Developing Models
Developing models with Babel Street Analytics
This guide provides a methodology and processes for gathering data and training custom entity and event extraction models for use with Analytics Server.
Training models for named entity recognition
Entities are the key actors in your text data: the organizations, people, locations, products, and dates mentioned in documents.
An entity model is trained to extract a set of entity types. Before starting any type of entity recognition project, you must identify the entity types you want to extract.
Each named entity extraction project in Adaptation Studio results in a model trained by the Entity Training Server (EnTS). As the training samples in the project are annotated, the annotated data is sent to Entity Training Server to train the model. The training server can train multiple models simultaneously and support multiple projects concurrently.
The current status of the model being trained is displayed in the Manage page.
NER model training lifecycle
Documents are uploaded into Adaptation Studio. Documents are stored in the database.
Unsupervised training
Word classes are automatically generated as a background task.
Supervised training
Samples in the training set are annotated and adjudicated (can be auto-adjudicated).
The training server receives the annotations as the adjudicated samples are available, and trains a new version of the model. This model is held in memory.
The trained model is written out to disk. This process can take a few minutes. While this occurs, suggestions will come from the newly trained model in memory.
Training is complete.
Suggestions are provided by the model on disk.
The model can be deployed to another machine through the Export Model task. Exporting a model has no impact on training or training resources. Export Model is only enabled after all components have completed all training tasks.
Supervised training is repeated as additional samples are annotated and adjudicated.
Model management and caching
Model Training Suite includes a robust model management system, including a cache to manage multiple models and support model permanence across restarts. Be aware that training a new model takes several minutes. If the server shuts down before writing the model to disk, the current in-memory models are lost, but will be retrained when the training server is restarted.
When there is no annotation occurring, the model is not being trained. After a period of inactivity an inactive model is evicted from the Entity Training Server, freeing up memory. The model will be automatically reloaded once training resumes.
Unsupervised vs supervised training
Adaptation Studio uses two types of training for entity extraction:
Unsupervised training: Unsupervised training uses a clustering algorithm to create word classes from uploaded documents. It doesn't require any input from the user.
Supervised training: Supervised training uses annotated text to train models.
The major benefit of unsupervised training is that the process does not require the human-intensive effort to annotate example data. The model will discover entities using the context of words within the plain text input. It will generate groupings of words that appear in similar contexts and assign them to the same cluster, like "Boston", "Texas", and "France". The model then uses that cluster information to extract entities from your input.
However, if your domain is different from the default training domain or you are extracting new entity labels, you will need to use supervised training.
Ideally, the model is trained on both word classes and annotated text. The supervised training algorithm uses the word classes as well as the annotated data as input.
Unsupervised training
Unsupervised training evaluates a corpus of data and extracts word classes which are then used when training the model. The advantage of unsupervised training is that it doesn't require annotating large amounts of data, a resource-intensive process. Unsupervised training works best with a large amount of data; a minimum of 100 MB is recommended though a few GB is better.
Model Training Suite automatically performs unsupervised training and generates word classes when you upload documents into the system. To get the greatest impact from unsupervised training you should upload a large corpus of data at once. You do not have to annotate all the uploaded samples. Because generating word classes is a time-consuming task, ranging from a few hours for 100 MB to a few days for a few GB of data, we recommend uploading the documents a couple of days in advance of starting your annotation process.
Creating word classes
Documents are uploaded into the system.
Using Babel Street Base Linguistics, the input is broken into sentences, tokenized, and normalized to generate the normalized form for each input token.
The system scans the normalized input to calculate the distribution of unigram and bigrams.
Using the n-gram distributions, the system applies a clustering algorithm to determine the correlation between n-grams.
The system creates the final word classes. The algorithm groups up to one thousand words into a word class to yield the optimal extraction accuracy.
Supervised training
Supervised training uses annotated documents to train the model. Supervised training is useful when the target domain is significantly different from the default BasisTech training domain (news stories) and when training a model to extract new entity types (labels).
Babel Street Entity Extractor is shipped with a fully trained statistical model. The default model is trained on annotated news documents. You can improve the extraction of the default entity types by customizing this statistical model with more annotated data. The greater the difference between your domain and the default Entity Extractor domain, the larger the impact in the results.
