Entity Extractor
Introduction
Overview
Entities are the key actors in your text data: the organizations, people, locations, products, and dates mentioned in documents. Babel Street Analytics uncovers these entities, delivering structure, clarity, and insight to your data with adaptability, easy deployment, and consistent accuracy and performance across a broad range of languages and text genres.
Entity Extractor (Entity Extractor) ingests text and identifies people, locations, and organizations, in addition to many other entity types including product, date/time, URL, and email. These entities can be used to add structured metadata to a document or in downstream natural language processing (NLP) tasks, such as extracting themes and ideas, sentiment analysis, and relationship extraction.
Entity Extractor is deployed in Analytics Server as the /entities endpoint.
Entity Extraction Entity Extractor comes with multiple entity extraction processors along with a linker processor to link entities to a knowledge base. In case of conflicting entities, a redactor decides which entity extraction result “wins.” Entity Extractor has extensive customization features, including adding new entity patterns to the pattern-matching processor and new entity lists to the exact match processor. You can add a custom processor to systematically process Entity Extractor results. Numerous configuration settings let you fit Entity Extractor to your specific use case.
Entity Linking Entity Extractor has an entity linking processor which can identify the real-world entities extracted from the text as well as disambiguating between different entities with the same name. Entity linking can determine not only that "Tim Cook" is a person, but it can also determine who "Tim Cook" is and disambiguate between multiple possibilities. For example, is he the CEO of Apple or a political science scholar? The entity linking processor looks at the context of each extracted entity to link entities against Wikidata. Entity Extractor supports linking to other public knowledge bases as well as your organization's custom knowledge bases.
Adaptation & Customization Entity Extractor gives you a good start, but as with any natural language processor, you will need to configure and adapt Entity Extractor to your specific task for best results. Model Training Suite allows you to train a model on your domain-specific data or to add new entity types to the statistical model.
The statistical model is context-sensitive, meaning it identifies entities based on the context it appears in and thus can find names of people even if the name has been misspelled. It can also be trained on data that is more representative of your business case. Contact your sales representative or analyticssupport@babelstreet.com for more information on Model Training Suite.
Architecture
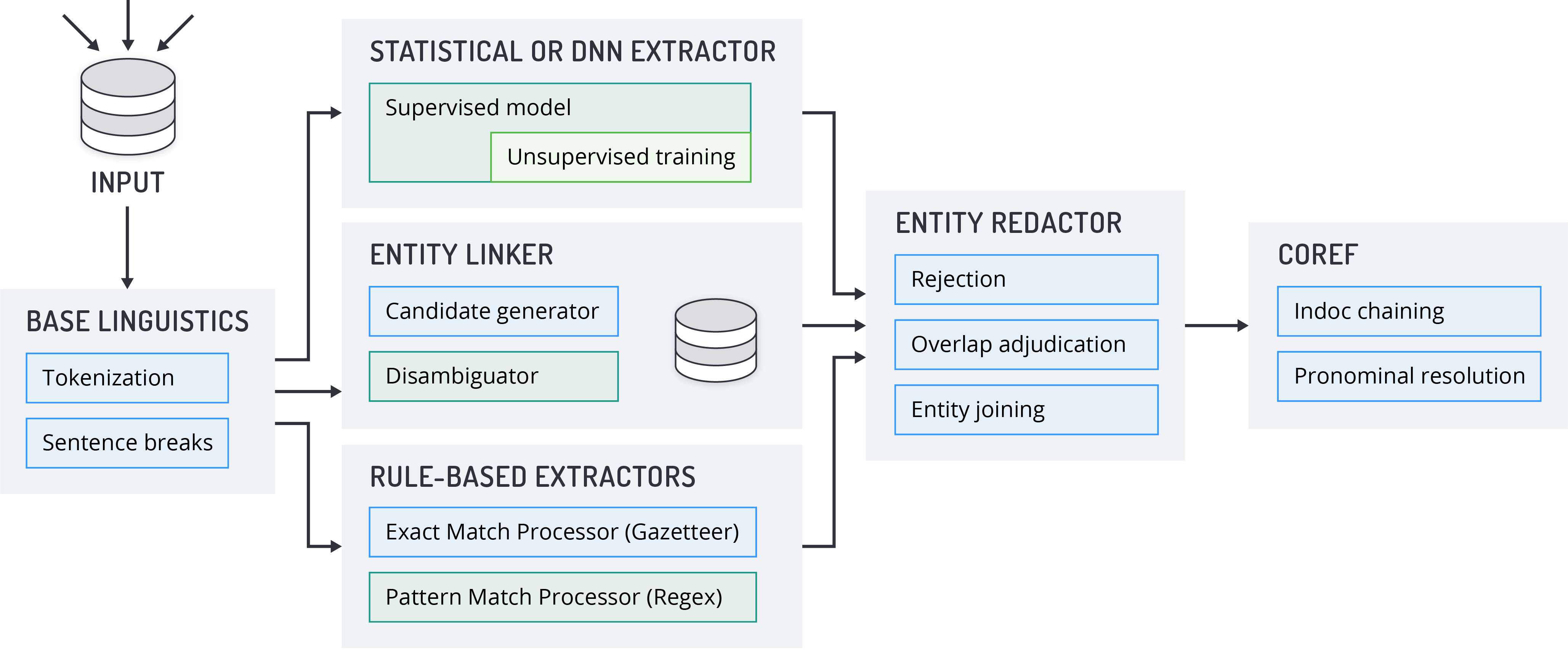
Basic Entity Extraction with Entity Extractor:
Using Babel Street Base Linguistics, Entity Extractor processes plain text input into sentences and tokens.
Entities are extracted by running the tokens through the statistical processor or DNN, regexes, and gazetteers. If the linker is enabled, the tokens are also run through the linker processor to link entities to a knowledge base.
Reject regexes and gazetteers may remove entities from the output. Some adjacent entities may be combined by the joiner into a single result. The final entities are selected by running the extractor results through the redactor.
The final extracted entities are returned as output.
Processors for entity extraction
Entity Extractor uses multiple complementary methods to identify entity mentions in the input text: statistical models, pattern matching, and exact matching. With Entity Extractor version 7.32, we added a deep neural network model which is currently in beta. Pattern-matching and exact matching processors can run in parallel with the statistical or the deep neural network processors, but the statistical and deep neural network processors cannot be used simultaneously.
Statistical Processor: The statistical processor that uses contextual features of the input to identify entities. Using computational linguistics, it has been trained on a body of annotated news stories to extract a variety of entities in a number of languages.
Pattern Matching Processor (regular expressions): Regular expressions (regexes) are a good way to identify language-specific entities and generic entities that appear in a variety of languages. You can modify the standard regexes that we supply, and add your own regexes.
Exact Matching Processor (gazetteers): Gazetteers (entity lists) return exact matches to a predefined list. The Entity Extractor distribution includes gazetteers for each language and a number of entity types, and a cross-language gazetteer for corporation names (as the name of the corporation does not generally change when it enters international markets). You can modify the standard gazetteers that we supply and add your own gazetteers to extract new entities or entity types.
Deep Neural Network Processor: This processor uses a model trained using a deep neural network. It is slower than the statistical processor, but has shown an error reduction of about 10% for English and Arabic and 30% for Korean, as measured by F-Score, for extracting person, location, organization, and titles. The model is trained on the same data as the statistical model. The model is based on an LSTM neural network and is backed by the TensorFlow library.
Note
The deep neural network processor is currently available in English, Arabic, Hebrew, and Korean.
Name Classifier Processor: This processor predicts entity types for text that lacks the syntactic context of complete sentences. It can extract entities from structured text, such as list items and tables, which typically contains text fragments instead of full sentences.
Redaction: When two processors return the same or overlapping entities, the redactor chooses an entity based on the length of the competing entity strings. You can also configure the redactor to choose which same-length mention to return based on entity type and/or processor.
Processors to customize results
These processors run on the extracted entities to further customize the results.
Joining: You can use a configuration file and the API to establish rules for joining adjacent entities into one (such as joining titles with personal names).
Rejections: You can define regexes and gazetteers to reject entities that otherwise may be returned.
Indoc Coref: In a single document, Entity Extractor chains together mentions that refer to the same entity (i.e., in-document coreference).
Optional functionality
Linker Processor: This processor extracts and links entity mentions to a knowledge base of known entities, each with a unique ID. This processor is disabled by default. Entity Extractor is shipped with a prepackaged default knowledge base linking entity mentions to a Wikidata QID. You can replace the default entity knowledge base with a custom knowledge base.
Notice
Currently, the linker performs its own entity extraction and does NOT use entities found by the default entity extraction processors (statistical, pattern-matching, exact-matching). Therefore, the linker processor’s entities will not necessarily match those from the default entity extraction processors.
Pronominal Resolver: Entity Extractor tries to resolve pronouns with their antecedent entities. This processor is disabled by default. The pronominal resolver is only available for English.
Standard entity types
Entity Extractor is pre-trained to extract the following entity types.
LOCATION
A city, state, country, region, or other location that contains both a population and a government.
A geographic place such as a body of water, mountain, park, or address.
A structure such as a building or monument.
ORGANIZATION
A corporation, institution, government agency, or other group of people defined by an established organizational structure.
PERSON
A human identified by name, nickname, or alias.
TITLE
Appellation associated with a person by virtue of occupation, office, birth, or as an honorific.
NATIONALITY
Reference to a country or region of origin, such as American or Swiss.
RELIGION
Reference to an organized religion or theology as well as its followers.
IDENTIFIER:CREDIT_CARDNUM
IDENTIFIER:DISTANCE*
IDENTIFIER:EMAIL
IDENTIFIER:LATITUDE_LONGITUDE*
IDENTIFIER:MONEY
IDENTIFIER:CURRENCY_AMT and IDENTIFIER:CURRENCY_TYPE
If CURRENCY is enabled, MONEY extractions will be replaced with CURRENCY_AMT and CURRENCY_TYPE whenever possible (both AMT and TYPE can be extracted). If the extracted value cannot be split, MONEY may be extracted instead.
To enable CURRENCY, set
regexCurrencySplitto true. By default, it is set to false.
IDENTIFIER:PERSONAL_ID_NUM
IDENTIFIER:PHONE_NUMBER
IDENTIFIER:URL
IDENTIFIER:UTM*
Geographical coordinates, expressed with the Universal Transverse Mercator System.
TEMPORAL:DATE
TEMPORAL:TIME
Entity types marked with a * are not returned by default. Activate them by instructing Entity Extractor to load the supplemental regexes in each language’s supplemental directory.
When the call includes {"options": {"includeDBpediaTypes": true}, Entity Extractor supports additional top-level entity types and over 700 additional types drawn from the DBpedia ontology. Entity linking must be enabled to return DBpedia entity types.
Adding new entity types
There are several ways to train Entity Extractor to extract entity types beyond the standard set.
Create new gazetteers (i.e., entity lists).
Create new regexes for entities that fit a pattern, such as telephone numbers.
You can train a new statistical model to extract different entity types using the Model Training Suite. Contact your sales representative or analyticssupport@babelstreet.com for more information on model training.
Language support
The following tables describe the entity types returned by the different processors for each supported language.
Key to processor used to identify each entity type:
S = statistical processor
G = exact matching processor (gazetteer)
R = pattern matching processor (regex)
L = entity linking available
D = deep neural network processor
Language (ISO code) | Entity Type | ||||||
|---|---|---|---|---|---|---|---|
LOC | ORG | PER | PROD | TTL | NAT | REL | |
Arabic | S/G/D/L | S/G/D/L | S/D/L | L | S | G | G |
Chinese, Script-insensitive | S/G/L | S/G/L | S/L | L | S | G | G |
Chinese, Simplified | S/G/L | S/G/L | S/L | L | S | G | G |
Chinese, Traditional | S/G/L | S/G/L | S/L | L | S | G | G |
Dutch | S/L | S/G/L | S/L | L | G | ||
English | S/G/L/D | S/R/G/L/D | S/L/D | S/L | S | G | G |
French | S/L | S/G/L | S/L | L | S | ||
German | S/L | S/G/L | S/L | L | S | ||
Hebrew | S/L/D | S/G/L/D | S/L/D | L | |||
Hungarian | S/G/L | S/G/L | S/G/L | S/L | S | ||
Indonesian | S/G/L | S/G/L | S/L | L | |||
Italian | S/L | S/G/L | S/L | L | S | ||
Japanese | S/L | S/G/L | S/L | L | S | G | G |
Korean | S/D/L | S/G/D/L | S/D/L | L | S | G | G |
Malay, Standard | S/G/L | S/G/L | S/L | L | |||
Pashto | S/L | S/G/L | S/L | L | S | ||
Persian | S/L | S/G/L | S/L | L | G | G | G |
Portuguese | S/L | S/G/L | S/L | L | S | ||
Russian | S/L | S/G/L | S/L | L | S | G | G |
Spanish | S/L | S/G/L | S/L | L | S | ||
Swedish | S/L | S/G/L | S/L | L | S | S/G | S/G |
Tagalog | S/G/L | S/G/L | S/L | L | |||
Urdu | S/L | S/G/L | S/L | L | G | ||
Vietnamese | S/L | S/L | S/L | L | G | G | G |
The following entity types are not returned by default:
Language (ISO Code) | Entity Type | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
CC# | Dist | EM | LATLNG | MONEY/CURRENCY | PERS ID | TEL# | URL | UTM | DATE | TIME | |
Arabic | R | R | R | R | R | R | R | R | R | R | R |
Chinese, Script-insensitive | R | R | R | R | R | R | R | R | R | R | R |
Chinese, Simplified | R | R | R | R | R | R | R | R | R | R | R |
Chinese, Traditional | R | R | R | R | R | R | R | R | R | R | R |
Dutch | R | R | R | R | R | R | R | R | R | R | R |
English | R | R | R | R | R | R | R | R | R | R | R |
French | R | R | R | R | R | R | R | R | R | R | R |
German | R | R | R | R | R | R | R | R | R | R | R |
Hebrew | R | R | R | R | R | R | R | R | R | R | R |
Hungarian | R | R | R | R | R | R | R | R | R | R | R |
Indonesian | R | R | R | R | R | R | R | R | R | R | |
Italian | R | R | R | R | R | R | R | R | R | R | R |
Japanese | R | R | R | R | R | R | R | R | R | R | R |
Korean | R | R | R | R | R | R | R | R | R | R | R |
Malay, Standard | R | R | R | R | R | R | R | R | R | R | |
Pashto | R | R | R | R | R | R | R | R | R | R | R |
Persian | R | R | R | R | R | R | R | R | R | R | R |
Portuguese | R | R | R | R | R | R | R | R | R | R | R |
Russian | R | R | R | R | R | R | R | R | R | R | R |
Spanish | R | R | R | R | R | R | R | R | R | R | R |
Swedish | R | R | R | R | R | R | R | R | R | R | R |
Tagalog | R | R | R | R | R | R | R | R | R | R | |
Urdu | R | R | R | R | R | R | R | ||||
Vietnamese | R | R | R | R | R | R | R | R | R | ||
Getting started
Install Analytics Server as described in the Analytics Server User Guide.
