.
scoreToRerankRestriction(a float from 0 to 1) influences the minimum similarity score, calculated based on the results of the base query, that documents returned by the base query must have in order to be passed to the RNI pairwise match for rescoring.reRankFilter(a Solr query) further filters any results from the main query from being passed to the RNI pairwise match.
In the following example, pairwise matching is performed on the top 200 names returned by the base query, and the RNI score is multiplied by 3 before it is added to the Solr score.
q=primaryName:"Lopez Diaz"
fl=primaryName,aka,score
&rq={!rniRerank reRankQuery=$rrq reRankDocs=200 reRankWeight=3}
&rrq={!func}rniMatch(primaryName, "Lopez Diaz")Example with Solr Admin
This example walks you through the steps for using the Solr 9 Admin example to perform queries.
Download and expand Solr 9.6.0.
Start the Solr webserver.
You can point it at a Solr core included in the RNI package that contains the OFAC list already indexed. From
Solr-9.6.0, run the following:bin/solr -f -s
$BT_ROOT/rlpnc/data/rnm/sample/ofac_solr_home -a \ "-Dbt.root=$BT_ROOT-Djava.security.manager=allow" -m 2gUse a Web browser to navigate to http://localhost:8983/solr/#/collection1/query. This form provides the full interface for submitting queries in Solr Admin.
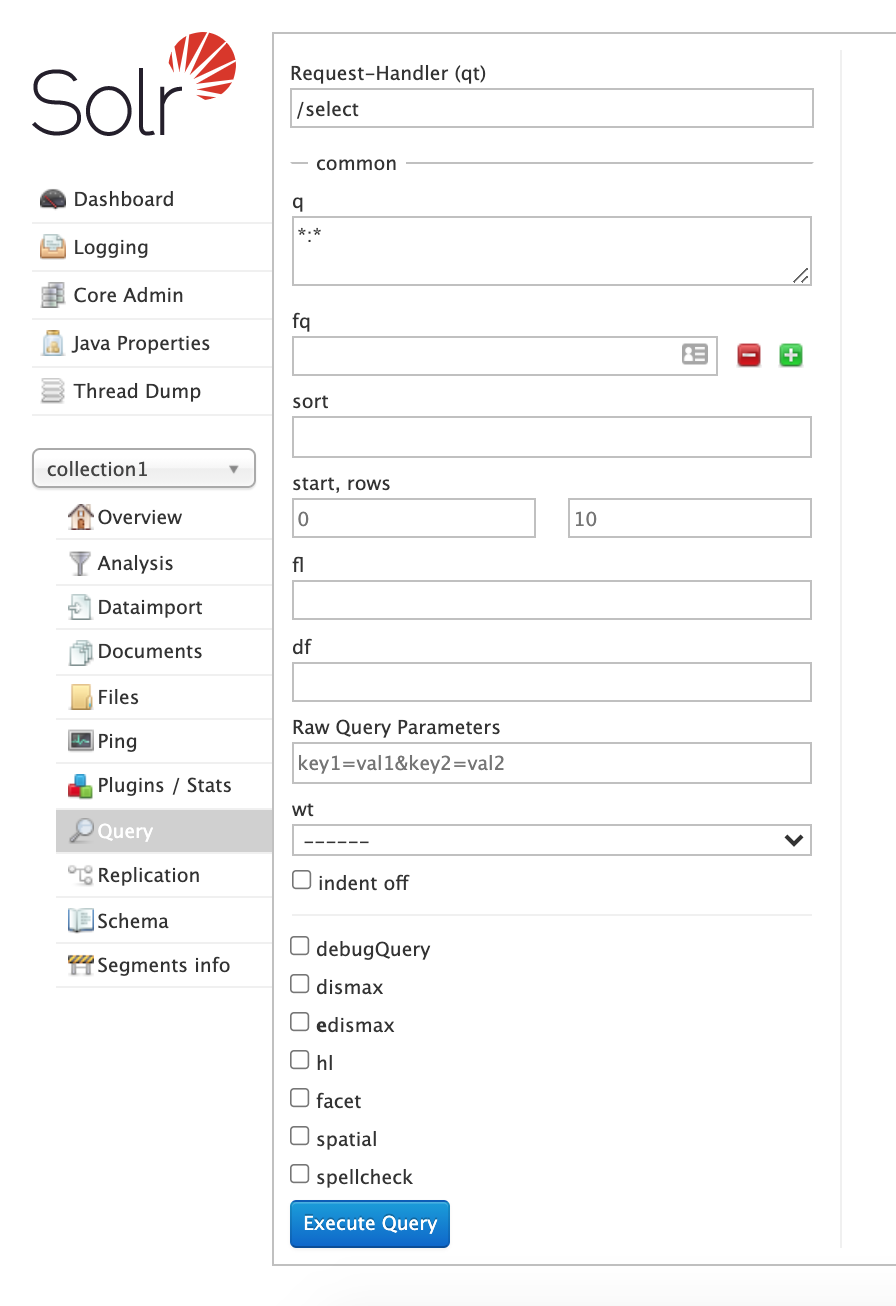
Submit a Solr Query
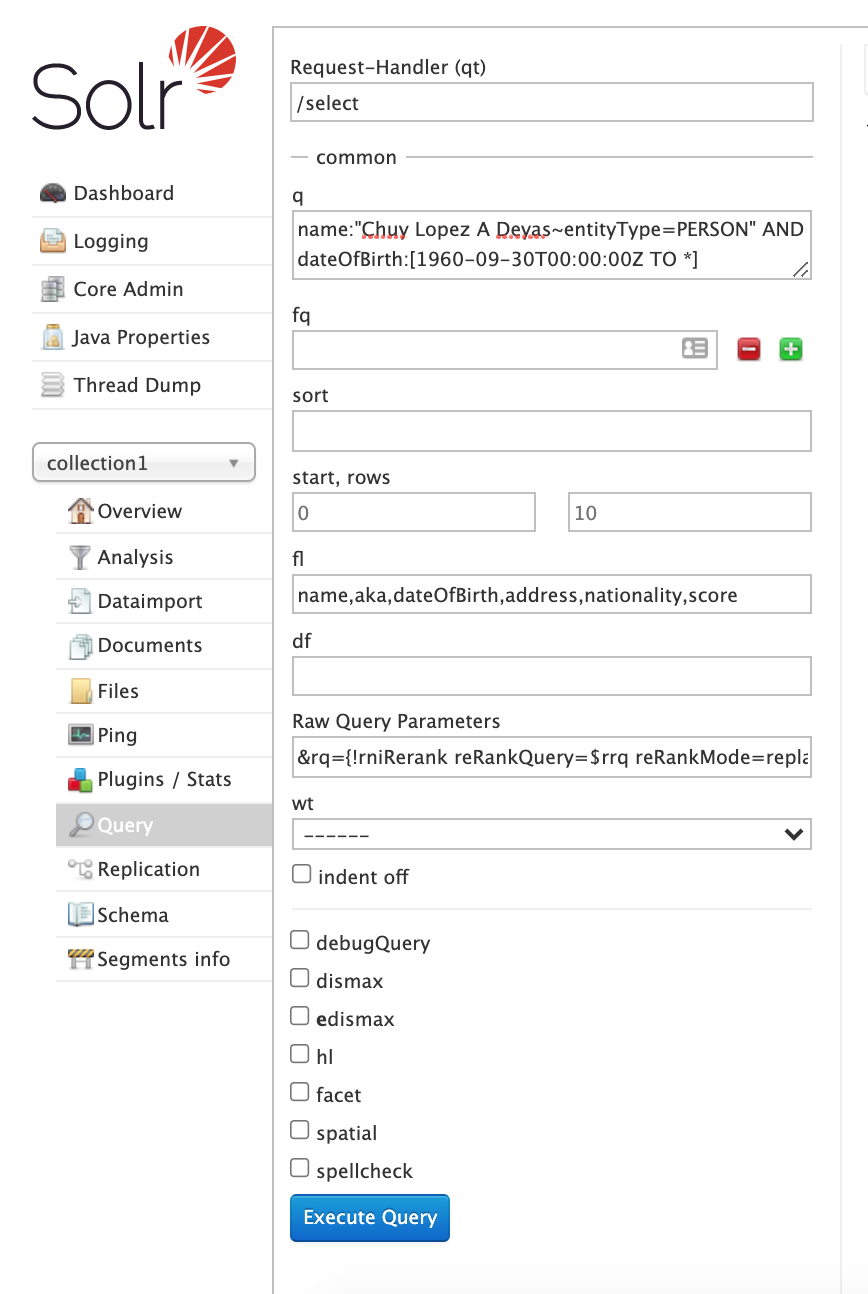
Fill in the q (query) textbox with a query that includes a name string and a date-of-birth range starting at 9/30/1960:
name:"Chuy Lopez A Deyas~entityType=PERSON" AND dateOfBirth:[1960-09-30T00:00:00Z TO *]
Fill in the fl (fields to return) textbox:
name,aka,dateOfBirth,address,nationality,score
Set raw query parameters to define the
reRankQuery&rq={!rniRerank reRankQuery=$rrq reRankMode=replace reRankWeight=1.0} &rrq={!func}rniMatch(name, "Chuy Lopez A Deyas~entityType=PERSON")Click Execute Query.
Solr Admin displays a response.
For this query, Solr returns the appropriate Diaz document.
{
{
"responseHeader": {
"status": 0,
"QTime": 387,
"params": {
"rrq": "{!func}rniMatch(name, \"Chuy Lopez A Deyas~entityType=PERSON\\")",
"q": "name:\"Chuy Lopez A Deyas~entityType=PERSON\" AND dateOfBirth:[1960-09-30T00:00:00Z TO *]",
"fl": "name,aka,dateOfBirth,address,nationality,score",
"_": "1631115490163",
"rq": "{!rniRerank reRankQuery=$rrq reRankMode=replace reRankWeight=1.0} "
}
},
"response": {
"numFound": 145,
"start": 0,
"maxScore":0.6820811,
"numFoundExact":true,
"docs": [
{
"name": "Jesus Alfonso LOPEZ DIAZ~uid=10353,entityType=PERSON",
"address": [
"c/o ESTABLO PUERTO RICO S.A. DE C.V.\nCuliacan Sinaloa\nMexico",
"Avenida Const. Pedro L Zavala 1957\nColonia Libertad\nCuliacan Sinaloa 80180\nMexico"
],
"nationality": [
"Mexico"
],
"dateOfBirth": [
"1962-09-30T00:00:00Z"
],
"score": 0.6820811
},
...
]
}
}Example using the solrj API
The RNI-RNT SDK ships with an example that illustrates the use of the org.apache.solr.client.solrj API to integrate the RNI Solr plugin into a Solr application. See RNISolrjSample. This sample also illustrates a procedure for posting Solr documents from an xml file.
You can use the org.apache.solr.client.solrj API to integrate the RNI Solr plugin into a Solr application.
The basic steps are as follows:
Add
bt-rni-solr8.11-plugin.jar(distributed inrlpnc/data/rnm/sample/solr_shared_lib/lib) to the classpath.Set
solr.solr.hometo a solr directory that contains a collection with a modifiedschema.xmlandsolrconfig.xmlas described in previous sections.Instantiate a SolrServer and use it to add documents to a Solr index. The documents should contain one or more name fields along with any other fields of interest. Name, address, and date fields may be multivalued.
Define a Solr query that involves name fields and other fields of interest, and that reranks the documents according to RNI's pairwise name match score.
Run the query and examine the documents that are returned.
The following sample code snippets use these imports:
import org.apache.solr.client.solrj.SolrQuery; import org.apache.solr.client.solrj.embedded.EmbeddedSolrServer; import org.apache.solr.client.solrj.response.QueryResponse; import org.apache.solr.common.SolrDocument; import org.apache.solr.common.SolrInputDocument; import org.apache.solr.common.params.CommonParams; import org.apache.solr.core.CoreContainer;
Setup:
// Set the bt.root property to point to the RNI installation
String btRoot = args[0];
System.setProperty("bt.root", btRoot);
// Set solr.solr.home to the parent of a collection1/conf directory that contains
// a modified schema.xml and solrconfig.xml.
String solrHome = btRoot + "/rlpnc/data/rnm/sample/solr8x_home";
System.setProperty("solr.solr.home", solrHome);
CoreContainer coreContainer = new CoreContainer(solrHome);
coreContainer.load();
// For simplicity, use an embedded SolrServer rather than an HTTPSolrServer.
EmbeddedSolrServer server = new EmbeddedSolrServer(coreContainer, "");Add a Solr document with fields of interest, including name fields:
SolrInputDocument doc = new SolrInputDocument();
// Primary name field
doc.addField("primaryName", "Midiam Patricia ZAMBADA NIEBLA");
// Multivalued also-known-as name field
doc.addField("aka", "Midian Patricia ZAMBADA NIEBLA");
doc.addField("aka", "Miriam ZAMBADA NIEBLA");
doc.addField("aka", "Midian Patricia LOPEZ LANDEY");
doc.addField("id", "3");
// Entity id field.
doc.addField("uid", "10358");
// Date field
doc.addField("dob", "1971-03-04");
// Address field
doc.addField("address", "road<Calle Lago Cuitzeo 1394>house<Colonia Las Quintas>"
+ "city<Culiacan>region<Sinaloa>postalCode<80060>"
+ "country<Mexico>~fielded=true");
doc.addField("nationality", "Mexico");
// Add the document to the index.
server.add(createInputDoc());Commit updates:
// When you have completed updates, commit the updates. server.commit();
Define and run a query against name and other fields, using RNI pairwise matching to rerank the documents returned:
// Define a query that combines name fields and other fields, and uses RNI
// pairwise matching to rerank the documents returned.