When training your new model, you can choose to supplement the annotations from the Studio with the data that was used to train the default statistical model. This is recommended when training a model using the same labels as the default labels. Select Use Basis Training Data when you create the model. This will include the training data used to train the statistical model shipped with Entity Extractor.
If you choose to Use Basis Training Data you can only train on the default training labels. You cannot add new labels for annotation and training.
Note
The time to train the model when Use Basis training data is enabled may be a few minutes longer than without the extra training data. The time is determined by the number of annotated documents as well as the language.
If this option is not selected, the model will be trained exclusively on the adjudicated annotation data provided by the Studio. This is required when there is at least one label that is not one of the standard Entity Extractor entity types.
Models from multiple domains
The most effective machine learning models are domain-specific because general models don't perform well on specific domains. For example, if you want to analyze tweets, you would want to train a model on tweets. If you also want to analyze financial data, you would train another model on financial data.
To extract entity types that are not part of the default Entity Extractor, train a new model using additional labels. For example, if your application has domain-specific types, or the terminology and usage is distinct, collect separate data corpora from each domain and train separate models for each domain. One example could be legal terms vs. medical terms. In this example, in Adaptation Studio you would create a new project for each domain and define the labels (entity types) for the domain. Each project will train its own separate domain-specific statistical model with its own set of entity types.
When annotating documents, the documents should be assigned to annotators based on the domain. This can be automated by evaluating the metadata (for example, the document source) or by a classifier that is trained to detect domains.
Multiple models can be deployed in Analytics Server. We call it model mixing when using a statistical model alongside the Entity Extractor standard models, to extract entities. With model mixing, the models are run in parallel. The default model can be mixed with a domain-specific model because it is trained on a corpus that contains well-edited text in a relatively generic domain. If the specific domain does not contain well-edited texts, for example tweets or other social media sources, the default model should be turned off as it is likely to generate noisy results.
We don't recommend applying more than two models to process a single document, where the two models are the default Entity Extractor model and a domain-specific model. Trying to process medical documents with multiple models, such as the default model + medical domain model + legal domain model will lead to noisy results, i.e. false positives, from the legal domain model.
In Analytics Server, use custom profiles to route users to the correct models. Custom profiles support a single Analytics Server instance with different data domains for each user group. One profile may use the standard model alongside the legal terms model, while another profile uses the medical terms model along with the Entity Extractor model.
Models to extract new entity types
Entity Extractor is shipped with a statistical model that extracts a set of default labels. There are times you may have the choice of using an existing entity type or creating a new entity type for a particular type of entity.
For example, let's assume we are training a model to extract computer hardware, such as specific mentions of graphics cards, routers, and other computer hardware. These could be extracted as product, which is a default label in some languages. Or, you could decide that your business requires the mentions to be extracted as equipment. To extract as product mentions, you can use the Basis Training Data and extend the existing Entity Extractor statistical model. To extract as equipment mentions, you are adding a new label and must not use the Basis Training Data.
Multilingual models
Similar to the issue of multiple domains, Babel Street Analytics handles multilingual scenarios by applying language-specific models to different languages. Before applying any language-specific models, Analytics uses a language classifier to identify the language and script of a document, and then applies language/script-specific models based on the document’s classification. A model trained on English text is not expected to perform adequately on Spanish text, much less on a language such as Arabic which is topologically even more different from English than Spanish is, and uses a different orthographic system.
In Adaptation Studio create a separate project for each language. A language-specific model is then trained for each language. If you have multiple domains and languages, create a project for each domain-language pair.
Case-sensitive vs case-insensitive models
Models may be built to be case-sensitive or case-insensitive. This refers to the capitalization (aka 'case') of the input texts.
Case-sensitive models are most appropriate for well-formed text where case is an informative model feature.
Case-insensitive models are most appropriate for text with no or imprecise casing, for example, tweets, all-caps, no-caps, or text with headline capitalization.
Case-sensitive models are only available for English in Model Training Suite.
We recommend splitting your corpus into case-sensitive and case-insensitive documents. At project creation, the option Train Case Sensitive Model is checked by default. If training a case-insensitive model, remove the checkmark. You will train two separate models, one for each input type.
If you don't have enough annotated documents to split the corpus, but you have headlines and body components (the first being case-insensitive, the body case-sensitive), you can train case-sensitive and case-insensitive models on the same corpus. At runtime, you will have to split the input documents into their separate components and process each part of the document with a different model.