Using the SDK in an OSGi Bundle
Note
These steps are only necessary when Entity Extractor is configured to use linking.
The linker uses Java's ServiceLoader to dynamically discover and load connectors. This functionality does not work well when Entity Extractor is embedded in an OSGi service bundle without additional configuration, and Entity Extractor may fail on initialization. To use Entity Extractor inside an OSGi bundle, we recommend Apache's SPI Fly, a reference implementation of the OSGi ServiceLoader Mediator specification. Follow these steps to configure your OSGi project for Entity Extractor:
Visit https://aries.apache.org/modules/spi-fly.html and follow the instructions to include SPI Fly's Dynamic Weaving OSGi bundle and associated dependencies in your project by either using Maven to manage its dependency or by manually downloading and including them in your project.
Add the following lines to
MANIFEST.MFfile of the OSGi bundle that embeds the SDK:Require-Capability: osgi.serviceloader; filter:="(osgi.serviceloader=com.basistech.rosette.flinx.api.service.KnowledgeBaseVariantFactory)"; cardinality:=multiple,osgi.extender; filter:="(osgi.extender=osgi.serviceloader.processor)",osgi.extender; filter:="(osgi.extender=osgi.serviceloader.registrar)" Provide-Capability: osgi.serviceloader; osgi.serviceloader=com.basistech.rosette.flinx.api.service.KnowledgeBaseVariantFactory SPI-Consumer: *
Configuring the Entity Extractor
The entity extraction endpoint (https://localhost:8181/rest/v1/entities) comes fully configured to extract entities. This guide explains how to modify the configuration of the extractor for your use case.
General configuration options
Parameter | Description | Default |
|---|---|---|
| A Entity Extractor root directory contains language models and necessary configuration files. |
|
| The directory containing the RBL root for Entity Extractor to use. |
|
| Regular expressions and gazetteers may be configured to match tokens partially independent from token boundaries. If true, reported offsets correspond to token boundaries. |
|
| The maximum number of tokens allowed in an entity returned by Statistical Entity Extractor. Entity Redactor discards entities from Statistical Entity Extractor with more than this number of tokens. |
|
| Custom processors to add to annotators. See Creating Custom Processors for more details on custom processors. |
|
| Register a custom processor class. |
|
| Entity types to be excluded from extraction. |
|
| An overlay directory is a directory shaped like the |
|
| If true, entity chain salience values are calculated. Can be overridden by specifying |
|
| The option to retain social media symbols ('@' and '#') in normalized output |
|
| The option to keep existing annotated text entities. |
|
| Configures how structured regions will be processed. It has three values: |
|
| Determines if money values should be extracted as |
|
Handling structured regions
The Entity Extractor statistical model is trained to extract entities from unstructured text, where the model uses the syntactic context in sentences to help identify entities and entity types. But not all data is unstructured. Often input documents contain some sections of structured text, such as tables and lists, along with the unstructured text. Structured text usually does not contain full sentences and is often missing the syntactic context that Entity Extractor expects. This can lead to noisy results and false positives.
In addition to sentences and token, the Babel Street Base Linguistics processor identifies structured and unstructured regions. For structured regions, Entity Extractor disables the statistical processor. The text in structured regions is still processed by the rule-based processors (gazetteers and regexes) and the linker. Additionally, for some languages, another extractor, the name classifier, can extract entities from structured regions of text.
By default, structured regions are processed the same as unstructured regions.
To change how structured text is processed, set structuredRegionProcessingType in the rex-factory-config.yaml file. You can also set the value in the call as an option. It has three values:
none: (default) Disables the statistical/DNN models from processing structured regions. When set to
none, Entity Extractor does not attempt to extract entities from structured regions using the statistical processor or DNN models. The rule-based extractors (gazetteers, regex) and the linker are used to process structured regions.nerModel: Processes the entire document as unstructured text. Structured regions are processed the same as unstructured regions.
nameClassifier: Disables the statistical/DNN models from processing structured regions and enables the name classifier on the structured regions.
You can enable the Apache Tika processor to extract lists and tables for contentUri (HTML) input by setting the enableStructuredRegion option to true as the default in the rex-factory-config.yaml file or in the call as an option:
"options": {"enableStructuredRegion": true}Some structured regions may contain enough syntactic context for the statistical/DNN models to accurately extract entities. You can set a minimum number of tokens required in a structured region to override the structured region processor setting. If the number of tokens in the region exceeds this minimum, the region will be processed with the statistical/DNN models. The default value is 0. With this default, all structured regions are processed as defined by the structuredRegionProcessingType.
To set the minimum number of tokens, change the value of RegionProcessingSentenceTokensMin in the rosette-factory-config.yaml file.
Fragment boundary detector
Note
Disabling the fragment boundary detector will classify the entire text as unstructured. This has a similar effect to setting structuredRegionProcessingType to nerModel.
Entity Extractor detects entities within sentences. By default, Entity Extractor uses a fragment boundary detector to identify structured regions, adding sentence boundaries at tabs, newlines, and multiple whitespace characters (such as 3 or more spaces) in text fragments, such as lists and tables. This enables the detection of multiple entities in text fragments that do not form standard sentences. Consider the following text:
George Washington John Adams Thomas Jefferson
Without the fragment boundary detector, the statistical model identifies the preceding text as a single PERSON entity. With the fragment boundary detector, the statistical model identifies three separate PERSON entities.
Turn off the fragment boundary detector in the rex-factory-config.yaml file.
#Regular expressions and gazetteers may be configured to match tokens #partially independent from token boundaries. If true, reported offsets #correspond to token boundaries. snapToTokenBoundaries: false
Note
While the fragment boundary detector improves Entity Extractor's performance on tables, lists, and other non-prose content, Entity Extractor is, by design, tuned for prose and may not return high accuracy results on content with significant non-prose elements.
Overlay data directory
If your project has a set of unique data files that you would like to keep separate from other data files, you can put them in their own directory, also known as an overlay directory. This is an additional data directory, which takes priority over the default Entity Extractor data directory.
The overlay directory must have the same directory tree as the provided data directory. If an overlay directory is set, Entity Extractor searches both it and the default data directory.
If a file exists in both places, the version in the overlay directory is used.
If there is an empty file in the overlay directory, Entity Extractor will ignore the corresponding file in the default
datadirectory.If there is no file in the overlay directory, Entity Extractor will use the file in the default directory.
To specify the overlay directory use:
Create an overlay directory:
<install-directory>/my-dataAdd the overlay directory to the
rex-factory-config.yamlfile:dataOverlayDirectory: <install-directory>/my-data
Create an overlay directory:
Add an empty file (
gaz-LE.bin) to the overlay directory:my-data/gazetteer/eng/accept/gaz-LE.bin
Add the overlay directory to the
rex-factory-config.yamlfile:dataOverlayDirectory: <install-directory>/my-data
The default English gazetteer will not be used in calls.
In the above example, add a reject gazetteer file:
my-data/gazetter/deu/reject/reject-names.txtEntity salience
Entity Extractor can return a salience score for each extracted entity. Salience indicates whether the entity is important to the overall scope of the document. Returned salience scores are binary, either 0 (not salient) or 1 (salient). The decision is made according to several parameters, such as frequency, distance from document start, etc. Salience is not calculated by default.
To include the salience in a result for by call, add the option to the request:
"options": {"calculateSalience": true}Or to get the salience by default, set the calculateSalience parameter to true in the rex-factory-config.yaml file.
#An option to calculate entity-chain salience values. calculateSalience: true
Retrieving Base Linguistics configuration
Entity Extractor internally uses Babel Street Base Linguisticsto analyze the text before processing it. If the user application already uses Base Linguistics for other purposes, it's possible to save processing time and have Entity Extractor annotate pre-toxenized documents by passing Entity Extractor's annotator annotate function a tokenized AnnotatedText instance instead of a string. However, if the user's instance of Base Linguistics and Entity Extractor's internal instance of Base Linguistics are configured differently, Entity Extractor's results might be affected.
To solve the problem, EntityExtractor provides a getBaseLinguisticsParameters function that returns the set of Base Linguistics options Entity Extractor uses internally, given a language. This function should be called after the EntityExtractor has been otherwise configured. It returns an EnumSet of keys to the values Entity Extractor configures them to.
Tip
Entity Extractor provides a sample (rex-je-<version>/samples/RBLParametersSample.java) which demonstrates how to retrieve RBL parameters from Entity Extractor and use RBL directly to process documents before running the Entity Extractor extractor.
Modifying entity extraction processors
Entity Extractor provides multiple processors for extracting entities. You can optimize Entity Extractor for your entity extraction tasks by configuring the processors. Examples of the modifications you can make include:
Removing one or more processors
Adding gazetteers or gazetteer entries for selecting or rejecting entities
Adding regex files or individual regex entries
Adding custom processors
Customizing the statistical model with Model Training Suite.
Each processor has its own set of parameters to customize its behavior.
Selecting processors
By default, Entity Extractor uses all the processors. You can select to use a subset of the processors. For example, you can decide to return only entities extracted by statistical analysis.
Entity Extractor includes the following processors:
statistical: Entity extractor processor using a statistically-trained modeldeepNeuralNetwork: Entity extractor processor using a model trained using a deep neural networkacceptGazetteer: Rule-based entity extractor based on gazetteersacceptRegex: Rule-based entity extractor based on regular expressionskbLinker: Entity extractor based on a knowledge base of known entitiesredactor: Chooses an entity when multiple processors extract the same or overlapping entitiesjoiner: Joins adjacent entities into a single entityrejectGazetteer: Rule-based entity rejector based on gazetteersrejectRegex: Rule-based entity rejector based on regular expressionsindocCoref: Chains together mentions that refer to the same entity (in-document coreference)pronominalResolver: Pronomial resolverbaseLinguistics: Extracts hashtags, urls, atmentions, and emails
The order of execution of the processors is determined internally and cannot be changed. Some processors are prerequisites for other processors. Entity Extractor will throw an exception if the processor list is missing a required processor.
Edit the rex-factory-config.yaml file, modifying the list of active processors for an entity extraction run.
#List the set of active processors for an entity extraction run. #All processors are active by default. This method provides a way #to turn off selected processors. The order of the processors cannot be changed. #Note that turning off redactor can cause overlapping and unsorted #entities to be returned. #Default processors: #acceptGazetteer, #acceptRegex, #rejectGazetteer, #rejectRegex, #statistical, #indocCoref, #redactor, #joiner # processors: statistical
Note
The redactor chooses among the entities when processors extract the same or overlapping entities. Turning off the redactor will return all entities found by all processors. This can cause overlapping and unsorted entities to be returned.
Statistical processor
The statistical processor uses models based on computational linguistics and human-annotated training documents. You can add other statistical models to improve extraction for your use case.
You can train a new statistical model to extract different entity types or to improve the results of the statistical model using the Model Training Suite. Contact your sales representative or analyticssupport@babelstreet.com for more information on model training.
Statistical model based extractions can return confidence scores for each entity. Confidence scores correlate well with precision and may be used for thresholding and removal of false positives. Confidence is calculated by default if linking is enabled. Otherwise, use the calculateConfidence parameter to enable confidence scores. To set a threshold value, use the confidenceThreshold parameter.