String queryName = "Chuy A Lopez";
SolrQuery solrQuery = new SolrQuery("aka" + ":\"" + queryName +
"\" AND dob:[1960-09-30T00:00:00Z TO *]");
// Set the rerank query parser parameters
solrQuery.set(CommonParams.RQ,
"{!rniRerank reRankQuery=$rrq reRankDocs=100 reRankWeight=1}");
// Create a rerank query that uses the RNI pairwise matching function
solrQuery.set("rrq", "{!func}rniMatch(" + "aka" + ", \"" + queryName + "\")");
// Set which fields to include in the results
solrQuery.setFields("uid", "primaryName", "address", "dob", "score");
QueryResponse qResults = server.query(solrQuery);
//QueryResponse qResults = server.query(createQuery());Define and run a query against name, address, and other fields, using RNI pairwise matching to rerank the documents returned:
// Define a query that combines name, address and other fields, and uses RNI
// pairwise matching to rerank the documents returned.
String queryName = "Chuy A Lopez";
String queryAddress = "road<Avenida Const. Pedro L Zavala 1957>house<Colonia Libertad>"
+ "city<Culiacan>country<Mexico>~fielded=true";
SolrQuery solrQuery = new SolrQuery("aka" + ":\"" + queryName +
"\" AND dob:\"1960-09-30\"");
// Set the rerank query parser parameters
solrQuery.set(CommonParams.RQ,
"{!rniAddrRerank reRankQuery=$rrq reRankMode=replace reRankDocs=100 reRankWeight=1}");
// Create a rerank query that uses the RNI pairwise matching function
solrQuery.set("rrq", "{!func}rniAddrMatch(" + "address" + ", \"" + queryAddress + "\")");
// Set which fields to include in the results
solrQuery.setFields("uid", "primaryName", "address", "dob", "score");
QueryResponse qResults = server.query(solrQuery);
//QueryResponse qResults = server.query(createQuery());Define and run a query against name, date, and other fields, using RNI pairwise matching to rerank the documents returned.
// Define a query that combines name, address and other fields, and uses RNI
// pairwise matching to rerank the documents returned.
String queryName = "Chuy A Lopez";
String queryDate = "04/03/1971~format=dd/MM/yyyy";
SolrQuery solrQuery = new SolrQuery("aka" + ":\"" + queryName +
"\" AND dob:\"1960-09-30\"");
// Set the rerank query parser parameters
solrQuery.set(CommonParams.RQ,
"{!rniDateRerank reRankQuery=$rrq reRankMode=replace reRankDocs=100 reRankWeight=1}");
// Create a rerank query that uses the RNI pairwise matching function
solrQuery.set("rrq", "{!func}rniDateMatch(" + "dob" + ", \"" + queryDate + "\")");
// Set which fields to include in the results
solrQuery.setFields("uid", "primaryName", "address", "dob", "score");
QueryResponse qResults = server.query(solrQuery);
//QueryResponse qResults = server.query(createQuery());Display the results:
// Print information about the documents returned with their Solr score.
for (SolrDocument rdoc : qResults.getResults()) {
System.out.println("Returned Entity: " + rdoc.getFieldValue("uid")+
"\n Name: " + rdoc.getFieldValue("primaryName") +
"\n Address: " + rdoc.getFieldValue("address") +
"\n DOB: " + rdoc.getFieldValue("dob") +
"\n Document Score: " + rdoc.getFieldValue("score"));
}For convenience utilities for working with RNI names in a Solrj environment, see the Javadoc for com.basistech.rni.solr.index.
Translating names
Rosette Name Translator (RNT) supports name translation in complex, non-Latin languages, such as Arabic and Chinese. See Supported languages of origin for the complete list of supported languages and scripts. RNT supports multiple transliteration standards for translating from non-Latin scripts to English.
Text domains
Rosette Name Translator translates a name from one text domain to another. A text domain is specified by three parameters:
Language (ISO 639)
The language of the document in which the name is found.
Writing script (ISO 15294)
The script used to represent the name, such as the Latin alphabet, Arabic script, or Chinese Han characters.
Transliteration scheme
The transliteration system in which the name is represented. If the name is in its native script, the transliteration scheme is native.
The source domain is the text domain of the document in which the name is found. The target domain is the text domain to which the name is to be translated.
Supported translation domains provides a list of supported source and target domains.
Types of translation
The type of translation depends on the characteristics of the source and target domains and the language of origin of the name to be translated. RNT supports the following types of translations:
Translation of a person name to English
How the name is translated depends on whether the language of origin of the name is the source language.
If the language of origin of the person name is the same as the source language, the name is translated according to the specified target transliteration scheme. For example, a Japanese name which is in Japanese.
If the language of origin is not the source language, the name is translated to its conventional English form. For example, a non-Japanese name that appears in Japanese.
RNT supports the following translations of names to their conventional English representation:
non-Arabic names that appear in the Arabic language
non-Chinese names that appear in the Chinese language
non-Hebrew names that appear in the Hebrew language
non-Japanese names that appear in the Japanese language
non-Korean names that appear in the Korean language
non-Russian names that appear in the Russian language
Use the languageOfOrigin Name field to inform RNT that the language of origin is not the language of use in which the name appears.
If the language of origin is Unknown (the default), the language model may classify the name as foreign (for Japanese, the script must be Katakana).
If the language of use is Japanese, the script is Kanji, and the language of origin is Chinese or Korean, RNT attempts to translate the name, using Pinyin for Chinese, and Revised Romanization of Korean for Korean.
If the language of use is Chinese and the language of origin is anything other than Chinese, RNT attempts to translate the name to its standard English representation.
If the language of use is Korean, the script is Hangul, and the language of origin is any language other than Korean, RNT attempts to translate the name to its standard English representation.
For other languages, RNT uses the specified target transliteration scheme to transliterate the name to Latin script, regardless of whether or not the name is etymologically native to the respective source language.
Example - Arabic:
Source domain: Arabic language, Arabic script, native transliteration scheme.
Target domain: English language, Latin script, IC transliteration scheme.
The translation of جورج بوش is George Bush. Note: The IC transliteration is Jwrj Bwsh.
The translation of صفية طالب السهيل (an Arabic name) is the IC transliteration: Safiyyah Talib al-Suhayl.
Example - Pashto with IC transliteration scheme:
For Pashto, if you are using the IC transliteration scheme and the language of origin is Afghan Persian, RNT provides special handling of two short vowels, using 'e' and 'o' in place of 'i' and 'u', as designated in the IC Pashto Standardized Transliteration System for Personal Names.
Source domain: Pashto language, Arabic script, native transliteration scheme.
Target domain: English language, Latin script, IC transliteration scheme.
The standard translation of اسحاق is Ishaq. If the language of origin is Afghan Persian, the translation is Eshaq.
Example - Japanese, Katakana:
Source domain: Japanese language, Katakana script, native transliteration scheme.
Target domain: English language, Latin script, Hebon transliteration scheme.
The translation of ウィリアム・シェイクスピアー is William Shakespeare. Note: The Hebon transliteration is Iriamu Shieikusupiaa.
Example - Japanese, Kanji:
Source domain: Japanese language, Kanji script, native transliteration scheme.
Target domain: English language, Latin script, Hebon transliteration scheme.
With Chinese as the language of origin, the translation (Pinyin transliteration) of 温家宝 is Wen Jiabao. Note: The Hebon transliteration of 温家宝 is On Kahou.
Example - Russian:
Source domain: Russian language, Cyrillic script, native transliteration scheme.
Target domain: English language, Latin script, BGN transliteration scheme.
The translation of Маргарет Этвуд is Margaret Atwood. Note: The BGN transliteration is Margaret Etvud.
The translation of Алекса́ндр Солжени́цын (a Russian name) is the BGN transliteration: Aleksándr Solzhenítsyn.
Example - Thai
Source domain: Thai language, Thai script, native transliteration scheme.
Target domain: English language, Latin script, ISO11940_2_2007 transliteration scheme.
The translation of นายก รัฐมนตรี (a Thai name) is the ISO11940_2_2007 transliteration: Nayok Ratthamontri.
Example - Greek
Source domain: Greek language, Greek script, native transliteration scheme.
Target domain: English language, Latin script, ISO843_1997 transliteration scheme.
The translation of Γεώργιος Αθανασιάδης-Νόβας (a Greek name) is the ISO843_1997 transliteration: Geōrgios Athanasiadīs-Novas.
Example - Hebrew
Source domain: Hebrew language, Hebrew script, English language of origin, native transliteration scheme.
Target domain: English language, Latin script, ISO259_2_1994 transliteration scheme.
The translation of ברברה סטרייסנד is Barbara Streisand. Note: The ISO259_2_1994 transliteration is Brbrah Sṭriysnd.
Note that the translation to Barbara Streisand will be returned only if the user specifies the language of origin as English.
Translation from Native script to Latin Script
This is used when the source script and the transliteration scheme are native while the target script is Latin, the transliteration scheme is something other than native, and the language of origin of the name is native.
Examples:
Source domain: Arabic language, Arabic script, native transliteration.
Target domain: English language, Latin script, IC transliteration.
The translation of صفية طالب السهيل is Safiyyah Talib al-Suhayl.
Reverse transliterations from Latin script to native script
Some transliteration schemes provide enough information to enable reverse transcription, going from English and Latin script to a native script.
Examples:
Source domain: English language, Latin script, Basis transliteration.
Target domain: Arabic language, Arabic script, native transliteration.
The translation of naayif abuu sharkh is نَايِف أَبُو شَرْخ.
Source domain: English language, Latin script, Basis transliteration.
Target domain: Russian language, Cyrillic script, native transliteration.
The translation of Dmitry Medvedev is Дмитрий Медведев.
Standardization of Arabic-origin names in English
This translation takes a name in English that is of Arabic-origin and translates the Arabic components according to the specified transliteration scheme.
Example:
Source domain: English language, Latin script, native transliteration.
Target domain: English language, Latin script, IC transliteration.
The IC standardization of Moustephah Ehmed ben Samire is Mustafa Ahmad Bin-Samir.
Orthographic completion
This is available if the source and target languages are Arabic, Hebrew, Iranian Persian, Afghan Persian, Pashto, or Urdu, the source and target scripts are Arabic or Hebrew, and the source and target transliteration schemes are native.
Language: Source and target language is Arabic, Hebrew, Iranian Persian, Afghan Persian, Pashto, or Urdu.
Script: Source and target script is Arabic or Hebrew script.
Transliteration: Source and target transliteration scheme is native.
In conventional Arabic and Hebrew script, short vowels and other diacritics are not included. In orthographic completion, the translator attempts to vocalize the names by adding the short vowels and other diacritics that don't appear in conventional Arabic and Hebrew script.
You can also perform orthographic completion as part of the translation process. See Translation options.
Segmentation
Arabic, Chinese, Japanese, and Korean, names are often unsegmented, so that is there are no spaces between the words in the name. The translator attempts to segment the unsegmented names by adding spaces between the words in the name.
Segmentation is available when the source and target languages are Arabic Chinese, Japanese, or Korean and the source and target transliteration schemes are native.
You can also perform segmentation as part of the translation process. See Translation options.
Variant Latin-Script representations of name in non-Latin Script
Language: Source and target language is Arabic, Iranian Persian, Afghan Persian, Pashto, or Urdu.
Script: Source script is Arabic script; the target script is Latin script.
Transliteration: Source transliteration scheme is native; the target transliteration scheme is folk.
The variants of a multi-word name include the cross product of the variants of each word. If, for example, each word in a two-word name has 10 variants, the name has 100 variants. Accordingly, it is a good idea to translate one word at a time. A two-word translation must produce 100 variants to provide the same information as two one-word translations producing 10 variants each.
Use the com.basistech.rnt.ITranslator setMaximumResults method to control the number of variants that are returned.
Example:
Source domain: Arabic language, Arabic script, native transliteration.
Target domain: Arabic language, Latin script, folk transliteration
نبيل شعث contains two words. Ten variants of نبيل are nabil, nabile, nabille, nabeel, nabiyl, nabiyle, nabiylle, nebil, nebile, nebille. Ten variants of شعث are sha`ath, sha'ath, shaath, sha`th, sha'th, shath, cha`ath, cha'ath, chaath, cha`th. These translations use the orthographic completion option, which is turned on by default.
Automated translation
With automated translation, the client provides one or more names, input and output text domains, and types of translation desired. For each name, the application generates a list of translations and associated confidence scores.
Automated usage model for performing RNT translations:
Set up your environment.
You must define the directory in which you installed RNI-RNT (
$BT_ROOT), and instantiate an Environment object. See Handling the Runtime Environment.Create a Translator Factory and use it to instantiate a Translator.
A given translator can perform translations from one source text domain to one target text domain. The Java API includes support for creating a Translator wrapper that can handle multiple source and target domains.
Set translation options (or use the default option settings).
For a listing of the source and target language domains to which each of these translation options applies, see Supported Translation Option Domains.