When the model is deployed in production, set the caseSensitivity parameter to automatic in the rex-factory-config.yaml file in Analytics Server to let Entity Extractor decide which model to use at run time.
Training models for event extraction
An event is a dynamic situation that unfolds. Most events describe an interaction or relationship between objects. A span within a document that refers to a single event is an event mention. Sample event mentions include:
A meeting between two people at a particular place and time.
Joe and Jane met at the park last Thursday.
A troop movement to a location.
Special Forces arrived in Baghdad in an armored personnel carrier.
A trip taken by an individual from one location to another location.
Bob flew from Boston to Los Angeles.
An event model is trained to extract specific types of event mentions. Before starting any type of event recognition project, you must identify the types of event mentions you want to extract and then define the structure or schema of each event type. Plan on spending a good amount of time and effort defining your event types and the schema for each type before beginning a project.
Once the schema is defined, use Adaptation Studio to annotate documents containing event mentions to train an events model. Event mentions in text have multiple components with nuanced relationships to each other, making annotating events much more complex than annotating for named entity recognition and extraction.
Tutorial
Event modeling can be complex. To help you learn about event modeling, look for tutorials on our support site. Events tutorials guide you through creating a schema and annotating data. They include sample data and basic annotation guidelines.
Event extraction model training lifecycle
Model your domain. Define the ontology of event mentions, event types, and roles you are interested in extracting.
Define the schema to model the ontology.
Load the schema.
Load training documents.
Annotate documents. As you annotate each training document, the model is trained.
Event extraction objects
Event recognition analyzes unstructured text and extracts event mentions. When extracting event mentions from text, each mention is of a specific, pre-defined type. Each type has a schema which specifies the details, including key phrases and roles, that characterize the event type. Each key phrase and role uses extractors to define how the object is extracted from the text.
Event types
The first task in defining your event schema is defining the set of event types you want to recognize. When extracting events, you don't extract all possible event types; you only extract the event types of interest. It's important to recognize which sorts of events are significant and will be mentioned frequently in your domain. Consider the set of entities and events that are going to be mentioned in the documents you will be analyzing. The goal is to train a model to extract only the event types that are meaningful to your operation.
For example, if you're analyzing financial documents, bankrupting and acquiring events will be of interest, but flying or battle events would not be of interest. If, however, you're analyzing travel blogs, recognizing flying events may be important. Alternatively, if you're analyzing military reports, flying and battle events may be relevant.
Let's consider a project that tracks troop movements and battles between military units: troop_movement and battle may be the only two event types you need.
You could make these event types more granular (e.g. aerial_battle, tank_battle, etc.), but a larger number of possible event types will result in a smaller number of training examples for each type. This will make it more difficult for a machine learning classifier to learn the patterns. A better solution might be to have a more generic event type (like battle) that captures more fine-grained distinctions with roles such as mode_of_battle indicating the concepts aerial, tank, or artillery. In general, you should try to create as few event types as possible to extract the information you’re really interested in.
Key phrases
Each event type has one or more key phrases, a word in the text that evokes the given event type. Event extractor uses key phrases to identify candidate event mentions from the text.
Let's consider the troop_movement example. If you were reading a document, what words would you look for to indicate that it was discussing troop movements? Drove, flew, took off, landed, arrived, moved are all potential key phrases.
Looking at the keyword flew in more detail, what about other tenses of the word flew? Words like flying, fly, flies. You don't want to have to list every possible version of the word.
Adaptation Studio identifies candidate keywords in your documents by using an extractor. For key phrases, the extractor will look for the exact words or the lemmas of the words you define.
Adaptation Studio uses the candidate key phrase to identify event types in the text.
Roles
Event mentions include more objects than the key phrase. These other objects are usually entity mentions, i.e. people, places, times, and other mentions which add detail to the key phrase. For a flying event, with a key phrase of flew, you may want to know who flew? Where did they go? When did they go? What kind of aircraft did they fly on? The people, locations, times, and aircraft are all entity mentions that have roles.
Roles detail how the entity mention relates to the event. They answer the questions: What does this entity do in the event? What role does it play?