Parameter | Description | Default |
|---|---|---|
| If true, entity confidence values are calculated. Can be overridden by specifying |
|
| The confidence value threshold below which entities extracted by the statistical processor are ignored. |
|
| Additional files used to produce statistical entities for the given language. You may pass multiple statistical models. The parameter should be formatted in trios of values specfying language, case-sensitivity and the model file, separated by commas. Case-sensitivity can be |
|
| The capitalization (aka 'case') used in the input texts. Processing standard documents requires caseSensitive, which is the default. Documents with all-caps, no-caps or headline capitalization may yield higher accuracy if processed with the caseInsensitive value. Can be |
|
Adding a custom statistical model
Custom trained entity extraction models can be added to Entity Extractor, replacing or supplementing the standard model shipped with the product. Use Model Training Suite (MTS) to train the new models.
You must choose whether to extract entities using both the new and the default statistical models together, which we call model mixing, or if you want to exclusively use the new statistical model.
With model mixing, Entity Extractor runs both the new and the default models in parallel and uses the redactor module to adjudicate the overlapping results.
Note
You can customize the redactor to favor output from the new statistical model(s).
The trained models are moved from MTS to the production instance of Entity Extractor through the following steps:
Export the entity extraction model from MTS.
Rename the model.
Tip
Model Naming Convention
The prefix must be
model.and the suffix must be-LE.bin. Any alphanumeric ASCII characters are allowed in between.Example valid model names:
model.fruit-LE.bin
model.customer4-LE.bin
Copy the model into the default data directory in the Entity Extractor root folder.
Deep neural network processor
Entity Extractor has a deep neural network (DNN) model that can be used in place of the statistical model for selected languages. By default, the statistical models is used rather than the DNN model. You can customize which model is used.
The deep neural network processor is using TensorFlow 2.3.1 (Java version 0.2.0). Ubuntu Linux 14.04+, Windows 7+, and MacOS 10.11+ are fully supported, but you should be able to run the processor successfully on other modern Linux flavors as well. To use the processor on platforms which are not otherwise supported, or to improve the speed on supported platforms, you can replace the TensorFlow library shipped with the product with one that’s built from source.
To make use of GPUs, you should download tensorflow-core-platform-gpu and add it to the top of your classpath.
To select which model will be used, set the modelType option in your calls. The default value for modelType is statistical. To enable the deep neural network model, provide DNN for the modelType. Example:
{"content": "your_text_here", "options": {"modelType": "DNN"}}Currently, Entity Extractor has DNN models for the following languages:
Arabic (
ara)English (
eng)Hebrew (
heb)Korean (
kor)
Important
The deep neural network model and the statistical model cannot be used together. When selected, the DNN replaces the statistical model.
Name classifier
Entity Extractor has a name classifier which can be used in place of the statistical model for structured regions. The name classifier is a machine learning model that tries to predict an entity type for an input string. It processes the entire structured region (the input string) as a single entity, predicting a label (PERSON, LOCATION, ORGANIZATION, or NONE) for the string. It works best on tables cells or list items where the entire entry is a single entity. If a structured region contains more text than the entity mention itself, the name classifier will usually label it as NONE.
To enable the name classifier for structured regions, set structuredRegionProcessingType to nameClassifier in the rex-factory-config.yaml file.
Currently, Entity Extractor supports the name classifier processor for the following languages:
Arabic
English
French
German
Hebrew
Japanese
Each language has its own configuration file, data/name_classifier/<lang>/<lang>_config.yaml, where <lang> is the 3 letter language code. The labelScoreThresholds field determines the chance that a classifier will label a phrase with a given entity type. Lowering the threshold will label more phrases, which will find more true positives, but may also identify more false positives.
To disable an entity type completely, remove or comment out the corresponding entry from the <lang>_config.yaml file. Example:
# labelScoreThresholds # Set the model score thresholds for each entity type. # To turn off an entity from the model, comment it out. # The accuracy of the current ORG model is too low and so it is better to turn it off for now. labelScoreThresholds: PER: 1.2 LOC: 3.2 # ORG: 5.2
Note
Currently, the ORG entity type is excluded for all languages. LOC is enabled for English and Japanese only.
Accept gazetteer
A gazetteer is a list of exact matches in a predefined closed class. For example, you can use a gazetteer to match all the countries in the world, as there is a precise and unambiguous list of countries. An entry would count as ambiguous if it has multiple possible meanings, such as "Apple", which could be either an ORGANIZATION or a fruit. The gazetteers are very fast at extracting entities. If you are searching for specific words or phrases in your data, a custom gazetteer is a good way to find them quickly.
Entity Extractor is shipped with default gazetteer files which you can modify. Gazetteer files are located in a subdirectory of the data directory, defined by language using the three-letter ISO-639-3 language code. A directory which applies to all languages, uses xxx for the language code. For example:
<install-directory>/roots/rex-<version>/data/gazetteer/eng/reject/ <install-directory>/roots/rex-<version>/data/gazetteer/xxx/accept/
By default, the data files are located in the <install-directory>/roots/rex-<version> directory. If you want your custom files to be in a separate location, use an Overlay data directory.
Parameter | Description | Default |
|---|---|---|
| The option to allow partial gazetteer matches. For the purposes of this setting, a partial match is one that does not line up with token boundaries as determined by the internal tokenizer. This only applies to accept gazetteers. |
|
| Additional gazetteer files used to produce entities for the given language. |
|
Creating a custom gazetteer
You can create your own, custom gazetteers. To create a custom gazetteer, put the new file in the appropriate location in the data/gazetteer tree.
language-specific:
data/gazetteer/<lang>/acceptall languages:
data/gazetteer/xxx/accept
A gazetteer file:
Is a .txt file encoded in UTF-8.
Each comment line is prefixed with #.
The first non-comment line is
TYPE[:SUBTYPE], where TYPE is required and SUBTYPE is optional. The type is applied to the entire gazetteer and defines the entity type name for output. TYPE and SUBTYPE may be predefined or user-defined.
Gazetteer entries and potential matches are space normalized to treat any whitespace between words as a single space. This enables the gazetteer to match entities with differences in whitespace.
Tip
To improve performance, text gazetteers can be compiled to a binary gazetteer using build-binary-gazetteer in the ./scripts directory or with Model Training Suite. The binary gazetteer file name must end with -LE.bin.
To track common infectious diseases, create a gazetteer like this:
# File: infectious-diseases-gazetteer.txt # DISEASE:INFECTIOUS tuberculosis e. coli malaria influenza
A single gazetteer may not be enough; you can create as many gazetteers as you need. To search for the scientific names of the infectious disease, you can create a file like this:
# File: latin-infectious-gazetteer.txt # DISEASE:INFECTIOUS Mycobacterium tuberculosis Escherichia coli Plasmodium malariae Orthomyxoviridae
To track certain diseases by their causes:
# File: infectious-bacterial-gazetteer.txt # DISEASE:BACTERIAL Escherichia coli E. coli Staphylococcus aureus Streptococcus pneuminiae Salmonella
Or to track the drugs used to treat them:
# File: antimicrobial-drugs-gazetteer.txt # DRUG:ANTIMICROBIAL methicillin vancomycin macrolide fluoroquinolone
Tip
By default, the data files are located in the <install-directory>/roots/rex-<version> directory. To install custom gazetteer files in a separate directory, use an Overlay data directory.
Partial gazetteer matches
By default, gazetteer matches must match token boundaries in the input text. You can enable partial matches that do not start and/or do not end on token boundaries. You can also set individual regexes to return partial matches by including allow-partial-matches="yes" in a regex.
Partial matches require in-document coreference to be disabled. As a result, the mentions will not be grouped into entities.
#An option for document entity resolution (also known as entity chaining). indocType: NULL
Tip
We do not recommend that you enable partial matches. It adds processing time and may match more than you expect. An entry such as "red" in a COLOR gazetteer will match "Frederick" in the input text.
Chinese gazetteers
Entity Extractor can analyze both simplified and traditional Chinese language documents. The following three language codes for are all used for Chinese:
Chinese (
zho)Simplified Chinese (
zhs)Traditional Chinese (
zht)
zho is the Chinese language code; it applies to both simplified and traditional Chinese. Gazetteers using zho as the language code apply to documents with a language code of zhs or zht. Users should include both simplified and traditional Chinese words in the zho gazetteer, so that it will work for all Chinese language codes.
{"language": "zho",
"configuration": {
"entities": { "ANIMAL": [ "狮子", "獅子" ] }
}
}Adding dynamic gazetteers
You can use the API to dynamically add gazetteer entries to the /entities endpoint. The REST endpoint is:
https://localhost:8181/rest/v1/entities/configuration/gazetteer/add
Parameters:
language: The 3 letter language code of the new values. For example, to add an English value, the language would be
eng. To add the value to all languages, the language code isxxx. The language must be supported by the /entities endpoint.entity type: The type of the entity. For example, PERSON, LOCATION, ORGANIZATION, or TITLE. The entity type must already exist in the system.
values: One or more values to be added to the gazetteer.
profileId (Optional): Custom profile id
In this example, we're adding the companies New Corp and Best Business, to the entities gazetteer for all languages (xxx).
curl --request POST \
--url http://localhost:8181/rest/v1/entities/configuration/gazetteer/add \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--data '{"language": "xxx", "configuration":{"entities":{ "COMPANY": ["New Corp", "Best Business"]}}}'In this example, we're adding the same data as above, to the profile named group1.
curl --request POST \
--url http://localhost:8181/rest/v1/entities/configuration/gazetteer/add \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--data '{"language": "xxx", \
"configuration":{"entities":{ "COMPANY": ["New Corp", "Best Business"]}}, "profileId": "group1"}'In this example, the new values are in a file called new_companies.json:
{"language": "xxx", "configuration": {"entities":{ "COMPANY": ["New Corp", "Best Business"] } } } The cURL command to add the file values:
curl --request POST \ --url http://localhost:8181/rest/v1/entities/configuration/gazetteer/add \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --data '@new_companies.json'
Caution
Dynamic gazetteer entries are held completely in memory and state is not saved on disk. When Analytics Server is brought down, the contents are lost. To save the new entries, add the new values to the related gazetteer file before restarting Analytics Server.
Accept regex
Regular expressions (regexes) are used for finding entities which follow a strict pattern with a rigid form and infinite combinations, such as URLs and credit card numbers. In the default Entity Extractor installation the regex files are:
language specific:
data/regex/<lang>/accept/regexes.xmlwhere <lang> is the ISO 693-3 language codecross-language:
data/regex/xxx/accept/regexes.xml
You can modify these files to add new patterns to extract the same entity type.
Parameter | Description | Default |
|---|---|---|
| Additional files used to produce regex entities. |
|
| The option to add supplemental regex files, usually for entity types that are excluded by #default. The supplemental regex files are located at |
|
| When set to true, Entity Extractor will attempt to split entities extracted with the regex engine of type IDENTIFIER:MONEY into two entities: IDENTIFIER:CURRENCY_AMT and IDENTIFIER:CURRENCY_TYPE. These types represent the amount of the currency (50,000) and the currency type ($), respectively |
|
To extract new entity types that have predictable patterns, add a new XML regex file, either the language-specific (<lang> ) or generic (xxx) location. Entity Extractor uses the Tcl regex format for defining the regex patterns.
Entity Extractor modifies the regex matcher so that \n in a regex expression matches straight new lines (\n), carriage returns (\r), or a combination of both (\r\n). Regardless of what is matches, offsets and lengths in the result will match the input document.
By default, the data files are located in the <install-directory>/roots/rex-<version> directory. If you want your custom files to be in a separate location, use an Overlay data directory.
Creating a new regex
Each regex is defined in a regexp, which may contain a lang attribute and may refer to define elements.
The lang attribute designates the language for the regex. If the regex applies to text in any language, there is no lang attribute. For example, all the regexes in data/regex/eng should include lang="eng". The regexes in data/regex/xxx do not include the lang attribute, since they apply to text in any language.
A define element contains a regex and a name attribute. By naming the regex, you can include the regex in multiple regexp files.
time_ampmDefine the regular expression in a
definestatement:<define lang="eng" name="time_ampm">(?:[pa]\.?\s?m\.?)</define>
Use the regular expression in a
regexpstatement:<regexp lang="eng" type="TEMPORAL:TIME">...${time_ampm}...<regexp>
When Entity Extractor evaluates the regexp statement, it follows these steps:
When
${time_ampm}appears in aregexp lang="eng"element, Entity Extractor looks for adefine name="time_ampm" lang="eng"statement.If it does not find the element, Entity Extractor looks for a
define name="time_ampm"element without the lang attribute.If it does not find such an element, an error occurs.
If you include an id attribute setting, that value is returned as the "subsource" of an entity returned by this regexp.
Supplemental regexes
Entity Extractor is shipped with supplemental regexes which are not activated by default. The supplemental regexes are located in the data/regex/<lang>/accept/supplemental directory.