Use the Translator to translate names from the source domain to the target domain.
Handle the list of one or more translation results that the Translator generates for each translation. Each result is tagged with a confidence score between 0 and 1.0. The higher the number, the higher the confidence that this is a result of interest. The sum of the confidence score for all the results that the Translator can generate is less than or equal to 1.0.
Release resources, such as the Translator and Environment.
translator.close(); environment.close();
Multithreading
RNT translators are multithreadable.
Using the API
Java Packages: The RNT classes are in com.basistech.rnt and com.basistech.rnt.options (translation options). Utility classes that RNT uses are in com.basistech.util.
Note: Unqualified class names that appear in this section are in the com.basistech.rnt and com.basistech.rnt.options packages.
For detailed information about the API, see the Java API Reference.
Sample
For a sample Java application that translates a name, see AutomatedTranslationSample.
Creating a translator
RNT provides a factory class for creating translators. The factory is responsible for instantiating the correct RNT internal implementation class, which may vary depending on the source and target text domains you specify. For a table that maps input domains to output domains, see Supported Translation Domains.
The following fragment uses the factory to create a translator for translating names from Arabic documents in Arabic script to their standard English form in Latin script, using the IC transliteration scheme:
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/create_translator.java
When you are done using the translator, close it:
translator.close();
To create a wrapper object that packages a number of Translators, use RuleSetTranslator and define a list of TranslationRules. Each TranslationRule specifies the transliteration scheme for the specified language domain and entity type (NEConstants.NE_TYPE_NONE for all entity types).
Translation options
The translations options are defined in the package com.basistech.rnt.options.
Orthographic Completion. Class:
CompleteOrthographyOptionFor Arabic, Iranian Persian, Afghan Persian, Pashto, or Urdu names in Arabic script, you can set the option to perform orthographic completion (add short vowels and other diacritics) prior to translation. The translator infers an orthographic completion if it cannot locate the name in its Arabic dictionary. For Pashto or Urdu, the translator omits orthographic completion for any named elements it cannot locate in the appropriate dictionary. The default setting for this option is true.
Given the lack of clear diacritization standards for Iranian Persian, Afghan Persian, Pashto and Urdu, the orthographic completion for these languages reflects BasisTech standards to assist the translation process, and is not intended for external use.
Suppose you are processing نايف أبو شرخ. As is the case in conventional Arabic, this text is not vocalized. For some transliteration schemes (such as IC) the transliteration of unvocalized Arabic is undefined. The translator produces NAyf 'Bw Shrkh. With the orthographic completion option, the Translator adds the missing vowels (giving نَايِف أَبُو شَرْخ) and produces the correct IC transliteration: Nayif Abu-Sharkh.
Orthographic completion is performed for Hebrew names in Hebrew script, but it is not controlled by this option. It is always enabled.
For supported languages and scripts, see Orthographic Completion.
Orthographic Minimization. Class:
MinimizeOrthographyOptionFor Arabic, Iranian Persian, Afghan Persian, Pashto, or Urdu names in Arabic script, you can set the option to devocalize (remove short vowel diacritics). The source domain and the target domain must be one of these languages, Arabic script, and Native transliteration. You can use this option to generate the Arabic script representation of names found in most media, such as news articles. The default setting for this option is false.
For supported languages and scripts, see Orthographic Minimization.
Statistical Methods. Class:
StatisticalMethodsOptionFor personal names in Arabic, Hebrew, Japanese, and Russian, use statistical methods to establish information that is not found in a dictionary. Statistical methods are used to do the following:
Classify unknown personal names as native or foreign.
(Arabic, Hebrew) Vocalize unknown personal names classified as native, or unknown personal names classified as foreign.
(Arabic, Hebrew, Japanese, Russian) translate unknown personal names classified as foreign.
For Arabic this option is set to true by default. If statistical methods are turned off, performance with Arabic input is faster, but for personal names not found in its dictionary, the translator can only mechanically transliterate the input.
For Hebrew, Japanese, and Russian, statistical analysis is always performed.
For supported languages and scripts, see Statistical Methods.
Performance Tradeoff. Class:
PerformanceTradeoffFor personal names in Arabic, Japanese, or Russian, you can control the tradeoff the translator makes between speed and correctness when it is performing statistical analysis. For Arabic, statistical methods must be turned on (the default). As mentioned above, statistical analysis is always performed for Japanese and Russian. Four settings are defined in
com.basistech.rnt.options.TradeoffEnum:For supported languages and scripts, see Performance Tradeoff.
FASTGreatest speed; least correctness
NORMALEven tradeoff between speed and correctness (the default)
CAREFULMore correctness; less speed
PRECISEGreatest correctness; least speed
Segmentation. Class:
SegmentOptionFor Chinese, Japanese or Korean names, you set the option to segment unsegmented names. Unsegmented Thai names are segmented, but it is not controlled by this option; it is always enabled.
Suppose you are processing 胡錦濤. This name is not segmented and the Pinyin transliteration is hujintao. With the segmentation option, the Translator segments the name into 胡 and 錦濤, and produces the correct Pinyin transliteration: hu jintao.
For Korean, the name may be in Hangul or Han script. For example, the following Hangul and Han representations of the same name are not segmented: 김정일 and 金正日. With the segmentation option, the Translator uses Hangul to segment either of these forms into 김 and 정일.
By default, the Segmentation option is set to true.
For supported languages and scripts, see Segmentation.
Normalization. Class:
NormalizeOptionThe normalization option applies to Arabic, Chinese, and Japanese names.
For Arabic native names, the normalizer applies a set of standardization rules. For example, the normalizer inserts a space in عبدالمجيد, producing the more standard representation: عبد المجيد (the IC transliteration is 'Abd-al-Majid).
For Chinese, normalization converts any characters in the traditional Chinese variant to the simplified Chinese variant (the standard for China). For example, the normalizer converts 張 to 张.
For Japanese names, normalization converts Kanji variants (including old Kanji) to their standard form. For example, the normalizer converts 亞 to 亜.
By default, the Normalization option is set to true.
For supported languages and scripts, see Normalization.
Pashto IC: Variant Spelling and Region. For Pashto, when applying the IC standard, these two options implement variations specified in the IC Pashto Standardized Transliteration System for Personal Names. For supported languages and scripts, see Variant Spelling and Region.
Korean Geography. For Korean, when applying the BGN standard, the standard that is actually used depends on the Korean Geography Option. For North Korea (the default) McKune-Reischauer is used. For South Korea, Revised Romanization of Korean is used. For supported languages and scripts, see Korean Geography.
Performing a translation
You can set various parameters for the ITranslator, and you must instantiate an ITranslatable object with which the Translator performs the translation.
- void setMaximumResults (int maxResults)
Sets the maximum number of candidate translations that RNT generates. If you are only interested in the best or most likely result, set this to 1.
- void setMinimumConfidence (double confidence)
Each result is tagged with a confidence score between 0 and 1.0. The higher the number, the higher the confidence that this is a result of interest.
- <T> void setOption (optionValue)
Each option is defined by a class. The options are defined in
com.basistech.rnt.options).By default,
PerformanceTradeoffis set toTradeoffEnum.NORMAL,VariantSpellingOptionis false,RegionOptionisRegionEnum.DEFAULT(region unknown), and the other options are set to true. You can use this method to reset an option. For example:setOption(new CompleteOrthographyOption(false)); setOption(new PerformanceTradeoff(TradeoffEnum.FAST);
RNT performs the translation on an ITranslatable object. An ITranslatable object contains several properties: data (the name), language, script, and entity type (person, location, organization, etc.). Language and script should match the language and script of the source text domain. Entity type may be unknown (com.basistech.util.NEConstants.NE_TYPE_NONE). The ITranslatable object may be extended to include additional information, such as geocoordinates for locations. For more information, see the Javadoc for the implementation of ITranslatable: com.basistech.rni.match.Name.
The following example translates an Arabic name: "صفية طالب السهيل".
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/translate.java
Inspecting translation results
The ITranslator translate() method returns a list of TranslationResult objects.
Each TranslationResult provides access to the translation, the confidence associated with that translation (a double from 0 to 1.0), and may provide additional information with an associated confidence score. The sum of the confidence of all the results returned by a translation is less than or equal to 1.0. The additional information may include orthographic completion (the diacritization of names in Arabic or Hebrew script), segmentation (of names in Chinese, Korean, Japanese, or Thai), and language of origin (for Arabic, Chinese, or Japanese Katakana script). By default, these options are set to true, in which case the Translator attempts to infer the additional information. You can turn off one or all of these options.
For names in Arabic script, orthographic completion means the addition of short-vowel markers and other diacritics that are absent in conventional Arabic script but required for accurate transliteration.
https://raw.githubusercontent.com/basis-technology-corp/rosette-sample-code/master/rni-rnt/inspect_translation_results.java
This translation returns a list containing one result.
Result | Value |
|---|---|
Translation (IC Transliteration) | Safiyyah Talib al-Suhayl |
Translation Confidence | 1.0 |
Orthographic Completion (Diacritization) | صَفِيَّة طَالِب اَلسُّهَيْل |
Orthographic Completion Confidence | 1.0 |
Language of Origin |
|
Overriding name pair translations
You can create UTF-8 files that specify how names are to be translated. The filenames specify the language of the source and target domains, and may specify an entity type. The file entries specify the text of the source and target names, the script of the target domain (required if the target language may be written in multiple scripts), and may specify a confidence score for the translation. RNT applies Unicode NFD normalization to the name strings, and performs the translations specified in these files. RNT supports both fullname and token overrides.
Filenames. The filenames use ISO639 three-letter codes to specify the language of the source domain and the language of the target domain. The filename may also specify an entity type.
fullnames_SRCLANG_TARGETLANG[_TYPE].txt
tokens_SRCLANG_TARGETLANG[_TYPE].txt
For example, fullnames_eng_zho_PERSON.txt would contain entries for translating English PERSON names to Chinese. fullnames_ara_eng.txt would contain entries for translating Arabic names of any or no entity type to English.
Sample Fullname Override Files. fullnames_ara_eng_LOCATION.txt, fullnames_jpn_eng_LOCATION.txt, fullnames_rus_eng_LOCATION.txt contain entries respectively for translating LOCATION names from Arabic, Japanese, and Russian to English. Entity-specific override files are additive to non-entity type overrides. Fullname overrides only take effect if the entire contents of an entry in the first column matches the entire input name.
Sample Token Override Files. tokens_ara_eng_ORGANIZATION.txt, tokens_jpn_eng_ORGANIZATION.txt, tokens_rus_eng_ORGANIZATION.txt contain entries respectively for translating ORGANIZATION names from Arabic, Japanese, and Russian to English. Entity-specific override files are additive to non-entity type overrides.
File entries. Each row in the file, except for rows beginning with #, contains tab-delimited fields with source name, target name, target script (not required if the target language is only written in one script), and optional confidence score.
source name Tab target name[ Tab target_script] [Tab confidence_score]
The confidence score must be between 0 and 1.0. If it is not included, RNT sets the confidence score to 1.0.
The following entry in fullnames_eng_zho_PERSON.txt specifies that Ho Lide should be translated to 贺 利得 with a confidence score of 0.99 if the entity type for the source name is PERSON and the script for the target domain is Hans (simplified Chinese).
Ho Lide贺 利得Hans0.99The translations you specify are not commutative, so the preceding entry has no influence on the translation of the Chinese 贺 利得 to English.
The following entry in fullnames_ara_eng.txt specifies that علي سعيد should be translated to 'Ali Sa'id with a confidence score of 1.0.
علي سعيد'Ali Sa'idYou can include multiple entries with the same source name, in which case it translates to multiple target names. The sum of the confidence scores for the source name must be between 0 and 1.0.
If you do not include result scores, and a source name translates to multiple target names, RNT sets the confidence score for each pair to 1 divided by the number of targets. If for example, a source name translates to two targets, the confidence score for each translation is 0.5. For fullname overrides, if a source name has multiple targets and only some have a specified confidence score, the confidence scores for the non-specified target names will be an even split of 1 minus the total confidence of the specified targets.
Note
Multiple override entries for tokens is not supported. If there are multiple override entries for a single token, the resulting translations will only contain the first entry in the file and ignore the others.
Note
Specifying a confidence score in token override files is only supported for the following [script/language/transliteration scheme] pairs:
source: [Khmr/khm/native] target: [Latn/eng/folk]
source: [Latn/eng/folk] target: [Cyrl/rus/native]
source: [Thai/tha/native] target: [Latn/eng/iso_11940_2]
source: [Thai/tha/native] target: [Latn/eng/iso11940_2_2007]
source: [Thai/tha/native] target: [Latn/eng/icu]
source: [Mymr/mya/native] target: [Latn/eng/folk]
source: [Mymr/mya/native] target: [Latn/eng/mlcts]
source: [Grek/ell/native] target: [Latn/eng/iso843_1997]
source: [Grek/ell/native] target: [Latn/eng/icu]
source: [Hebr/heb/native] target: [Latn/eng/folk]
source: [Hebr/heb/native] target: [Latn/eng/iso259_2_1994]
source: [Hebr/heb/native] target: [Latn/eng/icu]
source: [Hebr/heb/native] target: [Hebr/heb/native]
source: [Cyrl/rus/native] target: [Latn/eng/ic]
source: [Cyrl/rus/native] target: [Latn/eng/bgn]
source: [Cyrl/rus/native] target: [Latn/eng/und_bgn]
source: [Cyrl/rus/native] target: [Latn/eng/iso9_1995]
source: [Deva/hin/native] target: [Latn/eng/ic]
source: [Hani/yue/jyutping] target: [Latn/eng/folk]
source: [Hans/yue/jyutping] target: [Latn/eng/folk]
source: [Hant/yue/jyutping] target: [Latn/eng/folk]
For all other pairs, specifying a confidence score in the override file will not affect the score of the final result.