Let's look at a troop_movement event. What types of entities might we expect to find? What types of roles? Some possible roles include:
Mover: the people or organization moving
Origin: where the trip originates
Destination: where the trip ends
Mode of transportation: the vehicle used in the movement
Date: the date of the movement
There may be more roles in an entity mention than you are interested in capturing. For example, let's assume you want to know who flew, but you don't care about when they flew. You would define the role of traveler, but would not define a role for date or time. Part of defining the schema for an event model is determining which roles are important to your organization and task.
Roles are generic categories, such as traveler, origin, and destination, When annotating event mentions, you tag extracted entities with the role they perform in the entity mention. Extractors define the rules used to extract role candidates from text.
Required roles
A role can be required or optional. If required, an event mention will not be extracted without the role. You should only mark a role as required if it must always be in the event mention. Let's look at some examples for a flight scenario.
Bob flew from Boston to Los Angeles on Wednesday.
The key phrase and roles are:
Key phrase: flew
Roles: origin, destination, when
Let's assume the destination is marked as required in the schema definition. In this case, only one of the following event mentions will be extracted.
Bob flew to Los Angeles.
Bob's flew from Boston on Wednesday.
The second event mention will not be extracted, since it does not contain the required role, even if it is annotated.
Determining events and key phrases
It can be difficult to define when you need to separate the events you are trying to extract into different event types. Some events might be very similar, but the roles in the event have different perspectives to the key phrase. In this case, you will want to create separate event types. Otherwise, the model may have difficulty determining the correct roles.
For example, let's consider a Commerce event for buying and selling show tickets. One way to model this would be to create a purchase event that includes both buying and selling.
Event: commerce event
Key Phrases: buy, obtain, sell, distribute
Roles: buyer, seller, show
Let's consider a couple of events:
James[buyer] bought a ticket from Ticketmaster[seller] to see Les Mis[show].
James[seller] sold his ticket to Les Mis[show] to Jane[buyer].
In these examples, the model will have difficulty identifying correctly the buyer and the seller if they are the same event type. The event model cannot distinguish the different perspectives the roles may have based on the key phrase; all key phrases in a single event type are expected to have the same relationship to the roles.
Therefore, we strongly recommend that when key phrases have different relationships to the roles, they should be separated into separate event types.
Event: buying event
Key Phrases: buy, obtain
Roles: buyer, seller, show
Event: selling event
Key Phrases: sell, distribute
Roles: buyer, seller, show
A similar example would be the events entering and exiting. While they may have the same roles (person, from location, to location, time), the perspective of the person to the locations is different for each key phrase.
Extractors
Model Training Suite has multiple techniques to identify candidate key phrases and roles in text. For example, it can match a list of words, or it can match all the lemmas for a given word. Using Entity Extractor, it can identify entity mentions of specific entity types. Extractors define the rules and techniques used to identify role and key phrase candidates in the text. While any extractor type can be used to define roles, only morphological extractors can be used to identify key phrase candidates.
Once defined, extractors are reusable in multiple schemas. An extractor named location may be defined as the standard entity type Location. It could be used in troop_movement events as well as travel events, as each of them have roles involving locations.
The currently supported extractor types are:
Entity: A list of entity types. You can use the standard, pre-defined entity types or train a custom model to extract other entity types. The custom model must be loaded in Server to define an entity extractor with custom entity types.
Semantic: A list of words or phrases. Any word whose meaning is similar to one of these words will match. For example, an extractor of meeting will match assembly, gathering, conclave. Word vector similarity is used to identify similar words. While a semantic extractor can be defined by a phrase, it will only identify single words as candidate roles.
Morphological: A list of words. When a word is added to this list, it is immediately converted to and stored as its lemma. Words with the same lemmatization will match. For example, a morphological extractor for go will match going, went, goes, gone.This is the only extractor type valid for key phrases.
Exact: a list of words or phrases. Exact will match any words on the list, whether they are identified as entity types or not. For example, you could have a list of common modes of transportation, including armored personnel carrier and specific types of tanks.
Custom entity extractors
Event extraction takes advantage of the advanced entity extraction capabilities provided by Entity Extractor. Entity Extractor uses pre-trained statistical models to extract the following entity types:
Location
Organization
Person
Title
Product
You can also use custom-trained entity extraction models, trained by the Model Training Suite, to extract additional entity types. These models are loaded into Analytics Server. They can be called in the default configuration or through a custom profile.