#The option to add supplemental regex files, usually for entity types that are excluded by default. The supplemental regex files are located at data/regex/<lang>/accept/supplemental and are not used unless specified. supplementalRegularExpressionPaths: - data/regex/eng/accept/supplemental/geo-regexes.xml
Language (ISO Code) | Currency | Date | Distance | Geo | License-Plate | Numbers | Org | Personal-ID | Phone | Time |
|---|---|---|---|---|---|---|---|---|---|---|
Arab | X | X | X | X | X | X | X | |||
German | X | X | X | X | X | X | ||||
English | X | X | X | X | X | X | X | |||
Farsi | X | X | X | X | X | X | ||||
French | X | X | X | X | X | X | ||||
Hebrew | X | X | X | X | X | X | ||||
Hungarian | X | X | X | X | X | X | ||||
Hindu | X | X | X | X | X | |||||
Italian | X | X | X | X | X | X | ||||
Japanese | X | X | X | X | X | X | ||||
Korean | X | X | X | X | X | X | ||||
Dutch | X | X | X | X | X | X | ||||
Portuguese | X | X | X | X | X | X | ||||
Pursian | X | X | X | X | X | X | ||||
Russian | X | X | X | X | X | X | ||||
Spanish | X | X | X | X | X | X | ||||
Swedish | X | X | X | X | X | X | ||||
Tagalog | X | X | X | X | X | |||||
Upper-case English | X | X | X | X | X | X | ||||
Vietnamese | X | X | X | X | X | |||||
Simplified Chinese | X | X | X | X | X | X | ||||
Traditional Chinese | X | X | X | X | X | X | ||||
Malay, Standard | X | X | X | X | X |
Joiner
The joiner combines adjacent entities into a single entity, based on the joiners rules. Entity Extractor then returns the single entity.
The configuration file for joining adjacent entities is in data/etc.
Parameter | Description | Default |
|---|---|---|
| File containing additional joiner rules. |
|
| Run the joiner after the redactor, instead of before. |
|
The file neredact-config.xml specifies the rules for joining adjacent entities. Adjacent TITLE entities are joined into a single TITLE entity. The joiner elements for joining TITLE and PERSON entities into a PERSON entity are commented out by default.
<neredactconfig>
<joiners>
<joiner left='TITLE' right='TITLE' joined='TITLE'/>
<!-- Not joined by default
<joiner language='eng' left='TITLE' right='PERSON' joined='PERSON'/>
<joiner language='jpn' left='PERSON' right='TITLE' joined='PERSON'/>
-->
</joiners>
</neredactconfig>Rules can optionally specify a language, in which case they will apply only to entities of that specific language. If a language is not specified, the rule will apply for any language.
Entities are considered adjacent if they are separated by no more than 5 whitespace characters.
For example, to join "Barack Obama" and "President" in "Barack Obama, President", the joiner rule is:
<joiner left='PERSON' adjacency-regex=',\s+' right='TITLE' joined='PERSON'/>
The joiner runs before the redactor, as of release 7.46.2. To run the joiner after the redactor, set the parameter runJoinerPostRedactor to true in the rex-factory-config.yaml file.
Redactor
The redactor determines which entity to choose when multiple mentions for the same entity are extracted. The redactor first chooses longer entity mentions over shorter ones. If the length of the mentions are the same, the redactor uses weightings to select an entity mention.
Different processors can extract overlapping entities. For example, a gazetteer extracts "Newton", Massachusetts as a LOCATION, and the statistical processor extracts "Isaac Newton" as a PERSON. When two processors return the same or overlapping entities, the redactor chooses an entity based on the length of the competing entity strings. By default, a conflict between overlapping entities is resolved in favor of the longer candidate, "Isaac Newton".
Tip
The correct entity mention is almost always the longer mention. There can be examples, such as the example of "Newton" above, where the shorter mention is the correct mention. While it might seem that turning off the option to prefer length is the easiest fix, it usually just fixes a specific instance while reducing overall accuracy. We strongly recommend keeping the default redactorPreferLength as true.
The redactor can be configured to set weights by:
entity type
processor
Configuring the redactor
The configuration file for setting redactor weights is in <data/etc.
Set weight by entity type
Each of the ne-type elements in ne-types.xml defines weightings for a specified entity type. For example, to assign weights for IDENTIFER entities:
<ne_type>
<name>IDENTIFIER</name>
<subtypes>
<name>EMAIL</name>
<name>URL</name>
<name>DOMAIN_NAME</name>
<name>IP_ADDRESS</name>
<name>PHONE_NUMBER</name>
<name>FAX_NUMBER</name>
<name>PERSONAL_ID_NUM</name>
<name>CREDIT_CARD_NUM</name>
<name>MONEY</name>
<name>PERCENT</name>
<name>NUMBER</name>
</subtypes>
<weight name="statistical" value="9" />
<weight name="gazetteer" value="10" />
<weight name="regex" value="10" />
</ne_type>This assigns weights for the IDENTIFIER entities. They are also weighted by processor.
Set weights by processor
The processor weights are relative values; they do not have to add up to any specific value. For example, to favor gazetteer entries over regexes, and favor both over values returned by statistical analysis, you could set the weights as follows:
<weight name="statistical" value="1" />
<weight name="gazetteer" value="10" />
<weight name="regex" value="5" />Some processors offer subsources to identify specific instances. The kb-linker processor returns a subsource indicating the knowledge base the extraction originated in. To set a weight to a specific subsource set the name property to PROCESSOR:SUBSOURCE. For example, to favor your custom knowledge base (myKB) over other extractions but keep other linker extractions low, you could set the weights as follows:
<weight name="kb-linker:MyKB" value="20" />
<weight name="kb-linker" value="1" />When you define new entity types for gazetteers and regexes, you should add those entity types to ne-types.xml if you want to control how the redactor resolves conflicts. Types that do not appear in this file receive weights of 10 for all three processors.
For an entity type with subtypes, the settings apply to all the subtypes.
Reject gazetteer
Instead of adding entities to extract when matched you can define a list of entities to reject when matched. These are reject gazetteers.
The format of a reject gazetteer is identical to the format of an accept gazetteer except the wildcard (*) is allowed in the entity type. As with accept gazetteers, they are arranged by language.
language-specific:
data/gazetteer/<lang>/rejectall languages:
data/gazetteer/xxx/reject
If, for example, it is for rejecting German entities, put it in data/gazetteer/deu/reject. If it is for rejecting entities in multiple languages, put it in data/gazetteer/xxx/reject.
Parameter | Description | Default |
|---|---|---|
| Additional gazetter files used to reject entities for the given language. |
|
The following .txt file in data/gazetteer/eng/reject, rejects the PERSON entity named "George Watson" when processing English documents.
PERSON George Watson
A wildcard entity type would match any types. The value "George Watson" would be rejected from all entity types, not just PERSON.
* George Watson
Reject regex
A typical regex is used to identify entities of a specified entity type. You can also define a regex to reject entities; that is whenever the pattern is identified, the entity is rejected as the defined type. Reject regexes follow the same format as accept regexes with the addition that the wildcard (*) is allowed for the entity type.
Place your reject regex files in the following directories:
language-specific:
data/regex/<lang>/rejectall languages:
data/regex/xxx/reject
Parameter | Description | Default |
|---|---|---|
| Additional regex files used to reject entities. |
|
For example, a file to reject German entities, is named data/regex/deu/reject. Files rejecting entities in multiple languages go in data/regex/xxx/reject.
The following .xml file in data/regex/eng/reject rejects Baltimore as a LOCATION entity when processing English documents.
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<!DOCTYPE regexps PUBLIC "-//basistech.com//DTD RLP Regular Expression Config 7.1//EN"
"urn:basistech.com:7.1:rlpregexp.dtd">
<regexps>
<regexp lang="eng" type="LOCATION">Baltimore</regexp>
</regexps>Note
Lookbehind assertions are not supported.
In-document coreference
Within a document, there may be multiple references to a single entity. In-document coreference (indoc coref) chains together all mentions to an entity.
The indoc coref server is an additional server which must be installed on your system for Server.
By default, indoc coref is disabled.
To enable indoc coref for a call, set the option
useIndocServertotrue.The response time will be slower when indoc coref is enabled. We recommend using a GPU with indoc coref enabled.
To see which languages support indoc coref, use the
/entities/indoc-coref-server/supported-languagesendpoint.
Pronominal resolution
If resolvePronouns is enabled (it is disabled by default), Entity Extractor will try to resolve pronouns with the corresponding antecedent entities.
Pronominal resolution is supported for English only.
Parameter | Description | Default |
|---|---|---|
| When true, resolve pronouns to person entities. |
|
Creating Custom Processors
Entity Extractor has a plugin architecture that allows users to create custom processors that can be inserted into the Entity Extractor pipeline at two points.
At the
preExtractorphase - a custom processor may insert additional text pre-processing after input, but before tokenization and sentence breaks (either provided by Base Linguistics or the user’s own tokenizer and sentence breaker).At the
preRedactionphase - a custom processor may insert corrections or modifications to output from the default extractors (statistical, regex, gazetteer), using the full information and context that the default extractors have access to (e.g., plain text data, sentence boundaries, tokens, full list of entities extracted and the source extractors which found them, boundaries, and processor types, etc.)
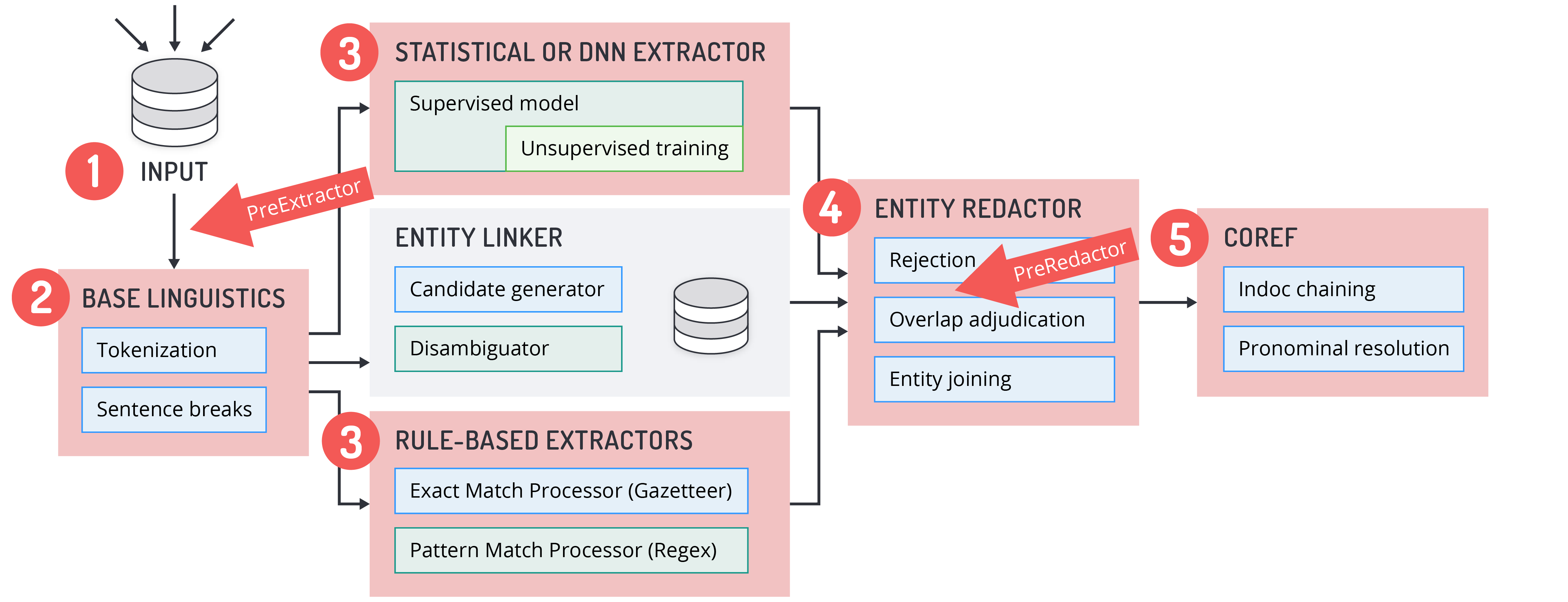
Pre-Extraction Custom Processors: For Additional Text Pre-Processing
Custom processors at the preExtractor phase can provide additional text pre-processing. For example, if the files contain boilerplate, footers, and navigation bar text that are not the target of the analysis, including these parts of the document in the analysis may trip up the tokenization process and thus decrease the overall quality of extraction results. A preExtractor custom processor can strip footers of emails or add metadata to the target files.
Pre-Redaction Custom Processors: For Correcting/Modifying Extractor Output
Custom processors at the preRedaction phase are run after the default processors (statistical, gazetteer, regex) and any filters (reject files for regex and gazetteer) have run, but before the redactor. A custom processor at the preRedaction phase receives all information and context of the intermediate results from the output of the default extraction processors, and can make modifications to those results before the redactor phase adjudicates conflicts between the results from statistical, gazetteer, and regex processors.
Only entities and metadata attributes fields can be updated with the pre-redaction custom processor. If the custom processor attempts to make changes in forbidden fields, specifically data (input), token, or sentence attributes, the specified changes will be ignored and a warning will be logged.
Examples of cases that are correctable with a custom processor include:
Reject a mention as an entity: Cases where Entity Extractor incorrectly extracts a mention that is not an entity can be excluded from the new list of entity results.
Correcting the entity type: If, for example, your dataset consists of personal letters, and you have high confidence that after a closing such as “Love,” or “Sincerely yours,” the entity that follows should be a PERSON, but Entity Extractor is identifying it as an ORGANIZATION.