Location of Override Files. Place your override files in the $BT_ROOT/rlpnc/data/rnt/ref/override directory.
Tip
To define your own override tables (character streams) in place of the tables in the default directory. See the HTML API documentation for the com.basistech.rnt.DictionaryService.replaceConfiguration method.
Interactive translation
RNT provides an API that you can use to build interactive applications to translate Arabic, Iranian Persian, Afghan Persian, Pashto, Chinese, Korean, and Russian names from English or native script to standardized English. For supported transliteration schemes, see Supported Translation Domains.
The input is an Arabic, Iranian Persian, Afghan Persian, Pashto, Chinese, Korean, or Russian name in native script or in English that the user wants to translate. In the common case, the name is in English but may not conform to the desired transliteration standard.
For Arabic names, the application walks users through the procedure of generating the name in fully vocalized Arabic script (conventional Arabic does not include short vowels), and transliterating the name.
For Iranian Persian, Afghan Persian and Pashto names, the application walks the user through the process of generating the names in standard Arabic script (no short-vowel markers).
For Chinese, Korean, or Russian names, the application walks the user through the process of generating the name in Hani, Hangul, or Cyrillic.
To take full advantage of the resources that RNT Interactive provides, the user should have some familiarity with Arabic, Iranian Persian, Afghan Persian, Pashto, Chinese, Korean, and/or Russian.
For detailed information about the API, see the com.basistech.rnt.assistant package in the Java API Reference.
Overview of an interactive application
An interactive application that walks the user through the process of translating an Arabic, Iranian Persian, Afghan Persian, Pashto, Chinese, Korean, or Russian name does the following:
Sets the Basis root directory and instantiates a
TranslationAssistant.Collects user input: a name to transliterate and a description of the desired output.
The name is in English (a 'folk' transliteration) or in native script.
The output is defined as one foreign language text domain (such as Arabic, Arab, NATIVE) and one or more English text domains (such as English, Latn, BGN). See Supported Translation Domains.
Asks RNT to initialize an output object, which includes segmentation information about the input.
The segmentation may not match the segmentation implied by the user input, and needs to be recirculated to RNT as part of each user interaction. For example, in Arabic the definite article or family/clan indicator 'al' may or may not be joined to the element that follows. In some cases, whether it should be joined is unambiguous. In other cases, either segmentation is possible. The selection you make for one element may undo the selection you have already made for another element and/or may change the options available for that other element.
For each segment in the name, provides the users with a set of output alternatives. Each alternative includes the segment transliteration for the specified output text domains. For Arabic input only, the alternative may include a brief gloss and part of speech to assist the user in making a choice: either may be 'Name'; the gloss may contain a Buckwalter annotation, such as 's' for surname' or 'f' for feminine name.
When the user selects an alternative, the application passes it to the output object, and passes the current segmentation (which the selection may have changed) back to the input.
Publishes the final output: for each output text domain, the combination of alternatives that the user has selected.
When the user is done, closes interactive RNT to free resources.
Sample application
For a sample application that simulates the interactive process described above, see InteractiveTranslationSample and the source code in $BT_ROOT/rlpnc/samples/java/InteractiveTranslationSample.java.
As shipped (you can modify the sample), the input is an Arabic name: Safiyah Talib Al Suhail.
RNT divides this input into a number of segments and generates alternatives for each segment. RNT returns these alternatives in descending order of confidence (the best alternative is the first). For Arabic input only, as the following table shows, RNT provides additional information about each alternative to help the user make the best selection.
As the table also indicates, Al could be an individual component, but in the context of the word that follows, should be joined with Suhail
Arabic (native) | English (IC) | Gloss | Part of Speech |
|---|---|---|---|
صَفِيَّة | Safiyyah | pure/clear/sincere | Adj |
صَافِيَة | Safiyah | net | Noun |
صَافِيَة | Safiyah | pure/clear/sincere | Adjective |
سَافِيَاء | Safiya' | fine dust | Noun |
??? | Safiyah | original input | |
تَلِيب | Talib | Talib s Libyan | Name |
طَلِيب | Talib | Talib s | Name |
طَالِب | Talib | requesting | Adj |
تَعْلِيب | Ta'lib | canning | Noun |
تَأْلِيب | Ta'lib | rallying/assembling | Noun |
طَلَب | Talab | quest/search // request/demand | Noun |
تَأَلُّب | Ta'allub | gathering/rally/assembly | Noun |
طَلِيبَة | Talibah | Talibah s | Name |
طُلَيْب | Tulayb | Tulayb | Name |
تَعْلَب | Ta'lab | Ta'lab | Name |
??? | Talib | original input | |
اَل | Al | al- definite article | Definite Article |
آل | Al | Al family/clan of | Name |
??? | Al | original input | |
اَلسُّهَيْل | al-Suhayl | Suheil // Canopus | Name |
اَلصَّهِيل | al-Sahil | neighing | Noun |
اَلسُّهَيْلَة | al-Suhaylah | Suhaylah f | Name |
اَلسُّحَيْل | al-Suhayl | Suhayl | Name |
اَلسُّهِيل | al-Suhil | Suhil | Name |
??? | Suhail | original input |
The final output (choosing the first alternative for each segment) is as follows:
IC transliteration: Safiyyah Talib al-Suhayl
Native transliteration: صَفِيَّة تَلِيب اَلسُّهَيْل
Fully supported text domains for name matching
The following tables describe the domain pairings for which RNI provides full support. All other domain pairings have limited support, as described in Language support parameters. A domain refers to the language and script of a piece of text. For example, one domain might be Latin (Latn) script in the English (eng) language.
Note
"Language" in this appendix refers to the language of use, the language of the document in which the name is found, which may not be the language of origin associated with the name. If the language of use is undetermined, use unknown (xxx).
Note
Prior to release 7.36.0, RNI did not support any limited languages; when presented with names in those languages, an "unsupported language" error would be returned.
To set RNI to behave as it did previously, set allLanguageSupport to false.
Name matching within a language
The first table identifies the languages, and for each language the writing scripts that Rosette Name Indexer fully supports.
Cross-language matches
This table identifies the range of cross-language searching and matching that Rosette Name Indexer and name matching fully support. If your query is a name in an Arabic document in Arabic script, the query may return one or more names in English documents in Latin script, in addition to names from Arabic documents in Arabic script. If the query is a name in English and Latin script, it may return documents from any of the supported languages and their native scripts.
Note
For supported scripts for each language, see the table in section 13.1.
Supported translation domains
This section specifies supported translation domain pairs and languages of origin for names to be translated with each domain pair.
Source and target translation domains
The following table identifies the translations (target text domains) that Rosette Name Translator supports for each source text domain.
For each source domain, the target domains for each language and script combination are presented in a single row.
Translation. If the languages in the source domain and target domain do not match, Rosette Name Translator translates the name to the target language.
Language of Origin. For Arabic, Chinese, Hebrew, Japanese, and Korean, if the target language is English and the language of origin does not match the source language, Rosette Name Translator attempts to translate the name to its standard English representation. If the language of origin is the source language, Rosette Name Translator transliterates the name with the specified transliteration scheme. If the language of origin for the name object is unspecified (UNKNOWN), Rosette Name Translator guesses the language of origin. For the supported languages of origin for each domain pair, see Supported Languages of Origin.
Orthographic Enhancement. When the source and target domains match (the transliteration schemes are native), the translations are orthographic enhancements in the native script (vocalization in Arabic and Hebrew script languages, segmentation in Chinese, Japanese, Korean, or Thai).
Name Variants. When the target transliteration scheme is folk, Rosette Name Translator generates a list of variant representations of the name in Latin script.
Supported languages of origin
The following table displays the languages of origin that are supported for each source and target domain. For the full English names for the scripts, languages, and transliteration schemes, see the preceding table.
Target Domain(s) | Source Domain | Language(s) of Origin | ||||
|---|---|---|---|---|---|---|
Language | Script | Transliteration Scheme | Language | Script | Transliteration Scheme(s),... | Language(s),... |
ara | Arab | native | ara | Arab | native | ara, eng |
ara | Arab | native | eng | Latn | fbis, bgn, basis, ic, satts, buckwalter, und_bgn, ext_ic, folk | ara, eng |
ell | Grek | native | eng | Latn | iso843_1997, icu | eng, ell |
eng | Latn | bgn | ara | Arab | native | ara |
eng | Latn | bgn | pus | Arab | native | pus |
eng | Latn | bgn | fas | Arab | native | fas |
eng | Latn | bgn | urd | Arab | native | urd |
eng | Latn | bgn | pes | Arab | native | pes |
eng | Latn | bgn | eng | Latn | und_bgn | eng, ara, pus, urd, prs, pes, fas, rus, zho, kor |
eng | Latn | bgn | kor | Hang | native | kor |
eng | Latn | basis | ara | Arab | native | ara |
eng | Latn | satts | ara | Arab | native | ara |
eng | Latn | buckwalter | ara | Arab | native | ara |
eng | Latn | mcr | kor | Hang | native | kor |
eng | Latn | moct | kor | Hang | native | kor |
eng | Latn | ctc | zho | Hani | native | zho |
eng | Latn | folk | ara | Arab | native | ara |
eng | Latn | folk | pus | Arab | native | pus |
eng | Latn | folk | prs | Arab | native | prs |
eng | Latn | folk | pes | Arab | native | pes |
eng | Latn | folk | rus | Cyrl | native | rus, eng |
eng | Latn | folk | kor | Hang | native | kor, eng |
eng | Latn | folk | zho | Hani | native | zho, eng |
eng | Latn | native | eng | Latn | bgn, basis, ic | ara |
fas | Arab | native | eng | Latn | bgn, und_bgn, folk | fas |
heb | Hebr | native | eng | Latn | native | heb, eng |
hin | Deva | native | eng | Latn | ic | hin |
jpn | Hani | native | eng | Latn | hebon, kunrei | jpn, zho, kor |
jpn | Hani | native | jpn | Hira | native | jpn |
jpn | Hani | native | jpn | Hani | native | jpn, zho, kor |
jpn | Hans | native | eng | Latn | hebon, kunrei | jpn, zho, kor |
jpn | Hant | native | eng | Latn | hebon, kunrei | jpn, zho, kor |
jpn | Hira | native | eng | Latn | hebon, kunrei | jpn |
jpn | Hrkt | native | eng | Latn | hebon, kunrei | jpn, eng |
jpn | Kana | native | eng | Latn | hebon, kunrei | jpn, eng |
jpn | Jpan | native | eng | Latn | hebon, kunrei | jpn, eng, zho, kor |
kmr | Khmr | native | eng | Latn | native | kmr, eng |
kor | Hang | native | eng | Latn | bgn, ic, und_bgn, korda, mcr, moct, folk | kor, eng |
kor | Hang | native | kor | Hang | native | kor, eng |
kor | Hani | native | eng | Latn | bgn, ic, und_bgn, korda, mcr, moct, folk | kor, eng |
kor | Hani | native | kor | Hang | native | kor, eng |
kor | Kore | native | eng | Latn | bgn, ic, und_bgn, korda, mcr, moct, folk | kor, eng |
kor | Kore | native | kor | Hang | native | kor, eng |
mya | Burmese | folk | eng | Latn | icu | mya, eng |
mya | Mymr | native | eng | Latn | folk, mlcts | mya |
pes | Arab | native | pes | Arab | native | pes |
pes | Arab | native | eng | Latn | bgn, ic, und_bgn | pes |
prs | Arab | native | prs | Arab | native | prs |
prs | Arab | native | eng | Latn | bgn, ic, und_bgn | prs |
pus | Arab | native | pus | Arab | native | pus |
pus | Arab | native | eng | Latn | bgn | pus |
pus | Arab | native | eng | Latn | ic | pus, prs |
pus | Arab | native | eng | Latn | und_bgn, folk | pus |
rus | Cyrl | native | eng | Latn | bgn, ic, iso9_1995, und_bgn | rus, eng |
rus | Cyrl | native | rus | Cyrl | native | rus, eng |
tha | Thai | native | eng | Latn | icu, iso_11940_2, iso11940_2_2007 | eng, tha |
urd | Arab | native | urd | Arab | native | urd |
urd | Arab | native | eng | Latn | bgn, ic, und_bgn, folk | urd |
zho | Hani | native | eng | Latn | bgn, ic, und_bgn, hypy, hypy_toned, wade_giles, ctc | zho, eng |
zho | Hani | native | zho | Hani | native | zho, eng |
zho | Hans | native | eng | Latn | bgn, ic, und_bgn, hypy, hypy_toned, wade_giles | zho, eng |
zho | Hant | native | eng | Latn | bgn, ic, und_bgn, hypy, hypy_toned, wade_giles | zho, eng |
zho | Hant | native | zho | Hans | native | zho, eng |
Supported translation option domains
This section specifies the translation domain pairs to which each of the RNT translation options applies.