Entity Extractor also includes rule-based extractors, including statistical regex extractors that can extract additional entity types such as:
Date
Time
Credit Card numbers
Phone Numbers
The rule-based extractors are not returned by default, To use rule-based extractors, modify the supplementalRegularExpressionPaths in the configuration (rex-factory-config.yaml) file. You can also add custom regex files to create new exact extractors.
Note
Any models, gazetteers, and regular expressions used when training a model must also be used when performing event extraction. Use the same custom profile to configure Entity Extractor for model training and event extraction. The custom profile is set in the schema definition for event model training.
Role types
Role types define the rules that are used to identify a piece of text as a candidate for a specific role or key phrase. A role type is made up of one or more extractors and is reusable.
Multiple extractors can be included in a role type definition. They are combined as a union - all possible candidates extracted are included.
This definition matches any Entity Extractor location, one synonym for New York City, or any words with meanings similar to city or state.
{entities: [LOC], exact: ["the big apple"], semantic: ["city", "state"]} 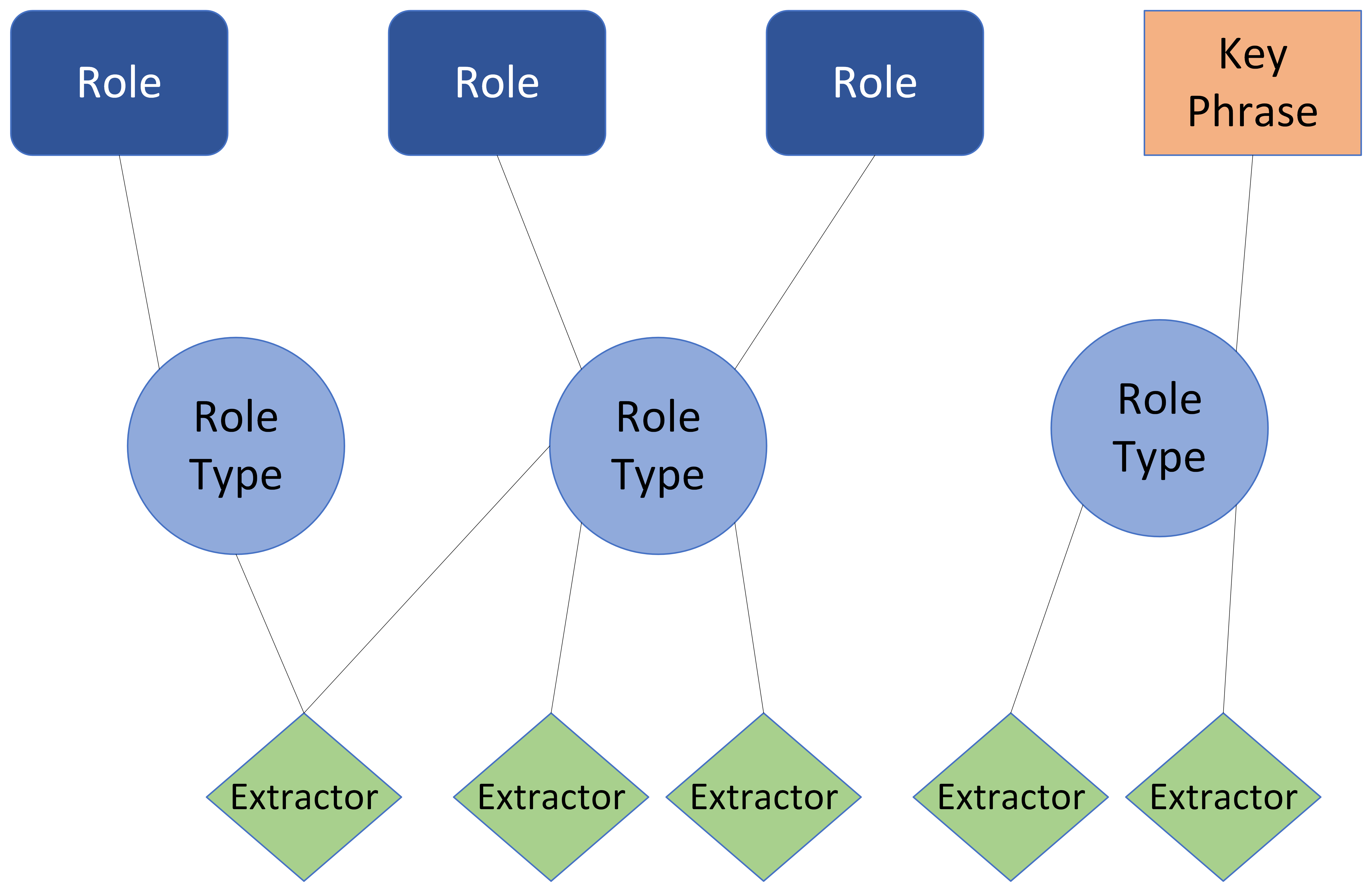
Let's look at another example. Let's say we want to identify the movers in the troop movement schema. What are potential movers?