Modifying entity boundaries: If, for example, Entity Extractor is incorrectly extracting “Hi” as part of a PERSON entity, as in “Hi Joe” instead of just extracting “Joe”.
The code sample in our public github repository at https://github.com/rosette-api/custom-processor-sample includes a custom processor called SampleCustomProcessor.java which corrects an entity type.
Note
Filters (reject files) vs. Pre-Redaction Custom Processors
The reject files for regexes and gazetteers simply filter out a list of words or a pattern-matched set of words the user does not want to extract as entities. These reject functions operate without considering the context in which these words appear. By contrast, custom processors at the preRedaction phase have access to the entire context in which an extracted entity appears, and thus can implement smarter rules.
Implementing the Custom Processor
You can implement the CustomProcessor and Annotator interfaces in Java in your own JAR and register them via the extractor’s setCustomProcessors. Your custom processor is the factory of the annotator implementation and thus should be familiar with the requirements of your annotators, and provide them with the correct parameters for the language and the phase requests. The Annotator is the interface to the ADM (i.e., annotated text) and based on the custom processor it manipulates the ADM and outputs it to the next phase.
Walk-Through Example of preRedaction Phase Custom Processors
A custom preRedaction annotator receives entity mentions from all extraction processors, after reject processors run and before redactor and coref processors run. It can reject (remove) entity mentions, modify entity types or adjust entity mention offsets. These modifications will affect the input of the next processors in the pipeline. For example coref would not consider chaining together PERSON and ORGANIZATION mentions into the same entity, so a mention whose entity type was changed from ORGANIZATION to PERSON by a custom processor would only be chained to other PERSON entities. After the Redactor phase, the rest of the pipeline runs as usual.
The code sample in our public github repository at https://github.com/rosette-api/custom-processor-sample includes a custom processor called SampleCustomProcessor.java which corrects an entity type.
The steps to create a custom processor:
Copy the custom processor java code into the
$ROSAPI_HOME/launcher/bundlesdirectory.Edit the
$ROSAPI_HOME/launcher/config/rosapi/rex-factory-config.yaml file:Add the custom processors to the
customProcessorssection:#Custom processors to add to annotators. customProcessors: - personContextAnnotator - boundaryAdjustAnnotator - metadataAnnotatorRegister the custom processor class:
#Register a custom processor class. customProcessorClasses: - sample.SampleCustomProcessor
Run Analytics Server.
Entity linking
Entity linking provides a mechanism for disambiguating the identity of similarly named entities mentioned in a document. For example, “Rebecca Cole” is the second African-American woman to become a doctor in the United States and also the name of an Australian professional basketball player. Linking helps establish the identity of the entity by disambiguating common names and matching a variety of names, such as nicknames and formal titles, with an entity ID.
Linker processor
To link entities to a knowledge base, Entity Extractor uses a statistical disambiguation model trained on a knowledge base. The linker processor is delivered with a model based on a default Wikidata knowledge base. If the entity exists in Wikidata, then Entity Extractor returns the Wikidata QID, such as Q1 for the Universe, in the entityId field. Once enabled, the linker can also return:
If the linker is disabled (the default), a random string is returned as the entityId. The string starts with a "T" (temporary id) followed by a random number, which is unique per document.
In addition to the default Wikidata knowledge base, you can train a disambiguation model for a custom knowledge base using the Model Training Suite. The custom knowledge base model can replace or run in parallel with the default knowledge base.
Linker Processor Files The linker processor is packaged as part of the standard Entity Extractor distribution. The linker files are in the subdirectory data/flinx.
By default, the linker processor both extracts and links entity candidates. These functions are separate from the default Entity Extractor entity extraction performed by the statistical, pattern-matching, and exact-matching processors.
You can choose to link the candidates from the statistical, pattern-matching, and exact-matching processors instead of using the linker processor to extract candidates. Set the parameter linkMentionMode to entities to use the other processors, not the linker processor. By default, linkMentionMode is set to text, in which case the linker processor extracts the candidate entities from the text.
Important
If you use the linker processor to extracts entities, the entities from the linker processor may differ from those returned by the statistical, pattern-matching, and exact-matching processors. The redactor will resolve any overlapping or conflicting entity results.
Parameter | Description | Default |
|---|---|---|
| Custom list of Knowledge Bases for the linker, in order of priority |
|
| The option to link mentions to knowledge base entities with disambiguation model. Enabling this option also enables |
|
| If true, entity confidence values are calculated. Can be overridden by specifying |
|
| The option to assign default confidence value 1.0 to non-statistical entities instead of null. |
|
| The confidence value threshold below which linking results by the kbLinker processor are ignored. |
|
| If set to |
|
Entity linking is enabled by setting the linkEntities value to true in the rex-factory-config.yaml file or by adding {"options": {"linkEntities": true}} to an API call.
By default, Entity Extractor factory is configured so the linker finds candidates in text before attempting to link them with knowledge base entries. To change this behavior and use pre-existing mentions extracted by the statistical, pattern-matching and exact-matching processors set the linkMentionMode in rex-factory-config.yaml to entities. In addition it is possible to pass the linkMentionMode option in the API call {"options": {"linkEntities": true, "linkMentionMode": "entities"}}. In both cases entity linking must be enabled.
Selecting a knowledge base for linking
By default, all knowledge bases under the data/flinx/data/kb directory inside the Entity Extractor installation will automatically be used for linking. Any custom knowledge bases placed in this directory will be loaded each time Entity Extractor launches.
You can enable dynamic loading, controlling which custom knowledge bases will be loaded in the rex-factory-config.yaml file with the kbs parameter, which takes a List of Paths to knowledge bases.
kbs:
- /customKBs/kb1
- /customKBs/kb2
- /rosette/server/roots/rex/7.44.1.c62.2/data/flinx/data/kb/basis
The list is in priority order; the match from the highest knowledge base on the list will be returned.
Important
Setting the list of knowledge bases completely overwrites the list of knowledge bases the linker uses. If you want the default Wikidata knowledge base to be included, it must be on the list of knowledge bases.
DBpedia types for linked entities
The linker processor can associate entities with types drawn from the DBpedia ontology, which provides over 700 types at up to seven levels of granularity.
By default, providing DBpedia types is turned off. To turn it on, add {"options": {"includeDBpediaTypes": true}} to your API call.
PermIDs
The linker processor can return the Refinitiv PermID for a subset of entities which are identified with a QID. By default, linking to PermIDs is turned off.
To return the PermID, add {"options": {"includePermID": true}} to your call. To return PermIDs, entity linking must also enabled.
ISO 639-3 language codes
Entity Extractor uses ISO 639-3 codes to specify the language of the input text.
Tcl regex format
The Pattern Matching Processor uses the Tcl regular expression engine to identify named entities in input text. To see the named entity types that the Pattern Matching Processor with the shipped regexes file returns, see Language Support of Named Entities. For background information about adding your own regexes, see Accept regex.
For information on Tcl syntax, see the Tcl re_syntax Manual Page .
Entity Extractor modifies the regex matcher so that \n in a regex expression matches straight new lines (\n), carriage returns (\r), or a combination of both (\r\n). Regardless of what is matches, offsets and lengths in the result will match the input document.
Tcl license
This software is copyrighted by the Regents of the University of California, Sun Microsystems, Inc., Scriptics Corporation, ActiveState Corporation and other parties. The following terms apply to all files associated with the software unless explicitly disclaimed in individual files.
The authors hereby grant permission to use, copy, modify, distribute, and license this software and its documentation for any purpose, provided that existing copyright notices are retained in all copies and that this notice is included verbatim in any distributions. No written agreement, license, or royalty fee is required for any of the authorized uses. Modifications to this software may be copyrighted by their authors and need not follow the licensing terms described here, provided that the new terms are clearly indicated on the first page of each file where they apply.
IN NO EVENT SHALL THE AUTHORS OR DISTRIBUTORS BE LIABLE TO ANY PARTY FOR DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OF THIS SOFTWARE, ITS DOCUMENTATION, OR ANY DERIVATIVES THEREOF, EVEN IF THE AUTHORS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
THE AUTHORS AND DISTRIBUTORS SPECIFICALLY DISCLAIM ANY WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, AND NONINFRINGEMENT.THIS SOFTWARE IS PROVIDED ON AN "AS IS" BASIS, AND THE AUTHORS AND DISTRIBUTORS HAVE NO OBLIGATION TO PROVIDE MAINTENANCE, SUPPORT, UPDATES, ENHANCEMENTS, OR MODIFICATIONS.
GOVERNMENT USE: If you are acquiring this software on behalf of the U.S. government, the Government shall have only "Restricted Rights" in the software and related documentation as defined in the Federal Acquisition Regulations (FARs) in Clause 52.227.19 (c) (2). If you are acquiring the software on behalf of the Department of Defense, the software shall be classified as "Commercial Computer Software" and the Government shall have only "Restricted Rights" as defined in Clause 252.227-7013 (c) (1) of DFARs. Notwithstanding the foregoing, the authors grant the U.S. Government and others acting in its behalf permission to use and distribute the software in accordance with the terms specified in this license.
Entity types and DBpedia types
Entity Types and DBpedia Types
Entity type | DBpedia type |
|---|---|
ACTIVITY | Activity |
ACTIVITY | Activity/Game |
ACTIVITY | Activity/Sales |
ACTIVITY | Activity/Sport |
ACTIVITY | Activity/Sport/Athletics |
ACTIVITY | Activity/Sport/TeamSport |
ACTIVITY | Activity |
ANATOMY | AnatomicalStructure |
ANATOMY | AnatomicalStructure/Artery |
ANATOMY | AnatomicalStructure/BloodVessel |
ANATOMY | AnatomicalStructure/Bone |
ANATOMY | AnatomicalStructure/Brain |
ANATOMY | AnatomicalStructure/Embryology |
ANATOMY | AnatomicalStructure/Ligament |
ANATOMY | AnatomicalStructure/Lymph |
ANATOMY | AnatomicalStructure/Muscle |
ANATOMY | AnatomicalStructure/Nerve |
ANATOMY | AnatomicalStructure/Vein |
DISEASE | Disease |
EVENT | Event |
EVENT | Event/Competition |
EVENT | Event/Competition/Contest |
EVENT | Event/LifeCycleEvent |