Orthographic completion
For Arabic-script names in Arabic, Iranian Persian, Afghan Persian, Pashto, or Urdu, this option (com.basistech.rnt.options.CompleteOrthographyOption) adds short vowels and other diacritics. If the language is Arabic or Hebrew[15] and statistical methods are turned on (the default), the translator statistically infers an orthographic completion if the name does not appear in its dictionary. For the other languages, orthographic completion only takes place if the name appears in the relevant dictionary. By default, this option is set to true. See Translation Options.
Orthographic Completion | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | |||||||||||||||||||||||||||||||||||||||||||||||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | ||||||||||||||||||||||||||||||||||||||||||||||
Afghan Persian (prs) | Arabic (Arab) | Afghan Persian (prs) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Afghan Persian (prs) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn) | |||||||||||||||||||||||||||||||||||||||||||||
Afghan Persian (prs) | Arabic (Arab) | Afghan Persian (prs) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn) | |||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Latin (Latn) [Deprecated domain] | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Hebrew (heb) | Hebrew (Hebr) | Hebrew (heb) | Hebrew (Hebr) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Iranian Persian (pes) | Arabic (Arab) | Iranian Persian (pes) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Iranian Persian (pes) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn) | |||||||||||||||||||||||||||||||||||||||||||||
Iranian Persian (pes) | Arabic (Arab) | Iranian Persian (pes) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn) | |||||||||||||||||||||||||||||||||||||||||||||
Pashto (pus) | Arabic (Arab) | Pashto (pus) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Pashto (pus) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Pashto (pus) | Arabic (Arab) | Pashto (pus) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Persian (fas) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Persian (fas) | Arabic (Arab) | Persian (fas) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Urdu (urd) | Arabic (Arab) | Urdu (urd) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Urdu (urd) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), BGN (bgn)[a] , IC (ic), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Urdu (urd) | Arabic (Arab) | Urdu (urd) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn)[a], IC (ic), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
[a] For Urdu, Basis implemented a BGN transliteration scheme based on an unofficial specification prior to the specification being officially adopted. | |||||||||||||||||||||||||||||||||||||||||||||||||
Orthographic minimalization
For Arabic-script names in Arabic, Iranian Persian, Afghan Persian, Pashto, or Urdu, this option (com.basistech.rnt.options.MinimizeOrthographyOption) removes diacritics for short vowels. The translation produces the Arabic script representation of names found in most print media, including news articles. By default this option is set to false. See Translation Options.
Orthographic Minimalization | ||||
|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | ||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | |
Afghan Persian (prs) | Arabic (Arab) | Afghan Persian (prs) | Arabic (Arab) | Native (native) |
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Arabic (Arab) | Native (native) |
Iranian Persian (pes) | Arabic (Arab) | Iranian Persian (pes) | Arabic (Arab) | Native (native) |
Pashto (pus) | Arabic (Arab) | Pashto (pus) | Arabic (Arab) | Native (native) |
Urdu (urd) | Arabic (Arab) | Urdu (urd) | Arabic (Arab) | Native (native) |
Statistical methods
For personal names in Arabic, Hebrew, Japanese, and Russian this option (com.basistech.rnt.options.StatisticalMethodsOption) uses statistical methods to establish information that is not found in a dictionary. For Arabic, this option is set to true by default. For Hebrew, Japanese and Russian it is always set to true. See Translation Options.
Statistical Methods | ||||
|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | ||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | |
Afghan Persian (prs) | Latin (Latn) [Deprecated domain] | Afghan Persian (prs) | Arabic (Arab) | BGN (bgn), Native (native) |
Afghan Persian (prs) | Latin (Latn) [Deprecated domain] | Afghan Persian (prs) | Arabic (Arab) | Folk (folk), Native (native) |
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Arabic (Arab) | Native (native) |
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Latin (Latn) [Deprecated domain] | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) |
Arabic (ara) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) |
Arabic (ara) | Latin (Latn) [Deprecated domain] | Arabic (ara) | Arabic (Arab) | Basis (basis), Native (native) |
Arabic (ara) | Latin (Latn) [Deprecated domain] | Arabic (ara) | Arabic (Arab) | BGN (bgn), Native (native) |
Arabic (ara) | Latin (Latn) [Deprecated domain] | Arabic (ara) | Arabic (Arab) | Buckwalter (buckwalter), Native (native) |
Arabic (ara) | Latin (Latn) [Deprecated domain] | Arabic (ara) | Arabic (Arab) | Folk (folk), Native (native) |
Arabic (ara) | Latin (Latn) [Deprecated domain] | Arabic (ara) | Arabic (Arab) | SATTS (satts), Native (native) |
English (eng) | Latin (Latn) | Afghan Persian (prs) | Arabic (Arab) | Folk (folk), Native (native) |
English (eng) | Latin (Latn) | Arabic (ara) | Arabic (Arab) | Basis (basis), Native (native) |
English (eng) | Latin (Latn) | Arabic (ara) | Arabic (Arab) | BGN (bgn), Native (native) |
English (eng) | Latin (Latn) | Arabic (ara) | Arabic (Arab) | Buckwalter (buckwalter), Native (native) |
English (eng) | Latin (Latn) | Arabic (ara) | Arabic (Arab) | Folk (folk), Native (native) |
English (eng) | Latin (Latn) | Arabic (ara) | Arabic (Arab) | SATTS (satts), Native (native) |
English (eng) | Latin (Latn) | Iranian Persian (pes) | Arabic (Arab) | Folk (folk), Native (native) |
English (eng) | Latin (Latn) | Iranian Persian (pes) | Arabic (Arab) | BGN (bgn), Native (native) |
English (eng) | Latin (Latn) | Pashto (pus) | Arabic (Arab) | BGN (bgn), Native (native) |
English (eng) | Latin (Latn) | Pashto (pus) | Arabic (Arab) | Folk (folk), Native (native) |
English (eng) | Latin (Latn) | Persian (fas) | Arabic (Arab) | BGN (bgn), Native (native) |
English (eng) | Latin (Latn) | Urdu (urd) | Arabic (Arab) | BGN (bgn), Native (native) |
Hebrew (heb) | Hebrew (Hebr) | English (eng) | Latin (Latn) | Native (native), ISO 259-2:1994 (iso259_2_1994), Folk (folk), ICU (icu) |
Iranian Persian (pes) | Latin (Latn) [Deprecated domain] | Iranian Persian (pes) | Arabic (Arab) | BGN (bgn), Native (native) |
Iranian Persian (pes) | Latin (Latn) [Deprecated domain] | Iranian Persian (pes) | Arabic (Arab) | Folk (folk), Native (native) |
Pashto (pus) | Latin (Latn) [Deprecated domain] | Pashto (pus) | Arabic (Arab) | Folk (folk), Native (native) |
Pashto (pus) | Latin (Latn) [Deprecated domain] | Pashto (pus) | Arabic (Arab) | BGN (bgn), Native (native) |
Persian (fas) | Latin (Latn) [Deprecated domain] | Persian (fas) | Arabic (Arab) | BGN (bgn), Native (native) |
Urdu (urd) | Latin (Latn) [Deprecated domain] | Urdu (urd) | Arabic (Arab) | BGN (bgn), Native (native) |
Performance tradeoff
For personal names in Arabic, Japanese, or Russian, this option (com.basistech.rnt.options.PerformanceTradeoff) controls the tradeoff the translator makes between speed and correctness. See Translation Options.
Performance Tradeoff | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | |||||||||||||||||||||||||||||||||||||||||||||||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | ||||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Latin (Latn) [Deprecated domain] | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | Chinese (zho) | Han (Hanzi) (Hani) | Native (native), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Chinese Telegraph Code (ctc), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Chinese Telegraph Code (ctc), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Simplified variant) (Hans) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Simplified variant) (Hans) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | Chinese (zho) | Han (Simplified variant) (Hans) | Native (native), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
English (eng) | Latin (Latn) | Russian (rus) | Cyrillic (Cyrl) | Folk (folk), Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Han (Kanji) (Hani) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Hiragana (Hira) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Simplified variant) (Hans) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Simplified variant) (Hans) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Traditional variant) (Hant) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Traditional variant) (Hant) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Hiragana (Hira) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Hiragana (Hira) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Katakana (Kana) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Katakana (Kana) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese syllabaries (alias for Hiragana + Katakana) (Hrkt) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese syllabaries (alias for Hiragana + Katakana) (Hrkt) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese (alias for Han + Hiragana + Katakana) (Jpan) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese (alias for Han + Hiragana + Katakana) (Jpan) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | English (eng) | Latin (Latn) | Native (native), BGN (bgn)[b], IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn)[b], IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | English (eng) | Latin (Latn) | Native (native), BGN (bgn)[b] , IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | English (eng) | Latin (Latn) | Native (native), BGN (bgn)[b], IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn)[b], IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Russian (rus) | Cyrillic (Cyrl) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), ISO 9:1995 (iso9_1995), Undiacritized BGN (und_bgn) | |||||||||||||||||||||||||||||||||||||||||||||
Russian (rus) | Cyrillic (Cyrl) | Russian (rus) | Cyrillic (Cyrl) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Russian (rus) | Cyrillic (Cyrl) | Russian (rus) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), ISO 9:1995 (iso9_1995), Undiacritized BGN (und_bgn) | |||||||||||||||||||||||||||||||||||||||||||||
[a] For transliteration of Cantonese (yue) in Han, Hans, and Hant scripts. [b] For how BGN is handled for Korean, see Korean Geography. | |||||||||||||||||||||||||||||||||||||||||||||||||
Segmentation
For Chinese, Japanese, and Korean[16] names, this option (com.basistech.rnt.options.SegmentOption) segments unsegmented names. By default, this option is set to true. See Translation Options.
Segmentation | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | |||||||||||||||||||||||||||||||||||||||||||||||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | ||||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Chinese Telegraph Code (ctc), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | Chinese (zho) | Han (Hanzi) (Hani) | Native (native), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Chinese Telegraph Code (ctc), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Simplified variant) (Hans) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Simplified variant) (Hans) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | Chinese (zho) | Han (Simplified variant) (Hans) | Native (native), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Han (Kanji) (Hani) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Hiragana (Hira) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Simplified variant) (Hans) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Simplified variant) (Hans) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Traditional variant) (Hant) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Traditional variant) (Hant) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Hiragana (Hira) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Hiragana (Hira) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese (alias for Han + Hiragana + Katakana) (Jpan) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese (alias for Han + Hiragana + Katakana) (Jpan) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese syllabaries (alias for Hiragana + Katakana) (Hrkt) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese syllabaries (alias for Hiragana + Katakana) (Hrkt) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Katakana (Kana) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Katakana (Kana) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | English (eng) | Latin (Latn) | Native (native), BGN (bgn) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), KORDA (korda), McCune-Reischauer (mcr), Revised Romanization of Korean (moct), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
[a] For transliteration of Cantonese (yue) in Han, Hans, and Hant scripts. | |||||||||||||||||||||||||||||||||||||||||||||||||
Normalization
This option (com.basistech.rnt.options.NormalizeOption) applies a set of rules to normalize Arabic native names to a standard form, converts characters in the traditional Chinese variant to the corresponding simplified Chinese variant, and for converts Japanese Kanji variants (including old Kanji) to their standard form. Normalization occurs before any other name processing. By default, this option is set to true. See Translation Options.
Normalization | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | |||||||||||||||||||||||||||||||||||||||||||||||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | ||||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | Arabic (ara) | Latin (Latn) [Deprecated domain] | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Arabic (ara) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), FBIS (fbis), BGN (bgn), Basis (basis), IC (ic), SATTS (satts), Buckwalter (buckwalter), Undiacritized BGN (und_bgn), Extended IC (ext_ic), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | Chinese (zho) | Han (Hanzi) (Hani) | Native (native), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Chinese Telegraph Code (ctc), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Hanzi) (Hani) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Chinese Telegraph Code (ctc), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Simplified variant) (Hans) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Simplified variant) (Hans) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | Chinese (zho) | Han (Simplified variant) (Hans) | Native (native), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | Chinese (zho) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Chinese (zho) | Han (Traditional variant) (Hant) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Pinyin (hypy), Hanyu Pinyin Toned (hypy_toned), Wade-Giles (wade_giles), Jyutping (LSHK)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Han (Kanji) (Hani) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Hiragana (Hira) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Kanji) (Hani) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Simplified variant) (Hans) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Simplified variant) (Hans) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Traditional variant) (Hant) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Han (Traditional variant) (Hant) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Hiragana (Hira) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Hiragana (Hira) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese (alias for Han + Hiragana + Katakana) (Jpan) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese (alias for Han + Hiragana + Katakana) (Jpan) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese syllabaries (alias for Hiragana + Katakana) (Hrkt) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Japanese syllabaries (alias for Hiragana + Katakana) (Hrkt) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Katakana (Kana) | English (eng) | Latin (Latn) | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Japanese (jpn) | Katakana (Kana) | Japanese (jpn) | Latin (Latn) [Deprecated domain] | Native (native), Hebon Romaji (hebon), Kunrei-shiki Romaji (kunrei) | |||||||||||||||||||||||||||||||||||||||||||||
Pashto (pus) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
Pashto (pus) | Arabic (Arab) | Pashto (pus) | Arabic (Arab) | Native (native) | |||||||||||||||||||||||||||||||||||||||||||||
Pashto (pus) | Arabic (Arab) | Pashto (pus) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn), IC (ic), Undiacritized BGN (und_bgn), Folk (folk) | |||||||||||||||||||||||||||||||||||||||||||||
[a] For transliteration of Cantonese (yue) in Han, Hans, and Hant scripts. | |||||||||||||||||||||||||||||||||||||||||||||||||
Variant spelling
When using the IC transliteration standard for personal names in Pashto, this option (com.basistech.rnt.options.VariantSpellingOption) specifies how long vowels are transliterated. When variant spelling is false (the default), long vowels are transliterated with a single vowel. When true, long vowels are transliterated with double vowels. For example, Hamid vs. Hamiid. See Translation Options.