People: Any entity extracted as a person. This could be defined as an entity extractor named person-entity.
Groups: Specific troop organizations, such as special forces or battalion or squad. This could be defined as an exact extractor, a list of terms you've identified as groups that are movers. Let's call this extractor troop_groups.
The movers role type would include both the person-entity and troop_groups extractors. The mover role would have the role type of movers. This role type could be used by other roles as well.
Role types are also used to define the rules for extracting key phrase candidates. How would we extract the key phrases for the troop movement schema? What are some key phrases we could be looking for? Words such as fly, drive, and move are all potential key phrases. We would also want other tenses and versions of those words. For example, given move, we would also want to extract moved, moves, moving.
You could define a single morphological extractor move-morphological-key that lists the specific words and specifies that all lemmas for the words are also matches. The troop_movement_key role type would use the move-morphological-key extractor.
"name": "move-morphological-key",
"kind": "morphological",
"items": [
{"surface-form": "march"
},
{"surface-form": "fly"
},
{"surface-form": "drive"
},
{"surface-form": "traverse"
},
{"surface-form": "move"
}
]Role types are generic categories, while role mentions are specific instances of those categories. Extractors define the specific rules to extract the role candidates. Extractors are combined into role types.
Modeling your domain
The events schema describes the events and roles you want to extract. Defining an ontology of event types and roles, along with the extractors that will find the events and roles in the text, is a complex and difficult task. It must be complete and accurate before you start training models. Semantic frames are one type of structured representation of a situation involving various participants and roles, such as an event. Existing resources which define semantic frames can be helpful in identifying and describing your event schema.
Let's consider a system that tracks troop movements and battles between military units. In this case, TROOP_MOVEMENT and BATTLE may be the only two event types necessary.
You could make these event types more granular (e.g. aerial_battle, tank_battle, etc.), but a larger number of possible event types will result in a smaller number of training examples for each type. This will make it more difficult for a machine learning classifier to learn the patterns. A better solution might be to have a more generic event type (like battle) that captures more fine-grained distinctions with roles such as mode_of_battle indicating the concepts aerial, tank, or artillery. In general, you should try to create as few event types as possible to extract the information you’re really interested in.
Once you have selected an event type, try writing a general description of what you want to extract for the event type. Think about the most basic elements of events of that type and how they relate to each other. The goal is to be able to describe the event in a way that generalizes all the possible event mentions that you will want to extract.
In a TROOP_MOVEMENT event, one or more soldiers (MOVER) move from one location (ORIGIN) to another (DESTINATION), possibly in some sort of vehicle (MODE_OF_TRANSPORTATION).
Defining an ontology of event types and role relations that is consistent and extends to all possible cases is very challenging. We strongly recommend you research existing resources, such as FrameNet, before trying to build something from scratch. It is possible that an ontology specific to your domain is already available somewhere. You can also use the existing event types in an ontology like FrameNet as an inspiration to design your own event types, as well as a verification check for the scheme you define.
Resources for modeling your domain
When modeling events for annotating in English, it may be helpful to rely on existing resources, such as the semantic frames proposed by FrameNet. A semantic frame is a sort of prototype for a situation, and the English FrameNet provides a dictionary of semantic frames and annotated examples. Some semantic frames and their constituent frame elements may align well with your concept of an event type and its roles.
If we look at the description of the “Motion” frame in FrameNet, we observe something fairly similar to what we came up with for TROOP_MOVEMENT:
Some entity (Theme) starts out in one place (Source) and ends up in some other place (Goal), having covered some space between the two (Path). Alternatively, the Area or Direction in which the Theme moves or the Distance of the movement may be mentioned.
The Motion frame describes more general movement events, not just troop movements, so obviously there is no mention of soldiers. But apart from this, there is a clear correspondence between many of them.