EVENT | Event/LifeCycleEvent/PersonalEvent |
EVENT | Event/NaturalEvent |
EVENT | Event/NaturalEvent/Earthquake |
EVENT | Event/NaturalEvent/SolarEclipse |
EVENT | Event/NaturalEvent/StormSurge |
EVENT | Event/PenaltyShootOut |
EVENT | Event/SocietalEvent |
EVENT | Event/SocietalEvent/AcademicConference |
EVENT | Event/SocietalEvent/Attack |
EVENT | Event/SocietalEvent/Convention |
EVENT | Event/SocietalEvent/Election |
EVENT | Event/SocietalEvent/FilmFestival |
EVENT | Event/SocietalEvent/HistoricalEvent |
EVENT | Event/SocietalEvent/Meeting |
EVENT | Event/SocietalEvent/MilitaryConflict |
EVENT | Event/SocietalEvent/MusicFestival |
EVENT | Event/SocietalEvent/Rebellion |
EVENT | Event/SocietalEvent/SpaceMission |
EVENT | Event/SocietalEvent/SportsEvent |
EVENT | Event/SocietalEvent/SportsEvent/CyclingCompetition |
EVENT | Event/SocietalEvent/SportsEvent/FootballMatch |
EVENT | Event/SocietalEvent/SportsEvent/GrandPrix |
EVENT | Event/SocietalEvent/SportsEvent/InternationalFootballLeagueEvent |
EVENT | Event/SocietalEvent/SportsEvent/MixedMartialArtsEvent |
EVENT | Event/SocietalEvent/SportsEvent/NationalFootballLeagueEvent |
EVENT | Event/SocietalEvent/SportsEvent/Olympics |
EVENT | Event/SocietalEvent/SportsEvent/Olympics/OlympicEvent |
EVENT | Event/SocietalEvent/SportsEvent/Race |
EVENT | Event/SocietalEvent/SportsEvent/Race/CyclingRace |
EVENT | Event/SocietalEvent/SportsEvent/Race/HorseRace |
EVENT | Event/SocietalEvent/SportsEvent/Race/MotorRace |
EVENT | Event/SocietalEvent/SportsEvent/Tournament |
EVENT | Event/SocietalEvent/SportsEvent/Tournament/GolfTournament |
EVENT | Event/SocietalEvent/SportsEvent/Tournament/SoccerTournament |
EVENT | Event/SocietalEvent/SportsEvent/Tournament/TennisTournament |
EVENT | Event/SocietalEvent/SportsEvent/Tournament/WomensTennisAssociationTournament |
EVENT | Event/SocietalEvent/SportsEvent/WrestlingEvent |
EVENT | Holiday |
EVENT | SportsSeason |
EVENT | SportsSeason/MotorsportSeason |
EVENT | SportsSeason/SportsTeamSeason |
EVENT | SportsSeason/SportsTeamSeason/BaseballSeason |
EVENT | SportsSeason/SportsTeamSeason/FootballLeagueSeason |
EVENT | SportsSeason/SportsTeamSeason/FootballLeagueSeason/NationalFootballLeagueSeason |
EVENT | SportsSeason/SportsTeamSeason/NCAATeamSeason |
EVENT | SportsSeason/SportsTeamSeason/SoccerClubSeason |
EVENT | SportsSeason/SportsTeamSeason/SoccerLeagueSeason |
EVENT | Statistic |
EVENT | TimePeriod |
EVENT | TimePeriod/CareerStation |
EVENT | TimePeriod/CareerStation/MilitaryService |
EVENT | TimePeriod/GeologicalPeriod |
EVENT | TimePeriod/HistoricalPeriod |
EVENT | TimePeriod/PeriodOfArtisticStyle |
EVENT | TimePeriod/PrehistoricalPeriod |
EVENT | TimePeriod/ProtohistoricalPeriod |
EVENT | TimePeriod/Reign |
EVENT | TimePeriod/Tenure |
EVENT | TimePeriod/Year |
EVENT | TimePeriod/YearInSpaceflight |
EVENT | UnitOfWork/Case |
EVENT | UnitOfWork/Case/LegalCase |
EVENT | UnitOfWork/Case/LegalCase/SupremeCourtOfTheUnitedStatesCase |
EVENT | UnitOfWork/Project |
EVENT | UnitOfWork/Project/ResearchProject |
EVENT | E4_Period |
FOOD | Food |
FOOD | Food/Beverage |
FOOD | Food/Beverage/Beer |
FOOD | Food/Beverage/Vodka |
FOOD | Food/Beverage/Wine |
FOOD | Food/Beverage/Wine/ControlledDesignationOfOriginWine |
FOOD | Food/Cheese |
IDENTIFIER | Identifier |
IDENTIFIER | Identifier/TopLevelDomain |
LANGUAGE | Language |
LANGUAGE | Language/ProgrammingLanguage |
LOCATION | ElectricalSubstation |
LOCATION | Place |
LOCATION | Place/ArchitecturalStructure |
LOCATION | Place/ArchitecturalStructure/AmusementParkAttraction |
LOCATION | Place/ArchitecturalStructure/AmusementParkAttraction/RollerCoaster |
LOCATION | Place/ArchitecturalStructure/AmusementParkAttraction/WaterRide |
LOCATION | Place/ArchitecturalStructure/Arena |
LOCATION | Place/ArchitecturalStructure/Building |
LOCATION | Place/ArchitecturalStructure/Building/Casino |
LOCATION | Place/ArchitecturalStructure/Building/Castle |
LOCATION | Place/ArchitecturalStructure/Building/Factory |
LOCATION | Place/ArchitecturalStructure/Building/HistoricBuilding |
LOCATION | Place/ArchitecturalStructure/Building/Hospital |
LOCATION | Place/ArchitecturalStructure/Building/Hotel |
LOCATION | Place/ArchitecturalStructure/Building/Museum |
LOCATION | Place/ArchitecturalStructure/Building/Prison |
LOCATION | Place/ArchitecturalStructure/Building/ReligiousBuilding |
LOCATION | Place/ArchitecturalStructure/Building/ReligiousBuilding/Church |
LOCATION | Place/ArchitecturalStructure/Building/ReligiousBuilding/Monastery |
LOCATION | Place/ArchitecturalStructure/Building/ReligiousBuilding/Mosque |
LOCATION | Place/ArchitecturalStructure/Building/ReligiousBuilding/Shrine |
LOCATION | Place/ArchitecturalStructure/Building/ReligiousBuilding/Synagogue |
LOCATION | Place/ArchitecturalStructure/Building/ReligiousBuilding/Temple |
LOCATION | Place/ArchitecturalStructure/Building/Restaurant |
LOCATION | Place/ArchitecturalStructure/Building/ShoppingMall |
LOCATION | Place/ArchitecturalStructure/Building/Skyscraper |
LOCATION | Place/ArchitecturalStructure/Building/Venue |
LOCATION | Place/ArchitecturalStructure/Building/Venue/Cinema |
LOCATION | Place/ArchitecturalStructure/Building/Venue/Stadium |
LOCATION | Place/ArchitecturalStructure/Building/Venue/Theatre |
LOCATION | Place/ArchitecturalStructure/Infrastructure |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Airport |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Dam |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Dike |
LOCATION | Place/ArchitecturalStructure/Infrastructure/LaunchPad |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Lock |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Port |
LOCATION | Place/ArchitecturalStructure/Infrastructure/PowerStation |
LOCATION | Place/ArchitecturalStructure/Infrastructure/PowerStation/NuclearPowerStation |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RestArea |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation/Bridge |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation/RailwayLine |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation/RailwayTunnel |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation/Road |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation/RoadJunction |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation/RoadTunnel |
LOCATION | Place/ArchitecturalStructure/Infrastructure/RouteOfTransportation/WaterwayTunnel |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Station |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Station/MetroStation |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Station/RailwayStation |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Station/RouteStop |
LOCATION | Place/ArchitecturalStructure/Infrastructure/Station/TramStation |
LOCATION | Place/ArchitecturalStructure/MilitaryStructure |
LOCATION | Place/ArchitecturalStructure/MilitaryStructure/Fort |
LOCATION | Place/ArchitecturalStructure/Mill |
LOCATION | Place/ArchitecturalStructure/Mill/Treadmill |
LOCATION | Place/ArchitecturalStructure/Mill/Watermill |
LOCATION | Place/ArchitecturalStructure/Mill/WindMotor |
LOCATION | Place/ArchitecturalStructure/Mill/Windmill |
LOCATION | Place/ArchitecturalStructure/Monument |
LOCATION | Place/ArchitecturalStructure/Monument/GraveMonument |
LOCATION | Place/ArchitecturalStructure/Monument/Memorial |
LOCATION | Place/ArchitecturalStructure/Pyramid |
LOCATION | Place/ArchitecturalStructure/SportFacility |
LOCATION | Place/ArchitecturalStructure/SportFacility/CricketGround |
LOCATION | Place/ArchitecturalStructure/SportFacility/GolfCourse |
LOCATION | Place/ArchitecturalStructure/SportFacility/RaceTrack |
LOCATION | Place/ArchitecturalStructure/SportFacility/RaceTrack/Racecourse |
LOCATION | Place/ArchitecturalStructure/SportFacility/SkiArea |
LOCATION | Place/ArchitecturalStructure/SportFacility/SkiArea/SkiResort |
LOCATION | Place/ArchitecturalStructure/Square |
LOCATION | Place/ArchitecturalStructure/Tower |
LOCATION | Place/ArchitecturalStructure/Tower/Lighthouse |
LOCATION | Place/ArchitecturalStructure/Tower/WaterTower |
LOCATION | Place/ArchitecturalStructure/Tunnel |
LOCATION | Place/ArchitecturalStructure/Zoo |
LOCATION | Place/CelestialBody |
LOCATION | Place/CelestialBody/Asteroid |
LOCATION | Place/CelestialBody/Constellation |
LOCATION | Place/CelestialBody/Galaxy |
LOCATION | Place/CelestialBody/Planet |
LOCATION | Place/CelestialBody/Satellite |
LOCATION | Place/CelestialBody/Satellite/ArtificialSatellite |
LOCATION | Place/CelestialBody/Star |
LOCATION | Place/CelestialBody/Star/BrownDwarf |
LOCATION | Place/CelestialBody/Swarm |
LOCATION | Place/CelestialBody/Swarm/Globularswarm |
LOCATION | Place/CelestialBody/Swarm/Openswarm |
LOCATION | Place/Cemetery |
LOCATION | Place/ConcentrationCamp |
LOCATION | Place/CountrySeat |
LOCATION | Place/Garden |
LOCATION | Place/HistoricPlace |
LOCATION | Place/Mine |
LOCATION | Place/Mine/CoalPit |
LOCATION | Place/NaturalPlace |
LOCATION | Place/NaturalPlace/Archipelago |
LOCATION | Place/NaturalPlace/Beach |
LOCATION | Place/NaturalPlace/BodyOfWater |
LOCATION | Place/NaturalPlace/BodyOfWater/Bay |
LOCATION | Place/NaturalPlace/BodyOfWater/Lake |
LOCATION | Place/NaturalPlace/BodyOfWater/Ocean |
LOCATION | Place/NaturalPlace/BodyOfWater/Sea |
LOCATION | Place/NaturalPlace/BodyOfWater/Stream |
LOCATION | Place/NaturalPlace/BodyOfWater/Stream/Canal |
LOCATION | Place/NaturalPlace/BodyOfWater/Stream/River |
LOCATION | Place/NaturalPlace/Cape |
LOCATION | Place/NaturalPlace/Cave |
LOCATION | Place/NaturalPlace/Crater |
LOCATION | Place/NaturalPlace/Crater/LunarCrater |
LOCATION | Place/NaturalPlace/Desert |
LOCATION | Place/NaturalPlace/Forest |
LOCATION | Place/NaturalPlace/Glacier |
LOCATION | Place/NaturalPlace/HotSpring |
LOCATION | Place/NaturalPlace/Mountain |
LOCATION | Place/NaturalPlace/MountainPass |
LOCATION | Place/NaturalPlace/MountainRange |
LOCATION | Place/NaturalPlace/Valley |
LOCATION | Place/NaturalPlace/Volcano |
LOCATION | Place/Park |
LOCATION | Place/PopulatedPlace |
LOCATION | Place/PopulatedPlace/Agglomeration |
LOCATION | Place/PopulatedPlace/Community |
LOCATION | Place/PopulatedPlace/Continent |
LOCATION | Place/PopulatedPlace/Country |
LOCATION | Place/PopulatedPlace/Country/HistoricalCountry |
LOCATION | Place/PopulatedPlace/GatedCommunity |
LOCATION | Place/PopulatedPlace/Intercommunality |
LOCATION | Place/PopulatedPlace/Island |
LOCATION | Place/PopulatedPlace/Island/Atoll |
LOCATION | Place/PopulatedPlace/Locality |
LOCATION | Place/PopulatedPlace/Region |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/ClericalAdministrativeRegion |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/ClericalAdministrativeRegion/Deanery |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/ClericalAdministrativeRegion/Diocese |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/ClericalAdministrativeRegion/Parish |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Arrondissement |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Canton |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Department |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Department/OverseasDepartment |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/District |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/District/HistoricalDistrict |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/DistrictWaterBoard |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/MicroRegion |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Municipality |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Municipality/FormerMunicipality |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Prefecture |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Province |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Province/HistoricalProvince |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/Regency |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/GovernmentalAdministrativeRegion/SubMunicipality |