Variant Spelling | ||||
|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | ||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | |
Pashto (pus) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), IC (ic) |
Pashto (pus) | Arabic (Arab) | Pashto (pus) | Latin (Latn) [Deprecated domain] | Native (native), IC (ic) |
Region
When using the IC transliteration standard for personal names in Pashto, this option (com.basistech.rnt.options.RegionOption) designates how the Pashto letter ږ (ģe) is transliterated. If the region is set to DEFAULT (unknown) or SOUTH, the transliteration is 'zh'. If the region is set to NORTH, the transliteration is 'g'. See Translation Options.
Region | ||||
|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | ||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | |
Pashto (pus) | Arabic (Arab) | English (eng) | Latin (Latn) | Native (native), IC (ic) |
Pashto (pus) | Arabic (Arab) | Pashto (pus) | Latin (Latn) [Deprecated domain] | Native (native), IC (ic) |
Korean geography
When using the BGN transliteration standard for names in Korean, this option (com.basistech.rnt.options.KorGeographyOption) designates which transliteration scheme is used. See Translation Options.
Korean Geography Option | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Source Domain | Target Domain(s) | Transliteration Scheme(s) (name),... | |||||||||||||||||||||||||||||||||||||||||||||||
Language (ISO 639-3) | Script (ISO 15924) | Language (ISO 639-3) | Script (ISO 15924) | ||||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | English (eng) | Latin (Latn) | Native (native), BGN (bgn)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Han (Hanja) (Hani) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | English (eng) | Latin (Latn) | Native (native), BGN (bgn)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Hangul (Hangŭl, Hangeul) (Hang) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | English (eng) | Latin (Latn) | Native (native), BGN (bgn)[a] | |||||||||||||||||||||||||||||||||||||||||||||
Korean (kor) | Korean (alias for Hangul + Han) (Kore) | Korean (kor) | Latin (Latn) [Deprecated domain] | Native (native), BGN (bgn)[a] | |||||||||||||||||||||||||||||||||||||||||||||
[a] For Korean, BGN uses the McKune-Reischauer (mcr) transliteration scheme if the option is | |||||||||||||||||||||||||||||||||||||||||||||||||
Appendix
Match phenomena
Match phenomena describe why token spans did or did not match. For example, some match phenomena, such as HMM_MATCH, occur when tokens are matched by a particular scorer. Others, such as DELETION, occur when tokens cannot be matched at all.
Name | Description | Example | |||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
CONFLICT | The tokens do not match. | When comparing "William Omega Stephens" and "William Kappa Stephens", "Omega" and "Kappa" are a CONFLICT. | |||||||||||||||||||||||||||||||||||||||||||||||
DELETION | The token is unmatched. | When comparing "Richard William Smith" with "Richard Smith", "william" would be considered a DELETION. | |||||||||||||||||||||||||||||||||||||||||||||||
EMBEDDING_MATCH | The tokens are semantically similar as determined by word-embedding vectors. | When comparing "boston building company" and "boston construction company", "building" and "construction" are an EMBEDDING_MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
FIELD_BLOCKED | This field cannot be matched because of a cross-field match involving the same field in the other name. | When comparing "Bob|William|Smith" with "William||Smith", "bob" is a FIELD_BLOCKED since the cross-field william match prevents it from matching with its corresponding field. | |||||||||||||||||||||||||||||||||||||||||||||||
FIELD_CONFLICT | When comparing two names that are divided into fields, these fields do not match. | When comparing "Richard|William|Smith" with "Richard|Johnson|Smith", "william" and "johnson" would be considered a FIELD_CONFLICT. | |||||||||||||||||||||||||||||||||||||||||||||||
FIELD_DELETION | When comparing two names that are divided into fields, this field is unmatched. | When comparing "Richard|Xi|Smith" with "Richard||Smith", "xi" would be considered a FIELD_DELETION. | |||||||||||||||||||||||||||||||||||||||||||||||
GIVEN_NAME_DELETION | When comparing two names that are divided into fields, the GIVEN_NAME field is unmatched. | When comparing "Richard|William|Smith" and "||William|Scott", "Richard" will be a GIVEN_NAME_DELETION if that field in both names is marked as a | |||||||||||||||||||||||||||||||||||||||||||||||
HANI_ABBREVIATION | One Hani token appears to be an abbreviation of another Hani token. | "北京大学" and "北大" are a HANI_ABBREVIATION match. | |||||||||||||||||||||||||||||||||||||||||||||||
HMM_MATCH | The tokens are similar but not identical, and the match was determined by a particular model (hidden Markov model). This is a type of fuzzy match. | "richard" and "richerd" are an HMM_MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
INITIALISM | One token is a name and the other token is the initials of the words which make up the name. | "john fitzgerald kennedy" and "JFK" are an INITIALISM. "consumer value stores" and "CVS" are an INITIALISM. | |||||||||||||||||||||||||||||||||||||||||||||||
INITIAL_MATCH | One token is the first initial of the other. | "w" and "william" are an INITIAL_MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
LANGUAGE_SPECIFIC_MATCH | The match was determined by a language-specific matcher. | "laden" and "لادن" are a LANGUAGE_SPECIFIC_MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
MATCH | The tokens are identical (after stop word elimination and normalization). | "john" and "john" are a MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
NULL | The NULL phenomenon is only listed in this table for completeness. It is only used internally and will never be returned in the SpanMatch object. | N/A | |||||||||||||||||||||||||||||||||||||||||||||||
OUT_OF_ORDER_DELETION | This unmatched token still leaves the remaining tokens out of order when it is removed. | When comparing "George Herbert Walker Bush" with "George Bush Walker", "herbert" would be considered an OUT_OF_ORDER_DELETION. | |||||||||||||||||||||||||||||||||||||||||||||||
OVERRIDE | The tokens appear as a pair on the override list. This is often used for nicknames. | "john" and "jack" will be an OVERRIDE match if they appear as a pair on the override list. | |||||||||||||||||||||||||||||||||||||||||||||||
PREFIX_INITIAL | One token is an initial that matches a prefix in the other token. In practice, the PREFIX_INITIAL phenomenon is rare. | If the | |||||||||||||||||||||||||||||||||||||||||||||||
STRING_SIMILARITY | The tokens are similar in string edit distance (number of insertions, deletions, and substitutions) but not similar enough to be a fuzzy match. | "akcd" and "xkcd" are a STRING_SIMILARITY match. | |||||||||||||||||||||||||||||||||||||||||||||||
STUCK_INITIAL | One name appears to have an initial mistakenly attached to a preceding token. | "DavidK" and "David Keith" are a STUCK_INITIAL match. | |||||||||||||||||||||||||||||||||||||||||||||||
SURNAME_DELETION | When comparing two names that are divided into fields, the SURNAME field is unmatched. | When comparing "Richard|William|Smith" and "Richard|William||", "Smith" will be a SURNAME_DELETION if that field in both names is marked as a | |||||||||||||||||||||||||||||||||||||||||||||||
TRAILING_PATRONYMIC_DELETION[a] | The unmatched token is a patronymic which has been truncated in the other name. | When comparing "Faisal bin Fahd bin Abdullah" and "Faisal bin Fahd", "bin Abdullah" is considered a TRAILING_PATRONYMIC_DELETION. | |||||||||||||||||||||||||||||||||||||||||||||||
TRUNCATED_EXACT_MATCH | The tokens are identical except that one has been slightly truncated. | "murgatroyd" and "murgatroy" are a TRUNCATED_EXACT_MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
TRUNCATED_HMM_MATCH | The tokens are similar, but not identical, and one has been slightly truncated. | "gilpatrickz" and "gillpatrick" are a TRUNCATED_HMM_MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
UNKNOWN_FIELD_MATCH | One of the tokens is part of an "unknown" field in a fielded name. The UNKNOWN_FIELD_MATCH phenomenon is rare and usually requires use of the Java API. | When comparing "Richard|William|Smith" with "Richard|William|Scott", if the first field is an "unknown" field, "richard" and "richard" would be considered an UNKNOWN_FIELD_MATCH. | |||||||||||||||||||||||||||||||||||||||||||||||
[a] Only applies to Latin script names of Arabic origin. | |||||||||||||||||||||||||||||||||||||||||||||||||
Parameters
This table lists the parameters that can be configured via paramater_profiles.yaml. When applicable, each parameter has been linked to the specific match phenomena that it impacts. You can find more information on each parameter in paramater_defs.yaml.
Parameter name | Applies to | Impacts | |||||||||||||||||||||||||||||||||||||||||||||||
addressCrossFieldScoreThreshold | Addresses | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
addressDeletionScore | Addresses | DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
addressDifferentGroupPenalty | Addresses | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
addressFinalBias | Addresses | All address match scores | |||||||||||||||||||||||||||||||||||||||||||||||
addressJoinedTokenLimit | Addresses | Concatenation[a] | |||||||||||||||||||||||||||||||||||||||||||||||
addressOverrideDefaultScore | Addresses | OVERRIDE match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
addressOverrideTablePath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
addressReorderPenalty | Addresses | Reordering[e] | |||||||||||||||||||||||||||||||||||||||||||||||
addressSameGroupPenalty | Addresses | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
addressStopPatternsPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
addressUnpairedFieldScore | Addresses | FIELD_DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
adjustOneSidedDeletionScores | All names | DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
allowNullValue | Elasticsearch | Elasticsearch setting | |||||||||||||||||||||||||||||||||||||||||||||||
alternativePairsToCheck | All names | Can affect any kind of match where English transliterations are being used, and where there are multiple possible transliterations (e.g., Chinese/Japanese/Korean readings of Han names) | |||||||||||||||||||||||||||||||||||||||||||||||
alternativeTimeProximityMatch | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
boostWeightAtBothEnds | All names | All name match scores | |||||||||||||||||||||||||||||||||||||||||||||||
boostWeightAtLeftEnd | All names | All name match scores | |||||||||||||||||||||||||||||||||||||||||||||||
boostWeightAtRightEnd | All names | All name match scores | |||||||||||||||||||||||||||||||||||||||||||||||
caseSensitiveData | All names | INITIALISM match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
cityAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
cityDistrictAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
cognateOverrideScore | All names | OVERRIDE match phenomenon for tokens marked as COGNATE in the override file | |||||||||||||||||||||||||||||||||||||||||||||||
conflictScore | All names | CONFLICT match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
conflictThreshold | All names | CONFLICT match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
countryAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
countryRegionAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
crossFieldInitialsPenalty | Fielded names | INITIAL_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
crossFieldJoinInitialPenalty | Fielded names | Concatenation[a] | |||||||||||||||||||||||||||||||||||||||||||||||
crossFieldJoinPenalty | Fielded names | Concatenation[a] | |||||||||||||||||||||||||||||||||||||||||||||||
crossFieldMatchPenalty | Fielded names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
crossLanguageGenderConflictPenalty | All names | Gender mismatch[b] | |||||||||||||||||||||||||||||||||||||||||||||||
dateFinalBias | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
dateOrdering | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
dayDistanceWeight | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
deletionScore | All names | DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
detectableLanguagesModelBased | All names | Can affect any kind of match where one or more names is in Latin script and the language is not already specified. | |||||||||||||||||||||||||||||||||||||||||||||||
detectableLanguagesRuleBased | All names | Currently, you can only enable detection of Latin script as Turkish or Vietnamese. | |||||||||||||||||||||||||||||||||||||||||||||||
editDistanceScoreBias | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
enableDynamicConfigurationEndpoints | Elasticsearch | Elasticsearch setting | |||||||||||||||||||||||||||||||||||||||||||||||
enablePromisingTermFiltering | Speed/Accuracy | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
enableYueReadings | All names | Names written in Han script | |||||||||||||||||||||||||||||||||||||||||||||||
entranceAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
equivalenceClassesPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
estimatedConflictOrDeletionScore | All names | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
exactLatnMatchScore | All names | Token normalization | |||||||||||||||||||||||||||||||||||||||||||||||
expensiveScorerJoinedTokenLimit | All names | Concatenation[a] | |||||||||||||||||||||||||||||||||||||||||||||||
fieldBlockedScore | Fielded names | OUT_OF_ORDER_DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
fieldConflictScore | Fielded names | CONFLICT match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
fieldDeletionScore | Fielded names | DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
finalBias | All names | All name match scores | |||||||||||||||||||||||||||||||||||||||||||||||
frequencyRankBias | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
genderConflictPenalty | All names | Gender mismatch[b] | |||||||||||||||||||||||||||||||||||||||||||||||
genderConflictPenaltyThreshold | All names | Gender mismatch[b] | |||||||||||||||||||||||||||||||||||||||||||||||
globalTokenCacheConfig | Speed/Accuracy | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
globalTokenPairCacheConfig | Speed/Accuracy | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
haniAbbreviationScore | All names | INITIALISM match phenomena in Han script | |||||||||||||||||||||||||||||||||||||||||||||||
haniAbbreviationThreshold | All names | INITIALISM match phenomena in Han script | |||||||||||||||||||||||||||||||||||||||||||||||
haniFourCornerCodeMismatchPenalty | All names | Names written in Han script | |||||||||||||||||||||||||||||||||||||||||||||||
hmmNormalizationAlternative | All names | HMM_MATCH phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
hmmScoreBias | All names | HMM_MATCH phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
hmmScoreLimit | All names | HMM_MATCH phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
houseAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
houseNumberAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
ignoreBadData | Elasticsearch | Elasticsearch setting | |||||||||||||||||||||||||||||||||||||||||||||||
improveSingleDigitManipulationMatch | Dates | Date match scores containing exactly one instance of digit manipulation[c] and no other differences | |||||||||||||||||||||||||||||||||||||||||||||||
initialFrequencyRank | All names | INITIAL_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
initialismMismatchPenalty | All names | HMM_MATCH phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
initialismScore | All names | INITIALISM match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
initialsConflictScore | All names | CONFLICT match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
initialsDeletionPenalty | All names | DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
initialsScore | All names | INITIAL_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
islandAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
joinedTokenInitialsPenalty | All names | Concatenation[a] INITIAL_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
joinedTokenLimit | All names | Concatenation[a] | |||||||||||||||||||||||||||||||||||||||||||||||
joinedTokenPenalty | All names | Concatenation[a] | |||||||||||||||||||||||||||||||||||||||||||||||
levelAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
libpostalDataDirPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
lowWeightTokenFrequencyRank | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
lowWeightTokenPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
maximumAlternateTokenizationRelativeDistance | All names | Affects tokenization and therefore any potential score | |||||||||||||||||||||||||||||||||||||||||||||||
maximumOrganizationInitialismLength | Organization names | INITIALISM match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
maximumPersonInitialismLength | Person names | INITIALISM match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
maxYearDistanceForDigitManipulation | Dates | Date match scores containing exactly one instance of digit manipulation[c] and no other differences. | |||||||||||||||||||||||||||||||||||||||||||||||
minFieldWeightFactor | Fielded names | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
minimumAlternateTokenizationLength | All names | Affects tokenization and therefore any potential score | |||||||||||||||||||||||||||||||||||||||||||||||
minimumOrganizationInitialismLength | Organization names | INITIALISM match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