Source: ORIGIN
Goal: DESTINATION
FrameNet uses terminology from the linguistic field of semantic role labeling, but you are free to name your role relations whatever is most descriptive and intuitive for developers and annotators.
You’ll also notice that Motion has more role types than TROOP_MOVEMENT (Path, Area, Direction, Distance). These may give you ideas for roles that you haven’t considered, but might be useful for your application. On the other hand, some of these roles are optional and appear very infrequently, which makes them difficult for a machine learning model to learn; this is exacerbated by the fact that some roles apply to long spans of text with complex grammatical constructions. We recommend keeping your list of roles as short and simple as possible to model the information you need, while ensuring that there are many examples of each role in the data you annotate.
Tip
If you can’t find anything in FrameNet that aligns with your description of an event type and roles, that’s an indication that the event type may be ill-defined.
Defining the event schema
Once you have a list of event types, create the schema for each event type. The event schema defines the objects that define an event type.
For each event type define the key phrases and roles that are important to your organization and the event extraction task you are performing.
The role type for the key phrase is defined with a morphological extractor on all key words.
For each role, define how to extract candidates, by defining the role types for the role. The role type definition consists of one or more extractors.
Note
Role types and extractors are generalized, reusable objects. They do not have to be defined in the same schema as the key phrases and roles which use them.
Events: troop_movement
Key Phrases: march, fly, drive, traverse, move
Roles: mover, mode_of_transportation, origin, destination
Role Types: location, transportation, person, movers, troop_movement_key
Extractors: location-entity, person-entity, person-semantic, troop-groups, vehicles, move-morphological-key
Troop movement schema example
A schema can be represented in a json file format.
{
"version":"1.0.0",
"name": "troop_movement",
"eventTypes": [
{
"name": "troop_movement",
"keys": [
{
"name":"key"
"roleType:"troop_movement_key"
}
]
"roles": [
{
"name": "mover",
"roleType": "movers",
"cardinality": "required",
},
{
"name": "origin",
"roleType": "location",
"cardinality": "optional",
},
{
"name": "destination",
"roleType": "location",
"cardinality": "optional",
},
{
"name": "mode_of_transportation",
"roleType": "transportation",
"cardinality": "optional",
}
]
}],"roleTypes": [
{
"name": "location",
"extractors": [
"location-entity"
]},
{
"name": "person",
"extractors": [
"person-entity",
"person-semantic"
]},
{
"name": "movers",
"extractors": [
"person-entity",
"troop_groups"
]},
{
"name": "transportation",
"extractors": [
"vehicles"
]},
{
"name": "troop_movement_key",
"extractors": [
"move-morphological-key"
]}
],"extractors": [
{
"name": "person-entity",
"kind": "entity",
"types": ["PERSON"]
},
{
"name": "person-semantic",
"kind": "semantic",
"items": ["person", "people"]
},
{"name": "location-entity",
"kind": "entity",
"types": ["LOCATION"]
},
{
"name": "troop_groups",
"kind": "exact",
"items": ["special forces", "battalion", "squad"]
},
{
"name": "vehicles",
"kind": "semantic",
"items": []},
{
"name": "move-morphological-key",
"kind": "morphological",
"items": [
{"surface-form": "march"
},
{"surface-form": "fly"
},
{"surface-form": "drive"
},
{"surface-form": "traverse"
},
{"surface-form": "move"
}
]
}
] Annotating event mentions
To train a model to extract event mentions, you annotate documents, identifying the key phrases and roles in the event mentions.
The rules defined in the extractors identify key phrase candidates in the text. The key phrase indicates what event type the mention is.
Once the sample is identified as a specific event type, the extractors for the role types will identify candidate role mentions.
The annotator accepts or modifies candidates.
Once completed, the event mention is used as training data.
Event mention example
Let's look at the troop movement event Special Forces arrived in Baghdad in an armored personnel carrier.
The key phrase is arrived. This is the word which tells you the event type is a travel event.
The entities of interest within the event are: Special Forces, Baghdad, and armored personnel carrier. What roles do they play?
Special Forces is the mover.
Baghdad is the destination of the movement.
Armored personnel carrier is the mode_of_transportation.
Mover, destination, and mode_of_transportation are roles which are defined as part of the troop_movement event.