LOCATION | Place/PopulatedPlace/Region/AdministrativeRegion/HistoricalAreaOfAuthority |
LOCATION | Place/PopulatedPlace/Region/HistoricalRegion |
LOCATION | Place/PopulatedPlace/Region/NaturalRegion |
LOCATION | Place/PopulatedPlace/Settlement |
LOCATION | Place/PopulatedPlace/Settlement/City |
LOCATION | Place/PopulatedPlace/Settlement/City/Capital |
LOCATION | Place/PopulatedPlace/Settlement/City/CapitalOfRegion |
LOCATION | Place/PopulatedPlace/Settlement/CityDistrict |
LOCATION | Place/PopulatedPlace/Settlement/HistoricalSettlement |
LOCATION | Place/PopulatedPlace/Settlement/Town |
LOCATION | Place/PopulatedPlace/Settlement/Village |
LOCATION | Place/PopulatedPlace/State |
LOCATION | Place/PopulatedPlace/Street |
LOCATION | Place/PopulatedPlace/Territory |
LOCATION | Place/PopulatedPlace/Territory/OldTerritory |
LOCATION | Place/ProtectedArea |
LOCATION | Place/SiteOfSpecialScientificInterest |
LOCATION | Place/WineRegion |
LOCATION | Place/WorldHeritageSite |
MEASURE | Altitude |
MEASURE | Area |
MEASURE | Depth |
MEASURE | GrossDomesticProduct |
MEASURE | GrossDomesticProductPerCapita |
MEASURE | Population |
MEASURE | SportCompetitionResult |
MEASURE | SportCompetitionResult/OlympicResult |
MISC | Thing |
MISC | Agent |
MISC | Agent/Employer |
MISC | Agent/Organisation/TermOfOffice |
MISC | Award |
MISC | Award/Decoration |
MISC | Award/NobelPrize |
MISC | Blazon |
MISC | ChartsPlacements |
MISC | Colour |
MISC | Demographics |
MISC | ElectionDiagram |
MISC | EthnicGroup |
MISC | Flag |
MISC | GeneLocation |
MISC | GeneLocation/HumanGeneLocation |
MISC | GeneLocation/MouseGeneLocation |
MISC | List |
MISC | List/TrackList |
MISC | Media |
MISC | MedicalSpecialty |
MISC | Medicine |
MISC | Name |
MISC | Name/GivenName |
MISC | Name/Surname |
MISC | PublicService |
MISC | Relationship |
MISC | SportCompetitionResult/SnookerWorldRanking |
MISC | TopicalConcept |
MISC | TopicalConcept/AcademicSubject |
MISC | TopicalConcept/CardinalDirection |
MISC | TopicalConcept/Fashion |
MISC | TopicalConcept/Genre |
MISC | TopicalConcept/Genre/ArtisticGenre |
MISC | TopicalConcept/Genre/LiteraryGenre |
MISC | TopicalConcept/Genre/MovieGenre |
MISC | TopicalConcept/Genre/MusicGenre |
MISC | TopicalConcept/Ideology |
MISC | TopicalConcept/MathematicalConcept |
MISC | TopicalConcept/PhilosophicalConcept |
MISC | TopicalConcept/PoliticalConcept |
MISC | TopicalConcept/ScientificConcept |
MISC | TopicalConcept/Standard |
MISC | TopicalConcept/SystemOfLaw |
MISC | TopicalConcept/Tax |
MISC | TopicalConcept/Taxon |
MISC | TopicalConcept/TheologicalConcept |
MISC | TopicalConcept/TheologicalConcept/ChristianDoctrine |
MISC | TopicalConcept/Type |
MISC | TopicalConcept/Type/DocumentType |
MISC | TopicalConcept/Type/GovernmentType |
MISC | UnitOfWork |
MISC | Unknown |
MISC | Unknown/WikimediaTemplate |
MISC | Work |
MISC | Work/Document |
MISC | Work/Document/File |
MISC | Work/Document/Image |
MISC | Work/Document/Image/MovingImage |
MISC | Work/Document/Image/StillImage |
MISC | Work/Document/Sound |
MISC | Work/MusicalWork/NationalAnthem |
MISC | Work/MusicalWork/Song/EurovisionSongContestEntry |
MISC | Work/WrittenWork |
MISC | Work/WrittenWork/Annotation |
MISC | Work/WrittenWork/Annotation/Reference |
MISC | Work/WrittenWork/Law |
MISC | Work/WrittenWork/Letter |
MISC | Work/WrittenWork/Quote |
MISC | Work/WrittenWork/Resume |
MISC | Work/WrittenWork/StatedResolution |
MISC | Work/WrittenWork/Treaty |
MISC | Work/Document |
MISC | Image |
MISC | SpatialThing |
MISC | _Feature |
MISC | Property |
MISC | Concept |
MISC | OrderedCollection |
MONEY | Currency |
ORGANIZATION | Agent/Family |
ORGANIZATION | Agent/Family/NobleFamily |
ORGANIZATION | Agent/Organisation |
ORGANIZATION | Agent/Organisation/Broadcaster |
ORGANIZATION | Agent/Organisation/Broadcaster/BroadcastNetwork |
ORGANIZATION | Agent/Organisation/Broadcaster/RadioStation |
ORGANIZATION | Agent/Organisation/Broadcaster/TelevisionStation |
ORGANIZATION | Agent/Organisation/Company |
ORGANIZATION | Agent/Organisation/Company/Bank |
ORGANIZATION | Agent/Organisation/Company/Brewery |
ORGANIZATION | Agent/Organisation/Company/Caterer |
ORGANIZATION | Agent/Organisation/Company/LawFirm |
ORGANIZATION | Agent/Organisation/Company/PublicTransitSystem |
ORGANIZATION | Agent/Organisation/Company/PublicTransitSystem/Airline |
ORGANIZATION | Agent/Organisation/Company/PublicTransitSystem/BusCompany |
ORGANIZATION | Agent/Organisation/Company/Publisher |
ORGANIZATION | Agent/Organisation/Company/RecordLabel |
ORGANIZATION | Agent/Organisation/Company/Winery |
ORGANIZATION | Agent/Organisation/EducationalInstitution |
ORGANIZATION | Agent/Organisation/EducationalInstitution/College |
ORGANIZATION | Agent/Organisation/EducationalInstitution/Library |
ORGANIZATION | Agent/Organisation/EducationalInstitution/School |
ORGANIZATION | Agent/Organisation/EducationalInstitution/University |
ORGANIZATION | Agent/Organisation/EmployersOrganisation |
ORGANIZATION | Agent/Organisation/GeopoliticalOrganisation |
ORGANIZATION | Agent/Organisation/GovernmentAgency |
ORGANIZATION | Agent/Organisation/GovernmentAgency/GovernmentCabinet |
ORGANIZATION | Agent/Organisation/Group |
ORGANIZATION | Agent/Organisation/Group/Band |
ORGANIZATION | Agent/Organisation/Group/ComedyGroup |
ORGANIZATION | Agent/Organisation/InternationalOrganisation |
ORGANIZATION | Agent/Organisation/Legislature |
ORGANIZATION | Agent/Organisation/MilitaryUnit |
ORGANIZATION | Agent/Organisation/Non-ProfitOrganisation |
ORGANIZATION | Agent/Organisation/Non-ProfitOrganisation/RecordOffice |
ORGANIZATION | Agent/Organisation/Parliament |
ORGANIZATION | Agent/Organisation/PoliticalParty |
ORGANIZATION | Agent/Organisation/ReligiousOrganisation |
ORGANIZATION | Agent/Organisation/ReligiousOrganisation/ClericalOrder |
ORGANIZATION | Agent/Organisation/SambaSchool |
ORGANIZATION | Agent/Organisation/SportsClub |
ORGANIZATION | Agent/Organisation/SportsClub/HockeyClub |
ORGANIZATION | Agent/Organisation/SportsClub/RugbyClub |
ORGANIZATION | Agent/Organisation/SportsClub/SoccerClub |
ORGANIZATION | Agent/Organisation/SportsClub/SoccerClub/NationalSoccerClub |
ORGANIZATION | Agent/Organisation/SportsLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/AmericanFootballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/AustralianFootballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/AutoRacingLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/BaseballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/BasketballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/BowlingLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/BoxingLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/CanadianFootballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/CricketLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/CurlingLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/CyclingLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/FieldHockeyLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/FormulaOneRacing |
ORGANIZATION | Agent/Organisation/SportsLeague/GolfLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/HandballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/IceHockeyLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/InlineHockeyLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/LacrosseLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/MixedMartialArtsLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/MotorcycleRacingLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/PaintballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/PoloLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/RadioControlledRacingLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/RugbyLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/SoccerLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/SoftballLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/SpeedwayLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/TennisLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/VideogamesLeague |
ORGANIZATION | Agent/Organisation/SportsLeague/VolleyballLeague |
ORGANIZATION | Agent/Organisation/SportsTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/AmericanFootballTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/AustralianFootballTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/BaseballTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/BasketballTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/CanadianFootballTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/CricketTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/CyclingTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/FormulaOneTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/HandballTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/HockeyTeam |
ORGANIZATION | Agent/Organisation/SportsTeam/SpeedwayTeam |
ORGANIZATION | Agent/Organisation/TradeUnion |
PERSON | Agent/Deity |
PERSON | Agent/FictionalCharacter |
PERSON | Agent/FictionalCharacter/ComicsCharacter |
PERSON | Agent/FictionalCharacter/ComicsCharacter/AnimangaCharacter |
PERSON | Agent/FictionalCharacter/DisneyCharacter |
PERSON | Agent/FictionalCharacter/MythologicalFigure |
PERSON | Agent/FictionalCharacter/NarutoCharacter |
PERSON | Agent/FictionalCharacter/SoapCharacter |
PERSON | Agent/Person |
PERSON | Agent/Person/Archeologist |
PERSON | Agent/Person/Architect |
PERSON | Agent/Person/Aristocrat |
PERSON | Agent/Person/Artist |
PERSON | Agent/Person/Artist/Actor |
PERSON | Agent/Person/Artist/Actor/AdultActor |
PERSON | Agent/Person/Artist/Actor/VoiceActor |
PERSON | Agent/Person/Artist/Comedian |
PERSON | Agent/Person/Artist/ComicsCreator |
PERSON | Agent/Person/Artist/Dancer |
PERSON | Agent/Person/Artist/FashionDesigner |
PERSON | Agent/Person/Artist/Humorist |
PERSON | Agent/Person/Artist/MusicalArtist |
PERSON | Agent/Person/Artist/MusicalArtist/BackScene |
PERSON | Agent/Person/Artist/MusicalArtist/ClassicalMusicArtist |
PERSON | Agent/Person/Artist/MusicalArtist/Instrumentalist |
PERSON | Agent/Person/Artist/MusicalArtist/Instrumentalist/Guitarist |
PERSON | Agent/Person/Artist/MusicalArtist/MusicDirector |
PERSON | Agent/Person/Artist/MusicalArtist/Singer |
PERSON | Agent/Person/Artist/Painter |
PERSON | Agent/Person/Artist/Photographer |
PERSON | Agent/Person/Artist/Sculptor |
PERSON | Agent/Person/Astronaut |
PERSON | Agent/Person/Athlete |
PERSON | Agent/Person/Athlete/ArcherPlayer |
PERSON | Agent/Person/Athlete/AthleticsPlayer |
PERSON | Agent/Person/Athlete/AustralianRulesFootballPlayer |
PERSON | Agent/Person/Athlete/BadmintonPlayer |
PERSON | Agent/Person/Athlete/BaseballPlayer |
PERSON | Agent/Person/Athlete/BasketballPlayer |
PERSON | Agent/Person/Athlete/Bodybuilder |
PERSON | Agent/Person/Athlete/Boxer |
PERSON | Agent/Person/Athlete/Boxer/AmateurBoxer |
PERSON | Agent/Person/Athlete/BullFighter |
PERSON | Agent/Person/Athlete/Canoeist |
PERSON | Agent/Person/Athlete/ChessPlayer |
PERSON | Agent/Person/Athlete/Cricketer |
PERSON | Agent/Person/Athlete/Cyclist |
PERSON | Agent/Person/Athlete/DartsPlayer |
PERSON | Agent/Person/Athlete/Fencer |
PERSON | Agent/Person/Athlete/GaelicGamesPlayer |
PERSON | Agent/Person/Athlete/GolfPlayer |
PERSON | Agent/Person/Athlete/GridironFootballPlayer |
PERSON | Agent/Person/Athlete/GridironFootballPlayer/AmericanFootballPlayer |
PERSON | Agent/Person/Athlete/GridironFootballPlayer/CanadianFootballPlayer |
PERSON | Agent/Person/Athlete/Gymnast |
PERSON | Agent/Person/Athlete/HandballPlayer |
PERSON | Agent/Person/Athlete/HighDiver |
PERSON | Agent/Person/Athlete/HorseRider |
PERSON | Agent/Person/Athlete/Jockey |
PERSON | Agent/Person/Athlete/LacrossePlayer |
PERSON | Agent/Person/Athlete/MartialArtist |