minimumPersonInitialismLength | Person names | INITIALISM match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
monthDistanceWeight | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
nameBigramQueryBoost | Lucene searches | First-pass accuracy Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
nameDoubleMetaphoneQueryBoost | Lucene searches | First-pass accuracy Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
nameGluedQueryBoost | Lucene searches | First-pass accuracy Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
nameInitialQueryBoost | Lucene searches | First-pass accuracy Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
nameLengthMismatchPenalty | All names | DELETION match phenomenon Concatenation[a] Any phenomenon that changes the number of tokens in a name | |||||||||||||||||||||||||||||||||||||||||||||||
nameRealWorldIdQueryBoost | Lucene searches | First-pass accuracy Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
ngramLMPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
ngramThresholdPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
nicknameOverrideScore | All names | OVERRIDE match phenomenon for tokens marked as NICKNAME in override file | |||||||||||||||||||||||||||||||||||||||||||||||
numericTokenFrequencyRank | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
outOfOrderDeletionScore | All names | OUT_OF_ORDER_DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
parseUnknownFieldMarker | Fielded names | UNKNOWN_FIELD_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
poBoxAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
postCodeAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
queryAlternativeOriginLanguages | Speed/Accuracy | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
realWorldIdsPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
realWorldIdsPathUser | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
reorderCorrection | All names | Rotation | |||||||||||||||||||||||||||||||||||||||||||||||
reorderCorrectionThreshold | All names | Rotation[d] | |||||||||||||||||||||||||||||||||||||||||||||||
reorderPenalty | All names | Reordering[e] | |||||||||||||||||||||||||||||||||||||||||||||||
rniFullnameOverridesPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
rntFullnameOverridesPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
roadAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
sameNameUnknownFieldMatchInterpolator | Fielded names | UNKNOWN_FIELD_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
staircaseAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
stateAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
stateDistrictAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
stopPatternsPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
stringDistanceWeight | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
stuckInitialAffixMinLength | All names | STUCK_INITIAL match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
stuckInitialScore | All names | STUCK_INITIAL match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
suburbAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
thresholdToDropoffBiasMapping | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
timeDistanceWeight | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
timeProximityYearInterval | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
tokenizeOrganizationsWithNumbers | Organization names | Affects tokenization and therefore any potential score | |||||||||||||||||||||||||||||||||||||||||||||||
tokenOverridesPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
trailingPatronymicDeletionScore | Person names | TRAILING_PATRONYMIC_DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
truncationFractionLimit | All names | TRUNCATED_EXACT_MATCH match phenomenon TRUNCATED_HMM_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
truncationScorerBias | All names | TRUNCATED_EXACT_MATCH match phenomenon TRUNCATED_HMM_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
tryAlternateTokenization | All names | Affects tokenization and therefore any potential score | |||||||||||||||||||||||||||||||||||||||||||||||
tryDayMonthSwap | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
unigramLMPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
unitAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
unknownFieldFrequencyRank | Fielded names | UNKNOWN_FIELD_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
unknownVsKnownScore | Fielded names | UNKNOWN_FIELD_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
unknownVsUnknownScore | Fielded names | UNKNOWN_FIELD_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
useEmbeddings | Organization names | EMBEDDING_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
useSolrPhraseQueries | Solr | Solr plugin setting | |||||||||||||||||||||||||||||||||||||||||||||||
variantOverrideScore | All names | OVERRIDE match phenomenon for tokens marked as VARIANT in the override file | |||||||||||||||||||||||||||||||||||||||||||||||
worldRegionAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
yearDistanceWeight | Dates | All date match scores | |||||||||||||||||||||||||||||||||||||||||||||||
[a] Concatenation occurs when adjacent tokens are joined together to see if the resulting compound token will be a good match for any tokens in the other name. [b] Gender mismatch occurs when the apparent or specified genders of the two names being compared do not match. [c] A digit manipulation is a transformation to a digit that can be accomplished with minimal additional lines. Digit manipulations may be intentional or the result of an OCR error. Our list of possible digit manipulations includes: 0↔8, 1↔7, 3↔8, 5↔8, 5↔6, 6↔8, 7↔2. [d] If the tokens in a name have been rotated, the reorder penalty will negatively impact the match score. RNI detects and compensates for this error. [e] Tokens that match, but that appear to be out-of-order, have their match scores adjusted to reflect that fact. | |||||||||||||||||||||||||||||||||||||||||||||||||
Internal parameters
This table lists the parameters that can be configured via internal_param_profiles.yaml. When applicable, each parameter has been linked to the specific match phenomena that it impacts. You can find more information on each parameter in internal_param_defs.yaml.
Important
We recommend against modifying these parameters unless advised to by Rosette support.
Name | Applies to | Impacts | |||||||||||||||||||||||||||||||||||||||||||||||
affixGlueThreshold[a] | All names and addresses | Concatenation[b] | |||||||||||||||||||||||||||||||||||||||||||||||
allLanguageSupport | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
allowCacheBonuses | All names | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
alwaysComputeSuffixes[a] | All names | TRUNCATED_EXACT_MATCH match phenomenon TRUNCATED_HMM_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
araRNISpeedOption | Translated names | Speed and accuracy tradeoff | |||||||||||||||||||||||||||||||||||||||||||||||
crossSurnameMatchPenalty | All names | Matches in languages with onomastic information | |||||||||||||||||||||||||||||||||||||||||||||||
debuggableIndex | N/A | Internal engineering detail Has no effect on matching | |||||||||||||||||||||||||||||||||||||||||||||||
debugPrintTuples | N/A | Internal engineering detail Has no effect on matching | |||||||||||||||||||||||||||||||||||||||||||||||
defaultScoreToCheckRestriction | All names Dates Addresses | First-pass scoring | |||||||||||||||||||||||||||||||||||||||||||||||
disabledLanguages | All names | ||||||||||||||||||||||||||||||||||||||||||||||||
doFrontTruncations | All names | TRUNCATED_EXACT_MATCH match phenomenon TRUNCATED_HMM_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryBigrams | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryCompleted | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryFullnameOverrides | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryFuzzy | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryGlued | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryIndexKeys | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryInitials | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryNormalized | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryPersonInitialisms | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryPhrase | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryRealWorldIds | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryTokenOverrides | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doQueryTranslated | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
doViterbiRescaling | All names | Fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
editDistanceTokenScorerPenalty | All names | STRING_SIMILARITY match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
embeddingBias | Organization names | EMBEDDING_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
embeddingZeroScore | Organization names | EMBEDDING_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
enableAdditionalOnomastics | All names | Matches in languages with onomastic information | |||||||||||||||||||||||||||||||||||||||||||||||
enableRemoteTokenScorer | All names | Japanese/English fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
enableSeq2SeqTokenScorer | All names | Japanese/English fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
enableTokenPairLogging | N/A | Internal engineering detail Has no effect on matching | |||||||||||||||||||||||||||||||||||||||||||||||
engEngFastMode | All names | English/English fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
expandedLanguages | All names | Fuzzy match[c] OVERRIDE match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
expansionLimit | All names | Fuzzy match[c] OVERRIDE match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
expansionScoreThreshold | All names | Fuzzy match[c] OVERRIDE match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
familiarTokenMismatchPenalty | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
familiarTokenThreshold | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
firstPassDayRange | Dates | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
firstPassMonthRange | Dates | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
firstPassYearRange | Dates | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
foreignAddressFinalBias | Addresses | All English-to-non-English address matches | |||||||||||||||||||||||||||||||||||||||||||||||
genderPenaltyMinimumLength | All names | Gender mismatch[d] | |||||||||||||||||||||||||||||||||||||||||||||||
givenFieldDeletionScore | Fielded names | DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
HMMCachePerProcess | All names | Internal engineering detail HMM_MATCH phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
HMMCachePerThread | All names | Internal engineering detail HMM_MATCH phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
hmmNormBias | All names | Internal engineering detail Fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
HMMUsageThreshold | All names | Internal engineering detail HMM_MATCH phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
identifierEditDistanceTokenScorerPenalty | Identifiers | STRING_SIMILARITY match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
ignoreTranslationOrigins | All names | Can affect any kind of match that uses English transliteration | |||||||||||||||||||||||||||||||||||||||||||||||
includeExtraKatakanaPersonReadings | Translated names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
initialAndSuffixMinLength | All names | Fuzzy match[c] INITIAL_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
initialAndSuffixScore | All names | Fuzzy match[c] INITIAL_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
jniBias | All names | Can affect any kind of match in languages that use a JNI scorer | |||||||||||||||||||||||||||||||||||||||||||||||
jpnRNISpeedOption | Translated names | Speed and accuracy tradeoff | |||||||||||||||||||||||||||||||||||||||||||||||
kanjiMismatchPenalty | All names | Normalization of tokens that include kanji | |||||||||||||||||||||||||||||||||||||||||||||||
katakanaTransliterationsOnly | Translated names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
korRNISpeedOption | Translated names | Speed and accuracy tradeoff | |||||||||||||||||||||||||||||||||||||||||||||||
latinDataAlternativesToCheck | All names | Can affect any kind of match where English transliterations are being used, and where there are multiple possible transliterations (e.g., Chinese/Japanese/Korean readings of Han names) | |||||||||||||||||||||||||||||||||||||||||||||||
limitedLanguageEditDistance | All names | STRING_SIMILARITY match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
maxIdentifierEditDistance | All names | First-pass accuracy | |||||||||||||||||||||||||||||||||||||||||||||||
notExactMatchPenalty | All names | Normalization | |||||||||||||||||||||||||||||||||||||||||||||||
_postCodePathAddressFieldWeight | Addresses | Weighting | |||||||||||||||||||||||||||||||||||||||||||||||
promisingFuzzyTermFrequencyFactor | Speed/Accuracy | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
promisingTermFrequencyFactor | Speed/Accuracy | Performance only | |||||||||||||||||||||||||||||||||||||||||||||||
queryMaxResults | All names Dates Addresses | First-pass scoring | |||||||||||||||||||||||||||||||||||||||||||||||
queryMaxToCheck | All names Dates Addresses | First-pass scoring | |||||||||||||||||||||||||||||||||||||||||||||||
queryMaxToConsider | All names Dates Addresses | First-pass scoring | |||||||||||||||||||||||||||||||||||||||||||||||
queryToCheckAllowance | All names Dates Addresses | First-pass scoring | |||||||||||||||||||||||||||||||||||||||||||||||
realWorldIdScore | Organization names | Real-world id match[e] | |||||||||||||||||||||||||||||||||||||||||||||||
remoteTokenScorerURL | All names | Internal engineering detail Japanese/English fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
rntTokenOverridesPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
rusRNISpeedOption | Translated names | Speed and accuracy tradeoff | |||||||||||||||||||||||||||||||||||||||||||||||
secondarySurnameTokenTypeWeight | All names | Matches in languages with onomastic information | |||||||||||||||||||||||||||||||||||||||||||||||
seq2seqCachePerProcess | All names | Internal engineering detail Japanese/English fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
seq2seqCachePerThread | All names | Internal engineering detail Japanese/English fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
seq2seqTokenOverridesPath | File locations | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
seq2seqUsageThreshold | All names | Internal engineering detail Japanese/English fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
splitTokens | All names | Internal engineering detail | |||||||||||||||||||||||||||||||||||||||||||||||
stringDistanceThreshold[a] | All names | Fuzzy match[c] | |||||||||||||||||||||||||||||||||||||||||||||||
surnameFieldDeletionScore | fielded names | DELETION match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
surnameTokenTypeWeight | All names | Matches in languages with onomastic information | |||||||||||||||||||||||||||||||||||||||||||||||
taggerMinimumConfidenceThreshold | All names | Matches in languages with onomastic information | |||||||||||||||||||||||||||||||||||||||||||||||
translatorResultsToKeep | translated names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
truncationAffixSimilarityLength | All names | TRUNCATED_EXACT_MATCH match phenomenon TRUNCATED_HMM_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
truncationAffixSimilarityThreshold | All names | TRUNCATED_EXACT_MATCH match phenomenon TRUNCATED_HMM_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
truncationLengthLimit | All names | TRUNCATED_EXACT_MATCH match phenomenon TRUNCATED_HMM_MATCH match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
useCharacterLM | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
useEditDistanceTokenScorer | All names | STRING_SIMILARITY match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
useIdentifierEditDistanceTokenScorer | Identifiers | STRING_SIMILARITY match phenomenon | |||||||||||||||||||||||||||||||||||||||||||||||
useLM | All names | Can affect any kind of match | |||||||||||||||||||||||||||||||||||||||||||||||
useOldAndNewNameSegmentationForJapanese | All names | Can affect any kind of match involving Japanese translations | |||||||||||||||||||||||||||||||||||||||||||||||
useRealWorldIds | all names (or just orgs?) | Real-world id match[e] | |||||||||||||||||||||||||||||||||||||||||||||||
zhoRNISpeedOption | Translated names | Speed and accuracy tradeoff | |||||||||||||||||||||||||||||||||||||||||||||||
[a] Unlike public parameters for this feature, this is a speed/accuracy tradeoff, not a science-tuning parameter. [b] Concatenation occurs when adjacent tokens are joined together to see if the resulting compound token will be a good match for any tokens in the other name. [c] A fuzzy match is a match between tokens that are similar but not identical. The HMM_MATCH and SEQ2SEQ_MATCH phenomena are examples of this. [d] Gender mismatch occurs when the apparent or specified genders of the two names being compared do not match. [e] RNI contains real world identifiers for corporations, which pair an entity id with nicknames and common permutations of the corporation name | |||||||||||||||||||||||||||||||||||||||||||||||||
Directory structure
While not exhaustive, this appendix briefly describes and details the location of parts of RNI-RNT that developers may need to access. Any directories not described in this appendix, such as those containing internally used compiled code referenced by other parts of the product, will not need to be accessed by most developers.
BT_ROOT directory
BT_ROOT is the Basis Root directory. This is the high-level structure of an RNI-RNT installation. As a developer, you will not need to access most of these files and folders. Some files and folders of note are listed below. For more information on this directory, see Setting the Basis root directory.
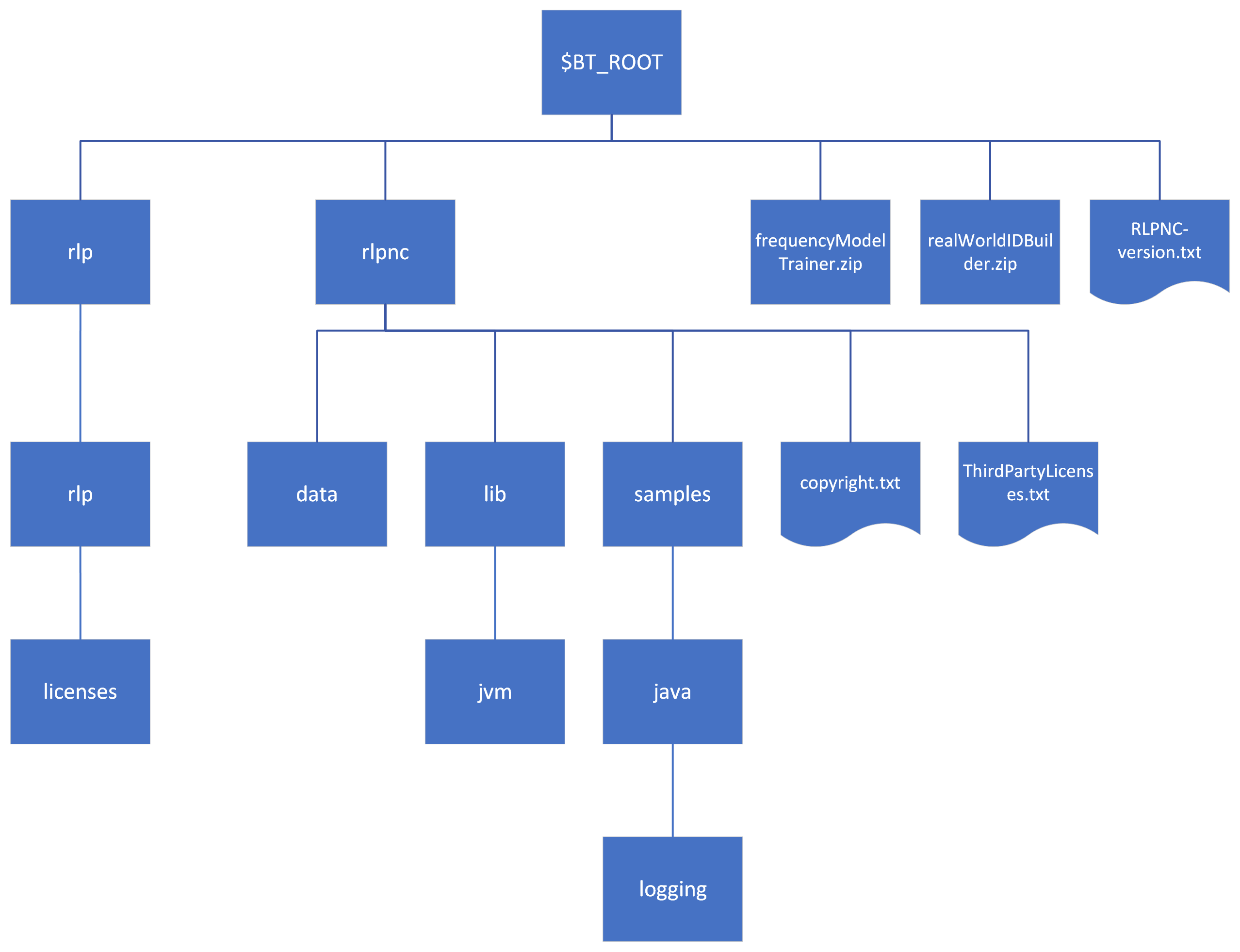
| This is where you should copy the license file included in your product shipment. |
| Library of jar files you may need to include on your classpath for logging purposes or when building and running RNI-RNT applications. |
| Source files for sample applications and the Ant build file for compiling and running them ( |
| Contains a copy of |
| Copyright information. |
| Information on the third party components included in the software. |
| Use this to train a language model on your own name data. Instructions and a full description of arguments are in the |
| Use this to build a real world ID binary file. Instructions on how to run the program are in the |
| A text file containing the version number. |
data directory
This is the low-level structure of the $BT_ROOT\rlpnc\data folder. As a developer, most of the files you will need to access are contained in this folder. File paths and descriptions of important files and folders are included below.
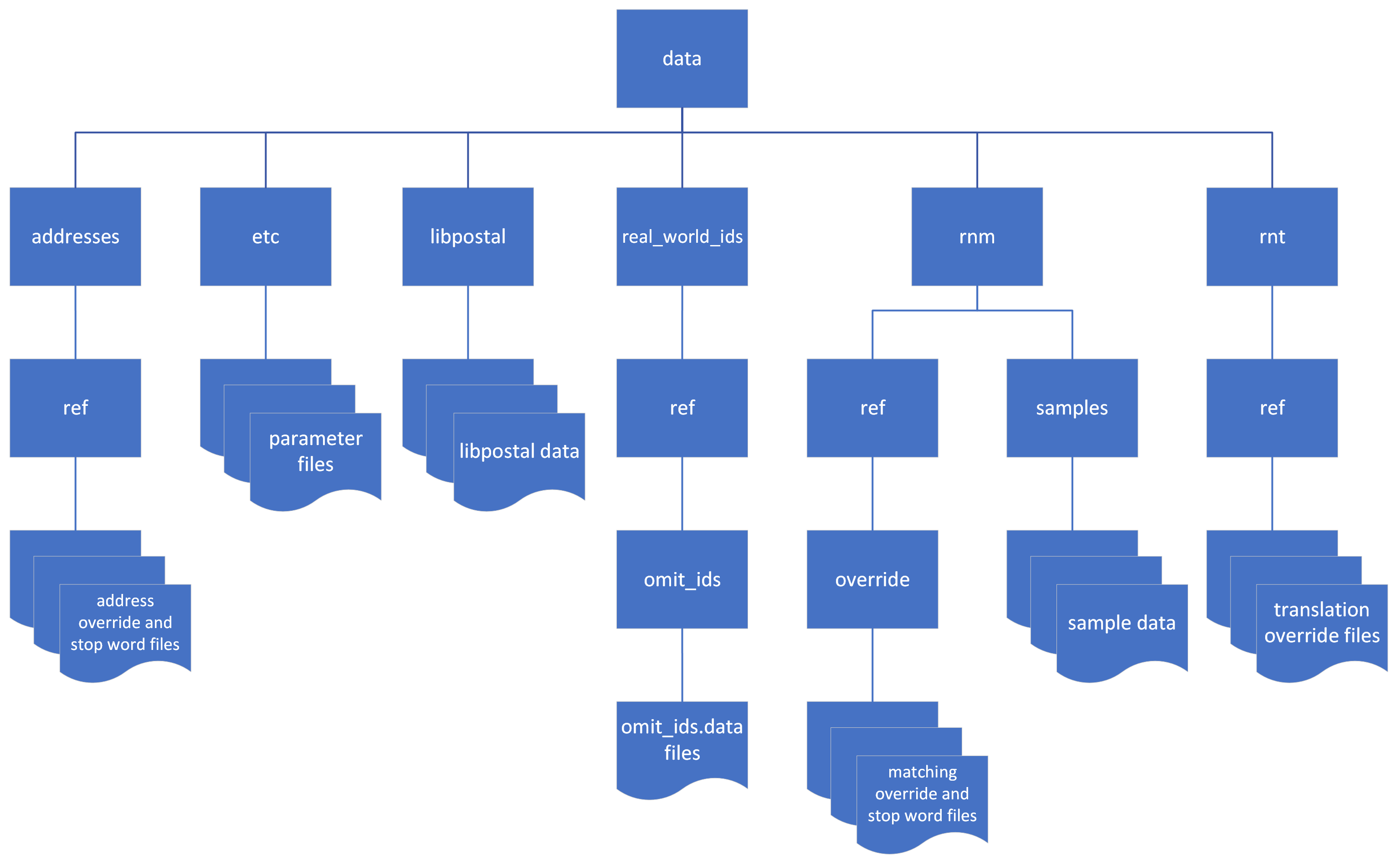
| Override and stop word files for matching addresses. |
| Files pertaining to match parameters. The parameters are defined in |
| Data for libpostal, a C library for parsing/normalizing street addresses around the world using statistical NLP and open data. If you are certain that you won't be utilizing address matching of unfielded addresses, you can safely delete the libpostal data directory without impacting any other RNI-RNT functionalities. |
| Contains |
| Files for name matching overrides, stop patterns, stop word prefixes, normalizing token variants, and unimportant tokens. |
| Sample data for name matching. |
| Name translation override files. |
[8] # may also be used after an entry on the same line to begin a comment.
[9] Override files are not provided for all supported languages. Specifically, while no files are provided for Russian or Korean, you can create token pair files for these languages.
[10] Language of use, the language of the document in which the name appears
[11] RNI depends on the jpostal binding for the open source libpostal library to parse unfielded addresses as a pre-processing step. Though jpostal is not officially supported on Windows, our tests have shown it to function as expected. Please contact support@basistech.com if you discover any issues.
[12] # may also be used after an entry on the same line to begin a comment.
[13] # may also be used after an entry on the same line to begin a comment.
[14] RNI depends on the jpostal binding for the open source libpostal library to parse unfielded addresses as a pre-processing step. Though jpostal is not officially supported on Windows, our tests have shown it to function as expected. Please contact support@basistech.com if you discover any issues.
[15] Hebrew orthographic completion occurs automatically; it is not controlled by this option.
[16] Arabic, Burmese, Khmer, and Thai segmentation occurs automatically; they are not controlled by this option.