PERSON | Agent/Person/Athlete/MotorsportRacer |
PERSON | Agent/Person/Athlete/MotorsportRacer/MotorcycleRider |
PERSON | Agent/Person/Athlete/MotorsportRacer/MotorcycleRider/MotocycleRacer |
PERSON | Agent/Person/Athlete/MotorsportRacer/MotorcycleRider/SpeedwayRider |
PERSON | Agent/Person/Athlete/MotorsportRacer/RacingDriver |
PERSON | Agent/Person/Athlete/MotorsportRacer/RacingDriver/DTMRacer |
PERSON | Agent/Person/Athlete/MotorsportRacer/RacingDriver/FormulaOneRacer |
PERSON | Agent/Person/Athlete/MotorsportRacer/RacingDriver/NascarDriver |
PERSON | Agent/Person/Athlete/MotorsportRacer/RacingDriver/RallyDriver |
PERSON | Agent/Person/Athlete/NationalCollegiateAthleticAssociationAthlete |
PERSON | Agent/Person/Athlete/NetballPlayer |
PERSON | Agent/Person/Athlete/PokerPlayer |
PERSON | Agent/Person/Athlete/Rower |
PERSON | Agent/Person/Athlete/RugbyPlayer |
PERSON | Agent/Person/Athlete/SnookerPlayer |
PERSON | Agent/Person/Athlete/SnookerPlayer/SnookerChamp |
PERSON | Agent/Person/Athlete/SoccerPlayer |
PERSON | Agent/Person/Athlete/SquashPlayer |
PERSON | Agent/Person/Athlete/Surfer |
PERSON | Agent/Person/Athlete/Swimmer |
PERSON | Agent/Person/Athlete/TableTennisPlayer |
PERSON | Agent/Person/Athlete/TeamMember |
PERSON | Agent/Person/Athlete/TennisPlayer |
PERSON | Agent/Person/Athlete/VolleyballPlayer |
PERSON | Agent/Person/Athlete/VolleyballPlayer/BeachVolleyballPlayer |
PERSON | Agent/Person/Athlete/WaterPoloPlayer |
PERSON | Agent/Person/Athlete/WinterSportPlayer |
PERSON | Agent/Person/Athlete/WinterSportPlayer/Biathlete |
PERSON | Agent/Person/Athlete/WinterSportPlayer/BobsleighAthlete |
PERSON | Agent/Person/Athlete/WinterSportPlayer/CrossCountrySkier |
PERSON | Agent/Person/Athlete/WinterSportPlayer/Curler |
PERSON | Agent/Person/Athlete/WinterSportPlayer/FigureSkater |
PERSON | Agent/Person/Athlete/WinterSportPlayer/IceHockeyPlayer |
PERSON | Agent/Person/Athlete/WinterSportPlayer/NordicCombined |
PERSON | Agent/Person/Athlete/WinterSportPlayer/Skater |
PERSON | Agent/Person/Athlete/WinterSportPlayer/Ski_jumper |
PERSON | Agent/Person/Athlete/WinterSportPlayer/Skier |
PERSON | Agent/Person/Athlete/WinterSportPlayer/SpeedSkater |
PERSON | Agent/Person/Athlete/Wrestler |
PERSON | Agent/Person/Athlete/Wrestler/SumoWrestler |
PERSON | Agent/Person/BeautyQueen |
PERSON | Agent/Person/BusinessPerson |
PERSON | Agent/Person/Chef |
PERSON | Agent/Person/Cleric |
PERSON | Agent/Person/Cleric/Cardinal |
PERSON | Agent/Person/Cleric/ChristianBishop |
PERSON | Agent/Person/Cleric/ChristianBishop/Archbishop |
PERSON | Agent/Person/Cleric/ChristianPatriarch |
PERSON | Agent/Person/Cleric/Pope |
PERSON | Agent/Person/Cleric/Priest |
PERSON | Agent/Person/Cleric/Saint |
PERSON | Agent/Person/Cleric/Vicar |
PERSON | Agent/Person/Coach |
PERSON | Agent/Person/Coach/AmericanFootballCoach |
PERSON | Agent/Person/Coach/CollegeCoach |
PERSON | Agent/Person/Coach/VolleyballCoach |
PERSON | Agent/Person/Criminal |
PERSON | Agent/Person/Criminal/Murderer |
PERSON | Agent/Person/Criminal/Murderer/SerialKiller |
PERSON | Agent/Person/Economist |
PERSON | Agent/Person/Egyptologist |
PERSON | Agent/Person/Engineer |
PERSON | Agent/Person/Farmer |
PERSON | Agent/Person/HorseTrainer |
PERSON | Agent/Person/Journalist |
PERSON | Agent/Person/Judge |
PERSON | Agent/Person/Lawyer |
PERSON | Agent/Person/Linguist |
PERSON | Agent/Person/MemberResistanceMovement |
PERSON | Agent/Person/MilitaryPerson |
PERSON | Agent/Person/Model |
PERSON | Agent/Person/Monarch |
PERSON | Agent/Person/MovieDirector |
PERSON | Agent/Person/Noble |
PERSON | Agent/Person/OfficeHolder |
PERSON | Agent/Person/OrganisationMember |
PERSON | Agent/Person/OrganisationMember/SportsTeamMember |
PERSON | Agent/Person/Philosopher |
PERSON | Agent/Person/PlayboyPlaymate |
PERSON | Agent/Person/Politician |
PERSON | Agent/Person/Politician/Ambassador |
PERSON | Agent/Person/Politician/Chancellor |
PERSON | Agent/Person/Politician/Congressman |
PERSON | Agent/Person/Politician/Deputy |
PERSON | Agent/Person/Politician/Governor |
PERSON | Agent/Person/Politician/Lieutenant |
PERSON | Agent/Person/Politician/Mayor |
PERSON | Agent/Person/Politician/MemberOfParliament |
PERSON | Agent/Person/Politician/Minister |
PERSON | Agent/Person/Politician/President |
PERSON | Agent/Person/Politician/PrimeMinister |
PERSON | Agent/Person/Politician/Senator |
PERSON | Agent/Person/Politician/VicePresident |
PERSON | Agent/Person/Politician/VicePrimeMinister |
PERSON | Agent/Person/PoliticianSpouse |
PERSON | Agent/Person/Presenter |
PERSON | Agent/Person/Presenter/RadioHost |
PERSON | Agent/Person/Presenter/TelevisionHost |
PERSON | Agent/Person/Producer |
PERSON | Agent/Person/Psychologist |
PERSON | Agent/Person/Referee |
PERSON | Agent/Person/Religious |
PERSON | Agent/Person/RomanEmperor |
PERSON | Agent/Person/Royalty |
PERSON | Agent/Person/Royalty/BritishRoyalty |
PERSON | Agent/Person/Royalty/BritishRoyalty/Baronet |
PERSON | Agent/Person/Scientist |
PERSON | Agent/Person/Scientist/Biologist |
PERSON | Agent/Person/Scientist/Entomologist |
PERSON | Agent/Person/Scientist/Medician |
PERSON | Agent/Person/Scientist/Professor |
PERSON | Agent/Person/SportsManager |
PERSON | Agent/Person/SportsManager/SoccerManager |
PERSON | Agent/Person/TelevisionDirector |
PERSON | Agent/Person/TheatreDirector |
PERSON | Agent/Person/Writer |
PERSON | Agent/Person/Writer/Historian |
PERSON | Agent/Person/Writer/MusicComposer |
PERSON | Agent/Person/Writer/PlayWright |
PERSON | Agent/Person/Writer/Poet |
PERSON | Agent/Person/Writer/ScreenWriter |
PERSON | Agent/Person/Writer/SongWriter |
PERSON | PersonFunction |
PERSON | PersonFunction/PoliticalFunction |
PERSON | PersonFunction/Profession |
PERSON | Person |
PRODUCT | Activity/Game/BoardGame |
PRODUCT | Activity/Game/CardGame |
PRODUCT | Device |
PRODUCT | Device/Battery |
PRODUCT | Device/Camera |
PRODUCT | Device/Camera/DigitalCamera |
PRODUCT | Device/Engine |
PRODUCT | Device/Engine/AutomobileEngine |
PRODUCT | Device/Engine/RocketEngine |
PRODUCT | Device/InformationAppliance |
PRODUCT | Device/Instrument |
PRODUCT | Device/Instrument/Guitar |
PRODUCT | Device/Instrument/Organ |
PRODUCT | Device/MobilePhone |
PRODUCT | Device/Weapon |
PRODUCT | Work/Artwork |
PRODUCT | Work/Artwork/Painting |
PRODUCT | Work/Artwork/Sculpture |
PRODUCT | Work/Cartoon |
PRODUCT | Work/Cartoon/Anime |
PRODUCT | Work/Cartoon/HollywoodCartoon |
PRODUCT | Work/CollectionOfValuables |
PRODUCT | Work/CollectionOfValuables/Archive |
PRODUCT | Work/Database |
PRODUCT | Work/Database/BiologicalDatabase |
PRODUCT | Work/Film |
PRODUCT | Work/LineOfFashion |
PRODUCT | Work/MusicalWork |
PRODUCT | Work/MusicalWork/Album |
PRODUCT | Work/MusicalWork/ArtistDiscography |
PRODUCT | Work/MusicalWork/ClassicalMusicComposition |
PRODUCT | Work/MusicalWork/Musical |
PRODUCT | Work/MusicalWork/Opera |
PRODUCT | Work/MusicalWork/Single |
PRODUCT | Work/MusicalWork/Song |
PRODUCT | Work/RadioProgram |
PRODUCT | Work/Software |
PRODUCT | Work/Software/VideoGame |
PRODUCT | Work/TelevisionEpisode |
PRODUCT | Work/TelevisionSeason |
PRODUCT | Work/TelevisionShow |
PRODUCT | Work/Website |
PRODUCT | Work/WrittenWork/Article |
PRODUCT | Work/WrittenWork/Book |
PRODUCT | Work/WrittenWork/Book/Novel |
PRODUCT | Work/WrittenWork/Book/Novel/LightNovel |
PRODUCT | Work/WrittenWork/Comic |
PRODUCT | Work/WrittenWork/Comic/ComicStrip |
PRODUCT | Work/WrittenWork/Comic/Manga |
PRODUCT | Work/WrittenWork/Comic/Manhua |
PRODUCT | Work/WrittenWork/Comic/Manhwa |
PRODUCT | Work/WrittenWork/Drama |
PRODUCT | Work/WrittenWork/MultiVolumePublication |
PRODUCT | Work/WrittenWork/PeriodicalLiterature |
PRODUCT | Work/WrittenWork/PeriodicalLiterature/AcademicJournal |
PRODUCT | Work/WrittenWork/PeriodicalLiterature/Magazine |
PRODUCT | Work/WrittenWork/PeriodicalLiterature/Newspaper |
PRODUCT | Work/WrittenWork/PeriodicalLiterature/UndergroundJournal |
PRODUCT | Work/WrittenWork/Play |
PRODUCT | Work/WrittenWork/Poem |
SPECIES | Species |
SPECIES | Species/Archaea |
SPECIES | Species/Bacteria |
SPECIES | Species/Eukaryote |
SPECIES | Species/Eukaryote/Animal |
SPECIES | Species/Eukaryote/Animal/Amphibian |
SPECIES | Species/Eukaryote/Animal/Arachnid |
SPECIES | Species/Eukaryote/Animal/Bird |
SPECIES | Species/Eukaryote/Animal/Crustacean |
SPECIES | Species/Eukaryote/Animal/Fish |
SPECIES | Species/Eukaryote/Animal/Insect |
SPECIES | Species/Eukaryote/Animal/Mammal |
SPECIES | Species/Eukaryote/Animal/Mammal/Cat |
SPECIES | Species/Eukaryote/Animal/Mammal/Dog |
SPECIES | Species/Eukaryote/Animal/Mammal/Horse |
SPECIES | Species/Eukaryote/Animal/Mollusca |
SPECIES | Species/Eukaryote/Animal/Reptile |
SPECIES | Species/Eukaryote/Fungus |
SPECIES | Species/Eukaryote/Plant |
SPECIES | Species/Eukaryote/Plant/ClubMoss |
SPECIES | Species/Eukaryote/Plant/Conifer |
SPECIES | Species/Eukaryote/Plant/CultivatedVariety |
SPECIES | Species/Eukaryote/Plant/Cycad |
SPECIES | Species/Eukaryote/Plant/Fern |
SPECIES | Species/Eukaryote/Plant/FloweringPlant |
SPECIES | Species/Eukaryote/Plant/FloweringPlant/Grape |
SPECIES | Species/Eukaryote/Plant/Ginkgo |
SPECIES | Species/Eukaryote/Plant/Gnetophytes |
SPECIES | Species/Eukaryote/Plant/GreenAlga |
SPECIES | Species/Eukaryote/Plant/Moss |
SUBSTANCE | Biomolecule |
SUBSTANCE | Biomolecule/Enzyme |
SUBSTANCE | Biomolecule/Gene |
SUBSTANCE | Biomolecule/Gene/HumanGene |
SUBSTANCE | Biomolecule/Gene/MouseGene |
SUBSTANCE | Biomolecule/Hormone |
SUBSTANCE | Biomolecule/Lipid |
SUBSTANCE | Biomolecule/Polysaccharide |
SUBSTANCE | Biomolecule/Protein |
SUBSTANCE | ChemicalSubstance |
SUBSTANCE | ChemicalSubstance/ChemicalCompound |
SUBSTANCE | ChemicalSubstance/ChemicalElement |
SUBSTANCE | ChemicalSubstance/Drug |
SUBSTANCE | ChemicalSubstance/Drug/CombinationDrug |
SUBSTANCE | ChemicalSubstance/Drug/MonoclonalAntibody |
SUBSTANCE | ChemicalSubstance/Drug/Vaccine |
SUBSTANCE | ChemicalSubstance/Mineral |
TITLE | Diploma |
TRANSPORT | MeanOfTransportation |
TRANSPORT | MeanOfTransportation/Aircraft |
TRANSPORT | MeanOfTransportation/Aircraft/MilitaryAircraft |
TRANSPORT | MeanOfTransportation/Automobile |
TRANSPORT | MeanOfTransportation/Locomotive |
TRANSPORT | MeanOfTransportation/MilitaryVehicle |
TRANSPORT | MeanOfTransportation/Motorcycle |
TRANSPORT | MeanOfTransportation/On-SiteTransportation |
TRANSPORT | MeanOfTransportation/On-SiteTransportation/ConveyorSystem |
TRANSPORT | MeanOfTransportation/On-SiteTransportation/Escalator |
TRANSPORT | MeanOfTransportation/On-SiteTransportation/MovingWalkway |
TRANSPORT | MeanOfTransportation/Rocket |
TRANSPORT | MeanOfTransportation/Ship |
TRANSPORT | MeanOfTransportation/SpaceShuttle |
TRANSPORT | MeanOfTransportation/SpaceStation |
TRANSPORT | MeanOfTransportation/Spacecraft |
TRANSPORT | MeanOfTransportation/Train |
TRANSPORT | MeanOfTransportation/TrainCarriage |
TRANSPORT | MeanOfTransportation/Tram |
Social media extractors
As of release 7.56.0.c77.0, Entity Extractor can extract the following social media entity types, improving entity extraction from social media content. The extractor utilizes the part of speech identified for the entity by Babel Street Base Linguistics to recognize social media types.
ATMENTIONEMAILHASHTAGURLTo enable social media, set
extractSocialMediatotruein therex-factory-config.yamlfile.Parameter
Description
Default
extractSocialMediaExtracts social media entity types, instead of person, location, or organization entity types.
falseWhen enabled, these entities replace person, organization, or location entity types for atmention and hashtag.
Text
Entity type extracted
Social media enabled
Social media disabled
@microsoft
ATMENTIONORGANIZATION#boston
HASHTAGLOCATIONJoeSmith@gmail.com
EMAIL/URLIDENTIFIER:EMAIL/URLhttps://docs.babelstreet.com/Extract/en/entity-extractor.html
EMAIL/URLI
IDENTIFIER:EMAIL/URL